1.基于内容的推荐
对于基于内容的推荐不多赘述,只说下基本的概念,根据用户已经评分且喜欢(评分高)的电影,为用户推荐和他过去喜欢的电影相似的电影,这里的相似就要依据电影的"内容"来计算了,例如电影的类型等等。
利用到评分预测上,就是对于目标用户A和电影M,从A已经评价过的电影中找到与M相似的电影,利用这些电影的评分来预测用户A对M的评分。
2.协同过滤
协同过滤算法主要分为基于用户的协同过滤算法和基于项目的协同过滤算法。
基于用户的协同过滤通俗的来说呢,就是对于待预测的目标用户A及电影M,找到与A相似的且评价过M的用户,利用这些用户对M的评分来预测用户A对M的评分。
基于项目的协同过滤呢,可以看作是基于用户的协同过滤的对偶(暂且这么说吧)。对于待预测的目标用户A及电影M,基于项目的协同过滤就是在A已评价过的电影中找到与M相似的那些电影,利用这些电影的评分来预测用户A对电影M的评分。看到这儿,你似乎很难理解基于内容的推荐和Item-Based CF的区别,事实上,它们的区别也确实很小,最关键性的区别就是:相似性的计算时,基于内容的推荐没有利用到用户信息,而Item-Based CF利用了用户信息,Item-Based CF计算两个电影M1和M2的相似性的时候,是依据用户对M1和M2的打分来计算的,例如用户A1、A2、A3对M1评分为3,3,3,用户A1、A2、A3对M2评分为3,4,3,那么M1和M2之间的相似度就是利用(3,3,3)和(3,4,3)来计算的(可用欧氏距离、余弦相似、皮尔森相似)。
3.User-Based算法实现
整个程序是小组多个人一起做的,我做的是User-Based这部分,代码是C++写的,训练数据有200多M,所以一般的PC就别浪费时间跑完整数据了,我们是放在服务器上跑的,程序也容易修改,代码比较长。下面说说我的程序得思想。
算法思想:
假设需要预测用户A对电影M的评分,首先对于电影M,根据训练数据集找出已经对电影M评过分的用户,然后计算A和这些用户之间的相似度,依据相似度和这些用户对M的评分,来预测用户A对电影M的评分。
根据训练数据集找出已经对电影M评过分的用户很容易,预测结果的好坏关键在于如何计算用户A和这些用户之间的相似度,以及采用何种方式来利用相似度和评分预测出用户A对电影M的评分。
1)相似度计算
已知电影1、2、3、4、5的风格如表格 1:
|
Action |
Adventure |
Comedy |
Crime |
Drama |
Fantasy |
Romance |
Thriller |
War |
|
|
1 |
√ |
√ |
√ |
√ |
√ |
||||
|
2 |
√ |
√ |
√ |
√ |
|||||
|
3 |
√ |
√ |
|||||||
|
4 |
√ |
√ |
√ |
||||||
|
5 |
√ |
√ |
√ |
表格 1 电影风格
假设用户A评价过的电影有1、3、4,用户B评价过的电影有1、2、5:
|
Action |
Adventure |
Comedy |
Crime |
Drama |
Fantasy |
Romance |
Thriller |
War |
|
|
1 |
√ |
√ |
√ |
√ |
√ |
||||
|
2 |
√ |
√ |
√ |
√ |
|||||
|
3 |
√ |
√ |
|||||||
|
4 |
√ |
√ |
√ |
||||||
|
5 |
√ |
√ |
√ |
表格 2 用户A所选电影
|
Action |
Adventure |
Comedy |
Crime |
Drama |
Fantasy |
Romance |
Thriller |
War |
