1、新建MR工程
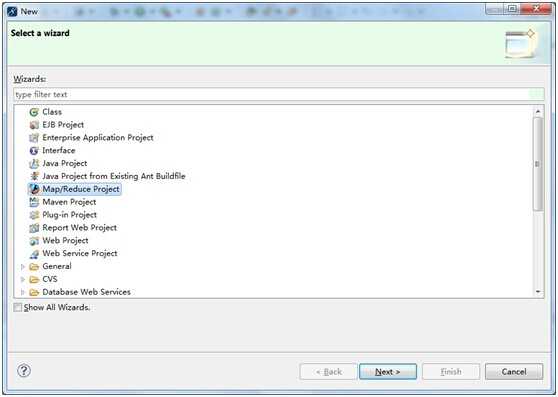
2、设置工程名字
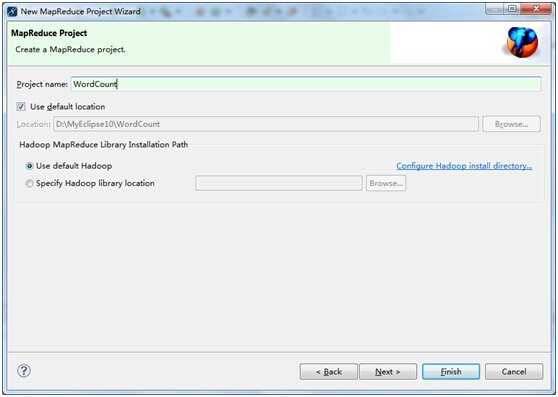
3、finish
4、使用navicate浏览,使用package太长了。
5、将hadoop例子下的WordCount复制过来,当然我自己打的,重新熟悉一下。
改改包名即可。
一个示例完成。
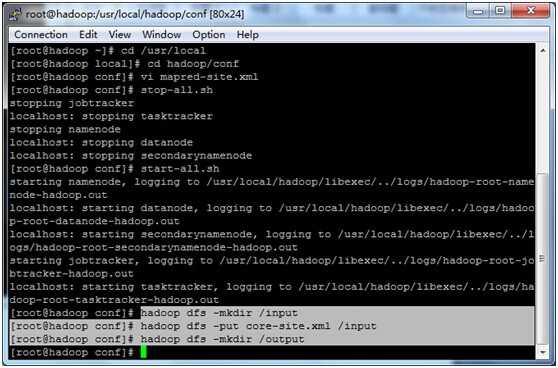
6、linux下准备数据文件
>hadoop dfs -mkdir /input (注意,如果你写成了input,则这个实际hadoop目录为/user/root/input,后面配置输入参数需要)
>hadoop dfs -put core-site.xml /input 上传一个文件进入hadoop输入目录
>hadoop dfs -mkdir /output 创建输出目录,注意一定是个空目录,否则hadoop运行报错。
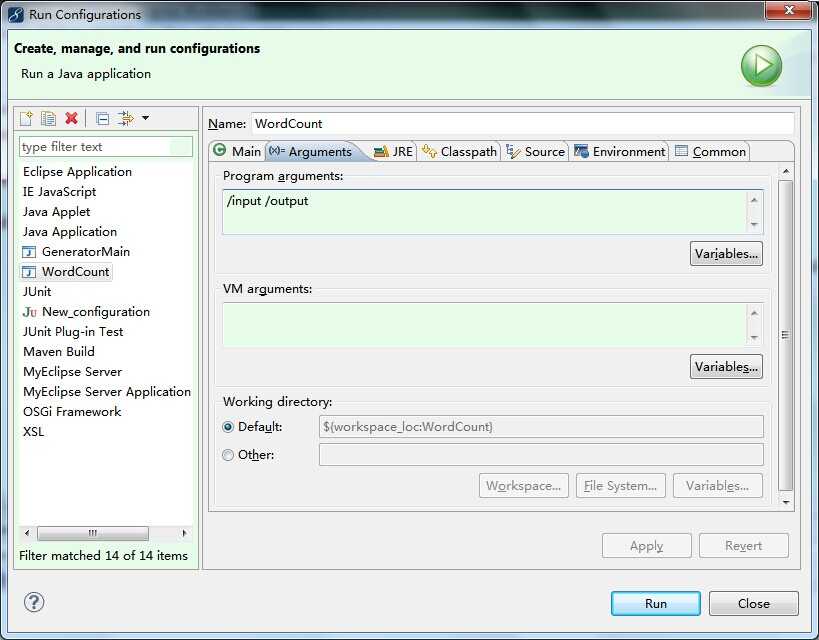
7、配置WordCount的运行参数
(如果直接创建的目录为input,而没有/则参数为/user/root/input /user/root/output)
8、运行(报错哎)
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
ERROR security.UserGroupInformation: PriviledgedActionException as:Administrator cause:java.io.IOException: Failed to set permissions of path: \usr\local\hadoop\tmp\mapred\staging\Administrator13835705\.staging to 0700
Exception in thread "main" java.io.IOException: Failed to set permissions of path: \usr\local\hadoop\tmp\mapred\staging\Administrator13835705\.staging to 0700
at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:689)
恩,注意第四句话,是在FileUtil.java的第689行报错的。关于权限设置的。
如果我们将它注释掉,就不会影响了。
注意:在linux下开发的话,不会有这个问题。
解决方案:下载,我的文件下面有一个FileUtil.rar,解压这个文件,将里面的org文件夹复制到自己工程的src下。
9、重新运行Run As on hadoop
10、对话框Select Hadoop location
选择我们配置的hadoop这个。
finish
11、成功运行,输出
14/06/15 10:07:13 INFO mapred.LocalJobRunner: reduce > reduce
14/06/15 10:07:13 INFO mapred.Task: Task ‘attempt_local_0001_r_000000_0‘ done.
14/06/15 10:07:13 INFO mapred.JobClient: map 100% reduce 100%
14/06/15 10:07:13 INFO mapred.JobClient: Job complete: job_local_0001
14/06/15 10:07:13 INFO mapred.JobClient: Counters: 19
14/06/15 10:07:13 INFO mapred.JobClient: File Output Format Counters
14/06/15 10:07:13 INFO mapred.JobClient: Bytes Written=370
