第三百二十四节,web爬虫,scrapy模块介绍与使用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
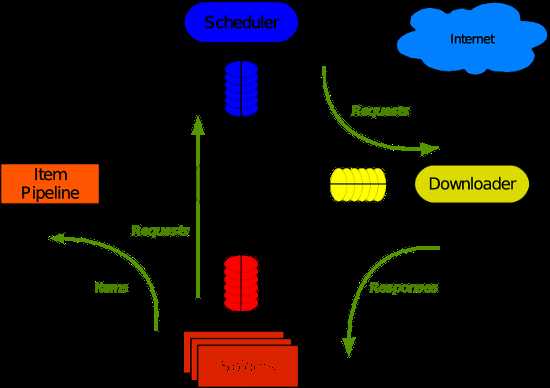
Scrapy主要包括了以下组件:
Scrapy运行流程大概如下:
创建Scrapy框架项目
Scrapy框架项目是有python安装目录里的Scripts文件夹里scrapy.exe文件创建的,所以python安装目录下的Scripts文件夹要配置到系统环境变量里,才能运行命令生成项目
创建项目
首先运行cmd终端,然后cd 进入要创建项目的目录,如:cd H:\py\14
进入要创建项目的目录后执行命令 scrapy startproject 项目名称
scrapy startproject pach1
项目创建成功
原文:http://www.cnblogs.com/adc8868/p/7226158.html