|
|
1 |
√ |
√ |
√ |
√ |
√ |
||||
|
2 |
√ |
√ |
√ |
√ |
|||||
|
3 |
√ |
√ |
|||||||
|
4 |
√ |
√ |
√ |
||||||
|
5 |
√ |
√ |
√ |
表格 3 用户B所选电影
于是用户A和用户B的类型表示为:
|
Action |
Adventure |
Comedy |
Crime |
Drama |
Fantasy |
Romance |
Thriller |
War |
|
|
A |
2 |
1 |
2 |
1 |
1 |
1 |
1 |
1 |
|
|
B |
1 |
2 |
2 |
1 |
1 |
2 |
1 |
2 |
表格 4 用户A和B的类型表示
计算A和B的相似度时,只选取A、B均有值的类型,对于没有同时有值的类型不参与计算:
|
Action |
Adventure |
Crime |
Drama |
Fantasy |
Romance |
Thriller |
|
|
A |
2 |
1 |
2 |
1 |
1 |
1 |
1 |
|
B |
1 |
2 |
1 |
1 |
2 |
1 |
2 |
表格 5 实际有效的A和B类型维度
至于相似度的计算方法,可采取:
计算过程中特殊情况简化处理:
2)评分预测
预测分的计算过程如下:
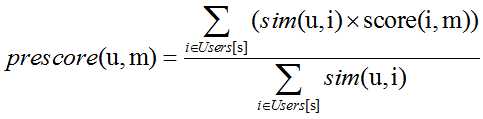
预测用户u对电影m的评分
3)特殊情况处理
4)数据结构及程序流程图
数据结构说明:
|
//用于存取用户基本信息,对应userid, movieid, score vector<map<long, float> > users(80000); //用户类型,用于计算相似度,对应userid, type, type的权值 vector<map<string, long> > users_type(80000); //用于存储待测试用户的信息,包括userid, movieid, 实际score, 预测score vector<map<long, pair<float,float> > > users_test(80000); map<long, map<long, float> > users_sim; //用于存储两个用户之间的相似度 map<int, vector<string> > movies; //用于存储电影的type map<long, vector<int> > movie_users; //用于存储看过某个电影的用户 |
主程序流程图:
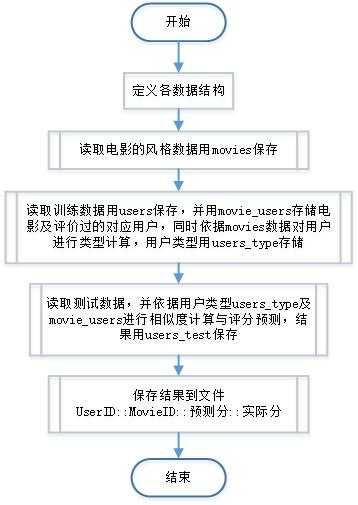
图 2 程序主体流程图
相似度计算函数流程图(本来打算采取空间换时间效率的策略,存取计算过的用户间的相似度,但是发现空间消耗太大,服务器无法跑):
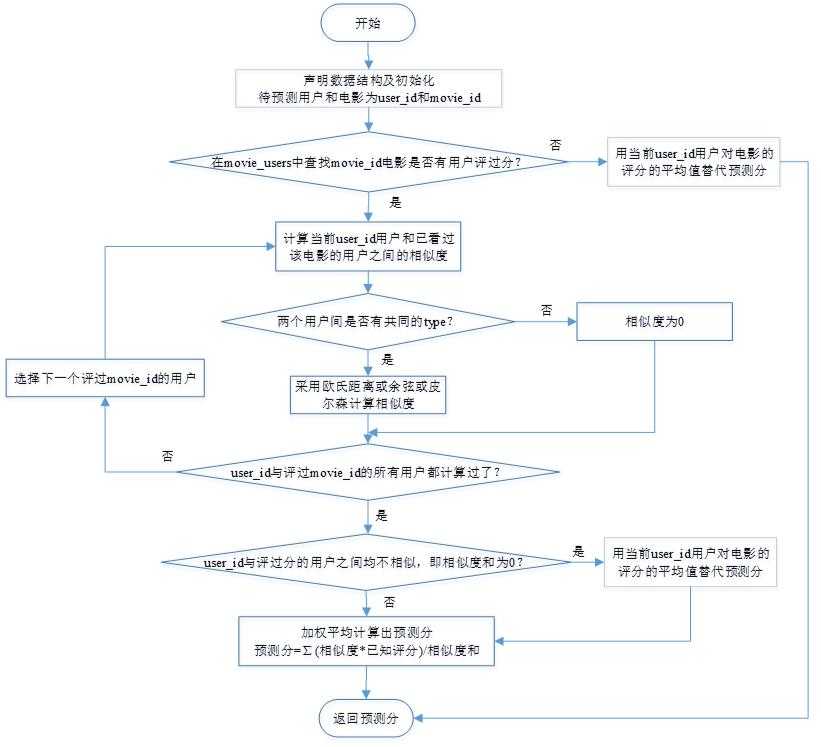
图 3 相似度计算流程图
5)RMSE
|
相似计算方法 |
RMSE |
|
欧几里得距离 |
0.978840 |
|
余弦相似 |
0.979142 |
|
皮尔森相似 |
0.977616 |
代码和数据(代码并没有采取空间换时间策略,因为空间消耗真的不是一般的大,大概十几G,进程会被Kill):
http://pan.baidu.com/s/1pJDJEfL
http://pan.baidu.com/s/1mgMDnsO
数据该放在哪,具体看代码的main函数里面,自己改改路径,想放哪都行。
原文:http://www.cnblogs.com/yanqi0124/p/3795047.html