14/06/15 10:07:13 INFO mapred.JobClient: FileSystemCounters
14/06/15 10:07:13 INFO mapred.JobClient: FILE_BYTES_READ=44614
14/06/15 10:07:13 INFO mapred.JobClient: HDFS_BYTES_READ=848
14/06/15 10:07:13 INFO mapred.JobClient: FILE_BYTES_WRITTEN=177320
14/06/15 10:07:13 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=370
14/06/15 10:07:13 INFO mapred.JobClient: File Input Format Counters
14/06/15 10:07:13 INFO mapred.JobClient: Bytes Read=424
14/06/15 10:07:13 INFO mapred.JobClient: Map-Reduce Framework
14/06/15 10:07:13 INFO mapred.JobClient: Map output materialized bytes=464
14/06/15 10:07:13 INFO mapred.JobClient: Map input records=15
14/06/15 10:07:13 INFO mapred.JobClient: Reduce shuffle bytes=0
14/06/15 10:07:13 INFO mapred.JobClient: Spilled Records=44
14/06/15 10:07:13 INFO mapred.JobClient: Map output bytes=445
14/06/15 10:07:13 INFO mapred.JobClient: Total committed heap usage (bytes)=328073216
14/06/15 10:07:13 INFO mapred.JobClient: SPLIT_RAW_BYTES=103
14/06/15 10:07:13 INFO mapred.JobClient: Combine input records=24
14/06/15 10:07:13 INFO mapred.JobClient: Reduce input records=22
14/06/15 10:07:13 INFO mapred.JobClient: Reduce input groups=22
14/06/15 10:07:13 INFO mapred.JobClient: Combine output records=22
14/06/15 10:07:13 INFO mapred.JobClient: Reduce output records=22
14/06/15 10:07:13 INFO mapred.JobClient: Map output records=24
12、命令查看输出
$ hadoop dfs -cat /output/* (只会列出文件,隐藏的不显示)
13、重新执行WordCount
ERROR security.UserGroupInformation: PriviledgedActionException as:Administrator cause:org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory /output already exists
执行之前删除输出目录内容即可。
14、OK,第一次hadoop之旅成功开始。
hadoop的第一次WordCount,布布扣,bubuko.com
原文:http://www.cnblogs.com/jsunday/p/3789155.html