首先我们打开唐诗三百首网页
1 http://www.gushiwen.org/gushi/tangshi.aspx
目标分析:
1、爬取网页七大板块:五言绝句,七言绝句,五言律诗,七言律诗,五言古诗,七言古诗,乐府。 2、爬取每个板块的所有古诗。 3、爬取每个古诗词内容。
网页详情如下:
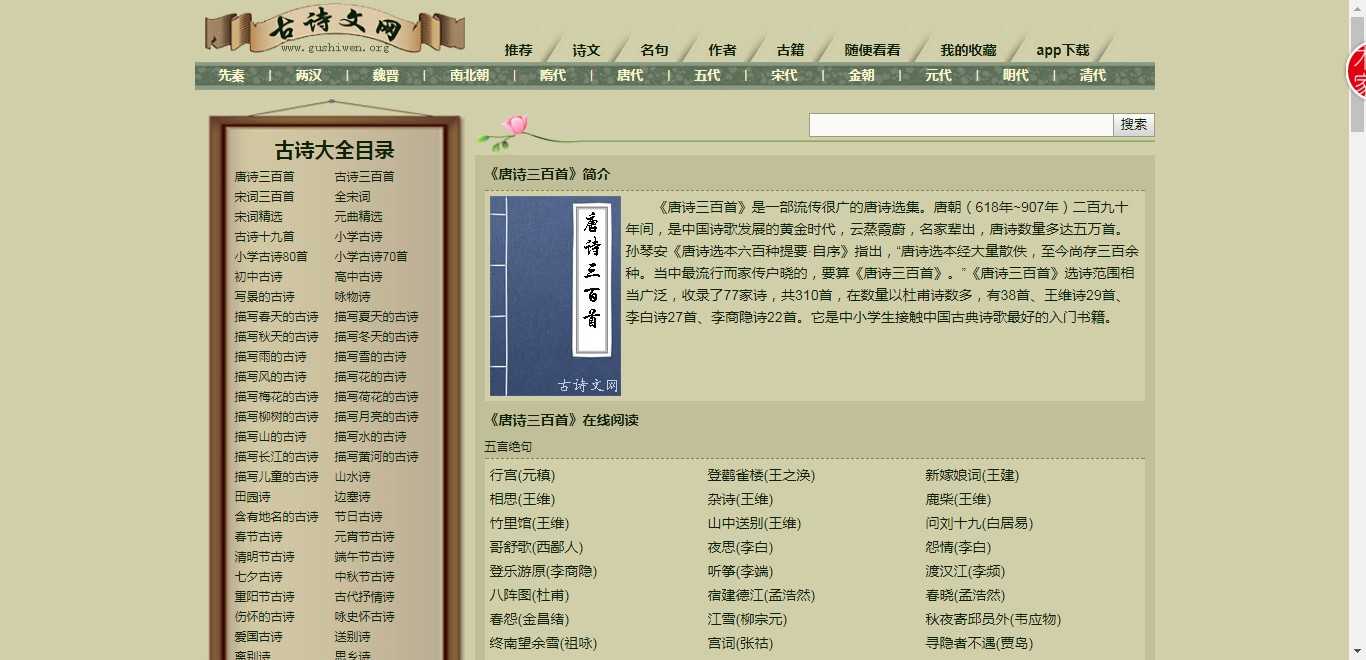
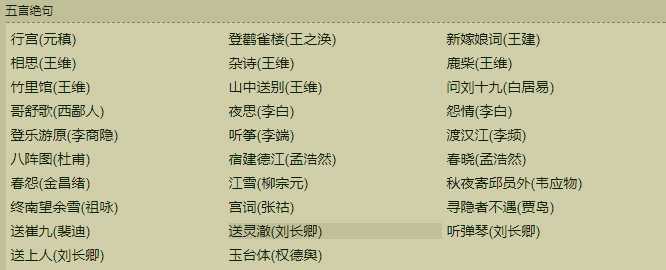

我们很容易就能发现,每一个分类都是包裹在:
1 <div id="guwencont2">
这种调理清晰的网站,大大方便了我们爬虫的编写。
下面是每个板块标题的特征
1 <div> 2 <span style="margin-left:10px;">五言绝句</span> 3 </div>
下面是每个板块的特征,很明显每首古诗的标题、链接的后半部分都存放在<a>标签里面。
<div id="guwencont2" style="height:248px;" class="guwencont2"> <a href="/GuShiWen_e57030b42c.aspx" target="_blank">行宫(元稹)</a> <a href="/GuShiWen_62214a2b00.aspx" target="_blank">登鹳雀楼(王之涣)</a> <a href="/GuShiWen_7fe57a613a.aspx" target="_blank">新嫁娘词(王建)</a> <a href="/GuShiWen_f4bcd5f606.aspx" target="_blank">相思(王维)</a> <a href="/GuShiWen_e731c3242e.aspx" target="_blank">杂诗(王维)</a> <a href="/GuShiWen_465b5b1b4a.aspx" target="_blank">鹿柴(王维)</a> <a href="/GuShiWen_2bb615bbd9.aspx" target="_blank">竹里馆(王维)</a> <a href="/GuShiWen_e788e9c73d.aspx" target="_blank">山中送别(王维)</a> <a href="/GuShiWen_8d927fac6d.aspx" target="_blank">问刘十九(白居易)</a> <a href="/GuShiWen_24e79da4f4.aspx" target="_blank">哥舒歌(西鄙人)</a> <a href="/GuShiWen_6fa12406af.aspx" target="_blank">夜思(李白)</a> <a href="/GuShiWen_1cd03cf3df.aspx" target="_blank">怨情(李白)</a> <a href="/GuShiWen_9dcf316328.aspx" target="_blank">登乐游原(李商隐)</a> <a href="/GuShiWen_bd602eaad0.aspx" target="_blank">听筝(李端)</a> <a href="/GuShiWen_bca3a963d7.aspx" target="_blank">渡汉江(李频)</a> <a href="/GuShiWen_3fafd55cca.aspx" target="_blank">八阵图(杜甫)</a> <a href="/GuShiWen_8d5a9ecdb7.aspx" target="_blank">宿建德江(孟浩然)</a> <a href="/GuShiWen_b3639b3722.aspx" target="_blank">春晓(孟浩然)</a> <a href="/GuShiWen_8aed48548f.aspx" target="_blank">春怨(金昌绪)</a> <a href="/GuShiWen_3ad899caed.aspx" target="_blank">江雪(柳宗元)</a> <a href="/GuShiWen_77049a01e9.aspx" target="_blank">秋夜寄邱员外(韦应物)</a> <a href="/GuShiWen_fe5950e8d7.aspx" target="_blank">终南望余雪(祖咏)</a> <a href="/GuShiWen_768631014b.aspx" target="_blank">宫词(张祜)</a> <a href="/GuShiWen_a2b94427a1.aspx" target="_blank">寻隐者不遇(贾岛)</a> <a href="/GuShiWen_5634353338.aspx" target="_blank">送崔九(裴迪)</a> <a href="/GuShiWen_6693ec4ec3.aspx" target="_blank">送灵澈(刘长卿)</a> <a href="/GuShiWen_6c39d14909.aspx" target="_blank">听弹琴(刘长卿)</a> <a href="/GuShiWen_536b8d6320.aspx" target="_blank">送上人(刘长卿)</a> <a href="/GuShiWen_3a544871c1.aspx" target="_blank">玉台体(权德舆)</a> </div>
