环境:
hadoop2.6.0
jdk1.8
ubuntu 14.04 64位
1 安装scala环境
版本是scala-2.10.6,官网下载地址http://www.scala-lang.org/download/
ps:这里最好用jdk1.8配合这个scala版本,不然可能会报错,不过我看有些大神的jdk1.7也没有报错,不过建议jdk1.8
然后配置scala的环境变量:sudo vim /etc/profile
export SCALA_HOME=/usr/scala/scala-2.10.6 export PATH=$PATH:$SCALA_HOME/bin
执行命令source /etc/profile 让环境变量生效
scala检测:在任意目录执行scala -version,结果如下:

2 spark配置
首先下载spark的压缩包,官网下载地址http://spark.apache.org/downloads.html
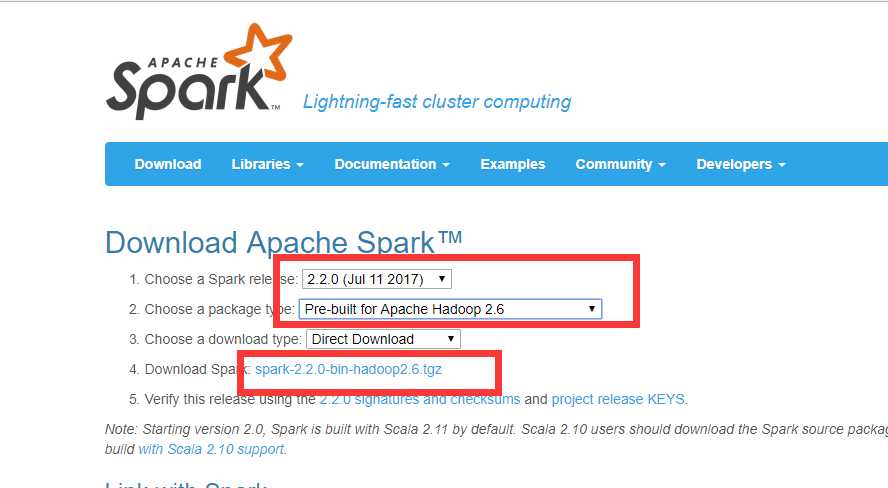
按照上图所示选取,然后下载spark-2.2.0-bin-hadoop2.6.tgz压缩包
解压到安装目录下,比如我是解压到/usr/local目录下,并且重命名为spark
进入spark/conf目录,把 spark-env.sh.template文件复制并且重命名为 spark-env.sh,并且在文件末尾加上如下配置
export JAVA_HOME=/usr/java/jdk1.8.0_141 export SCALA_HOME=/usr/scala/scala-2.10.6 export SPARK_MASTER_IP=master export SPARK_WORKER_CORES=2 export SPARK_WORKER_MEMORY=1g export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
其中export SPARK_MASTER_IP是指master的ip,由于我是伪分布式搭建,ip就是本机,而我在hosts中配置过本机ip为master
然后把 slaves.template文件复制重命名为slaves,文件的默认内容是localhost,把localhost删除,并添加内容master
(如果是完全分布式,就要把每个salve中的spark-env.sh文件中的SPARK_MASTER_IP参数改成master的ip,把master和每个slave上的slaves文件内容写成每一行一个slave的ip地址)
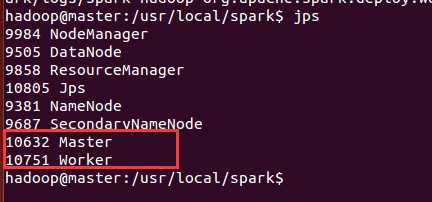
以上就完成了,然后进行再打开hadoop的dfs和yarn的服务后,再spark的目录下,执行sbin/start-all.sh,就启动spark进程了,然后执行jps查看,如下图,多了Master和Worker两个进程,就说明ok了。
原文:http://www.cnblogs.com/K-artorias/p/7226451.html