现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定变量的时候经常在特定的内存地址访问,这就需要各类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
为什么要了解内存对齐:各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出,而如果存放在奇地址开始的地方,就可能会需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该int数据。显然在读取效率上下降很多。这也是空间和时间的博弈。
通常我们不需要去主动进行内存对齐的操作,编译器会自动为我们选择最优的对齐规则方式,合理利用空间节省程序运行的时间,但若是我们能了解这种规则,对于我们编写程序还是会有很大的帮助的。


1 #pragma pack(1)//让编译器对此结构体作字节对齐
2 struct A
3 {
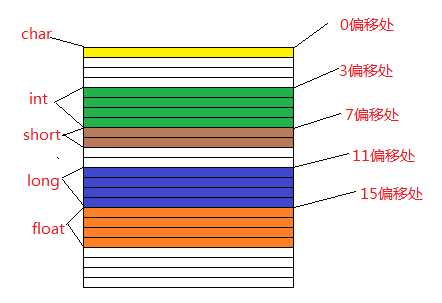
4 char a;// 1
5 int b;// 4
6 short c;// 2
7 long d;// 4
8 float e;// 4
9 };
10 #pragma pack()//取消字节对齐,回复默认字节对齐
11 int main()
12 {
13 struct A a;
14 printf("%d\n",sizeof(a));
15 return 0;
16 }

1 #include <stdio.h>
2 //#pragma pack(1)//让编译器对此结构体作字节对齐
3 struct A
4 {
5 char a;// 1
6 int b;// 4
7 short c;// 2
8 long d;// 4
9 float e;// 4
10 };
11 //#pragma pack()//取消字节对齐,回复默认字节对齐
12 int main()
13 {
14 struct A a;
15 printf("%d\n",sizeof(a));
16 return 0;
17 }
程序运行:

1 #include <stdio.h>
2 //#pragma pack(1)//让编译器对此结构体作字节对齐
3 struct A
4 {
5 char a;// 1
6 int b;// 4
7 short c;// 2
8 //long d;// 4
9 //float e;// 4
10 };
11 //#pragma pack()//取消字节对齐,回复默认字节对齐
12 int main()
13 {
14 struct A a;
15 printf("%d\n",sizeof(a));
16 return 0;
17 }
程序运行:

1 #include <stdio.h>
2 //#pragma pack(1)//让编译器对此结构体作字节对齐
3 struct A
4 {
5 char a;// 1
6 //int b;// 4
7 short c;// 2
8 long d;// 4
9 char g;// 1
10 //float e;// 4
11 };
12 //#pragma pack()//取消字节对齐,回复默认字节对齐
13 int main()
14 {
15 struct A a;
16 printf("%d\n",sizeof(a));
17 return 0;
18 }
程序运行:

1 #include <stdio.h>
2
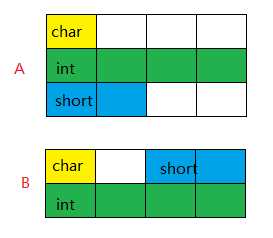
3 struct A
4 {
5 char a;
6 int b;
7 short c;
8 };
9 struct B
10 {
11 char a;
12 short b;
13 int c;
14 };
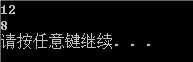
15 int main()
16 {
17 struct A a;
18 struct B b;
19 printf("%d\n",sizeof(a));
20 printf("%d\n",sizeof(b));
21 return 0;
22 }
程序运行:
原文:http://www.cnblogs.com/Leo_wl/p/7198485.html