1.安装
cmd------->>pip install beautifulsoup4
2.安装测试。
import requests # 导入requests库 from bs4 import BeautifulSoup # 导入美味汤库 r = requests.get("http://python123.io/ws/demo.html") print(r.status_code) # 测试是否连接正常 # print(r.text) # 全部文本信息 demo = r.text # 赋值,方便后期处理 soup = BeautifulSoup(demo,"html.parser") # 开始煲汤 demo 为解析对象。 html.parser 为解析方式 print(soup.prettify()) # 友好显示结果
煲汤过程可以总结为:
from bs4 import BeautifulSoup # B and S 大写 soup = BeautifulSoup ("<p>date</p>","html.parser") # <p>date</p> 解析对象 "html.parser" 解析器
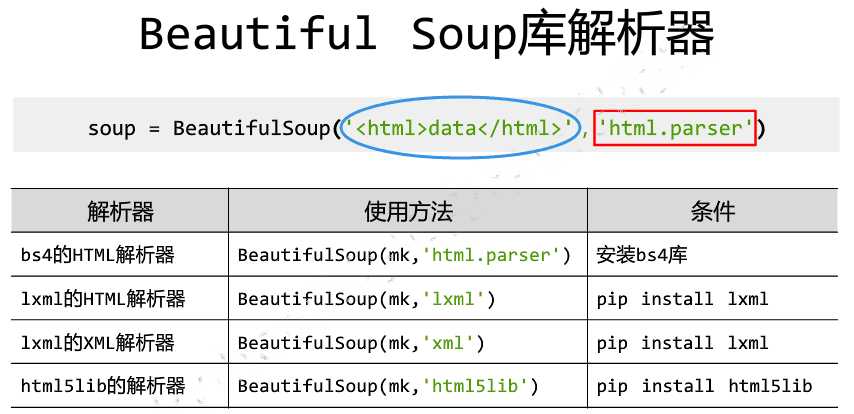
3. BeautifulSoup 的基本元素。

import requests # r = requests.get("http://python123.io/ws/demo.html") demo = r.text from bs4 import BeautifulSoup soup = BeautifulSoup(demo,"html.parser") # tag print(soup.a) print(soup.p) print(soup.a.prettify()) # 标签内容的友好显示 print(soup.p.prettify()) # 标签内容的友好显示 # name print(soup.a.name) print(soup.p.name) # string print(soup.a.string) print(soup.p.string) # 属性 print(soup.a.attrs) print(soup.p.attrs)
3.1 Tag标签
import requests from bs4 import BeautifulSoup r = requests.get("http://python123.io/ws/demo.html") demo = r.text soup = BeautifulSoup(demo,"html.parser") tag = soup.a print(tag) #a tag # <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
# 标签。最基本的信息组织单元,别用 <> 和 </> 表明开头和结尾。
3.2 标签的名字

3.3 标签的属性 (不懂有什么用)

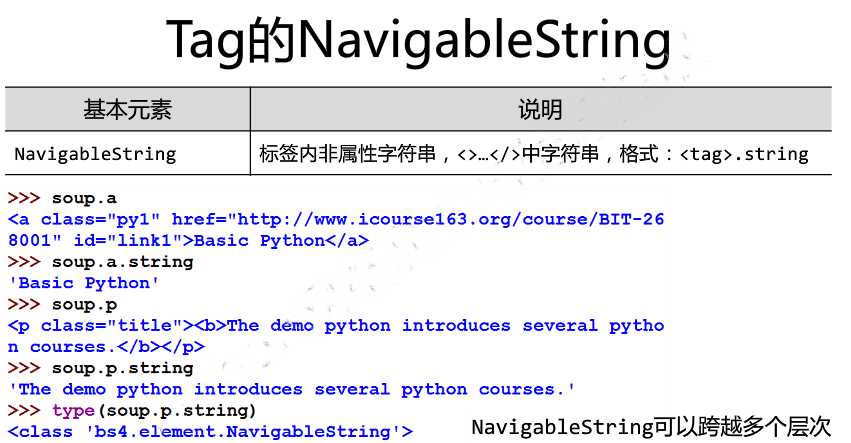
3.4 标签的字符串
print(soup.a.string) # Basic Python print(soup.p.string) # The demo python introduces several python courses. print(type(soup.p.string)) # <class ‘bs4.element.NavigableString‘>
3.5 注释。
demo,"html.parser"
原文:http://www.cnblogs.com/hanbb/p/7223276.html