这样一来,我们只需要在当前页面找到所有古诗的标题,链接,并保存在列表就行了。
下面就是获取每首古诗的内容,例如五言绝句的《行宫》的链接为
http://www.gushiwen.org/GuShiWen_e57030b42c.aspx
我们只需要将http://www.gushiwen.org与GuShiWen_e57030b42c.aspx连接起来即可。
下面我们观察古诗内容的特征
<p align="center"> “寥落古行宫,宫花寂寞红。” <br> “白头宫女在,闲坐说玄宗。” </p>
全部抓取代码如下:
1 # -*- coding: utf-8 -*- 2 import requests 3 from bs4 import BeautifulSoup 4 5 #网页抓取 6 def get_html(url): 7 try: 8 html = requests.get(url).text 9 soup = BeautifulSoup(html, ‘lxml‘) 10 return soup 11 except: 12 return "Someting Wrong!" 13 14 #将每个模块的每首古诗存到字典里面 15 def get_links(soup): 16 u = ‘http://www.gushiwen.org/‘ 17 all_html = soup.find_all(‘div‘,class_=‘son2s‘) 18 models = all_html[1].find_all(‘span‘,style=‘margin-left:10px;‘) #获取每个模块的标题,如五言绝句,七言律诗 19 #print(models) 20 links = all_html[1].find_all(‘div‘, class_=‘guwencont2‘) 21 all_models = {} 22 for index,item in enumerate(links): 23 every_model = [] 24 for i in item.find_all(‘a‘): 25 title = i.string #获取古诗标题 26 title_link = u + i[‘href‘] #获取古诗连接 27 every_model.append([title,title_link]) 28 all_models.setdefault(models[index].string,every_model) 29 return all_models 30 31 #获取每首古诗的链接,并且最终存文件里面 32 def get_shi(all_models): 33 with open(‘all_tangshi.txt‘, ‘w‘, encoding=‘utf-8‘) as f: 34 for k,v in all_models.items(): 35 f.write(str(k)+‘\t\t\t‘) 36 f.write(‘\n‘) 37 for i in v: 38 soup = get_html(i[1]) 39 txt = ‘‘ 40 if len(soup.find_all(‘p‘,align=‘center‘)) == 0: 41 txt = ‘找不到啊。。。。。。。。。。‘ 42 else: 43 for x in range(len(soup.find_all(‘p‘, align=‘center‘))): 44 45 txtx = soup.find_all(‘p‘,align=‘center‘)[x].text 46 txt = str(txt) + str(txtx) 47 f.write(str(i[0])) 48 f.write(str(txt)) 49 f.write(‘\n‘) 50 51 if __name__ == ‘__main__‘: 52 url = ‘http://www.gushiwen.org/gushi/tangshi.aspx‘ 53 h = get_html(url) 54 m = get_links(h) 55 get_shi(m)
本次爬虫写的比较顺利,主要是因为爬的网站是没有反爬虫技术,以及古诗分类清晰,结构优美。
但是,按照我们的这篇文的思路去爬取, 时间太长了!这种单线程的爬取方式效率必然很低。
其实还有更好的方式:下面我们将一起学习Scrapy框架
学到那里的时候,我再把这里代码重构一遍,
你会惊奇的发现,速度几十倍甚至几百倍的提高了!
这其实也是多线程的威力!
下面我们看一下爬取的结果

原文:http://www.cnblogs.com/freeman818/p/7143438.html