跟随表哥学习了点内容。一点小问题就容易烦我一整天。但是到最后问题解决的时候,总是挺刺激的。于是乎就碰到了这么一个问题。
向数据库中插入一百万条记录,然后通过模糊搜索。
内容大概就是如此。
搜索的语句一开始是:select * from n_news where content like "%中国%" limit 10 offset 3。一开始搜索,速度很快。一瞬间的事情,但是随着offset和length的值不断增大,的发现查询的结果原来越慢。几秒,十几秒。那么问题来了,如何优化查询,将速度缩短到一秒内?围绕着这个问题,我开始思考,并在不断的搜索资料的过程中徘徊。
对已一般的查询例如 % 开头 或者 % 结尾的 模糊搜索语句可以通过添加索引优化,但是如果是 %...% 两个百分号中的搜索,就只有通过全文搜索。
对此我对id添加了索引
没有对desc添加索引的时间是11.078s
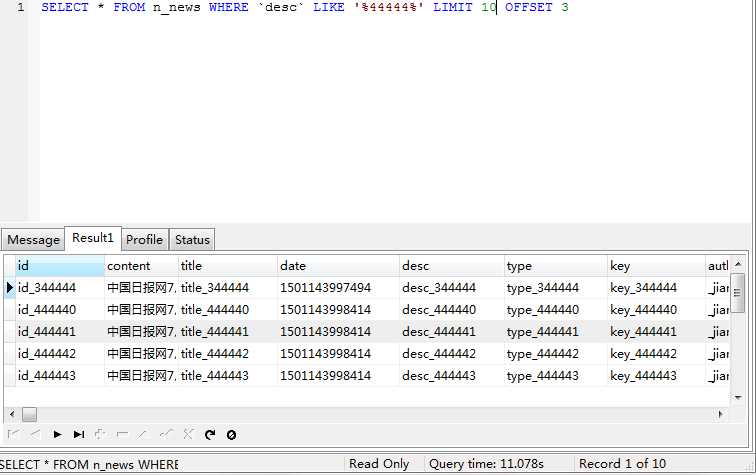
id添加了索引的是10.817s
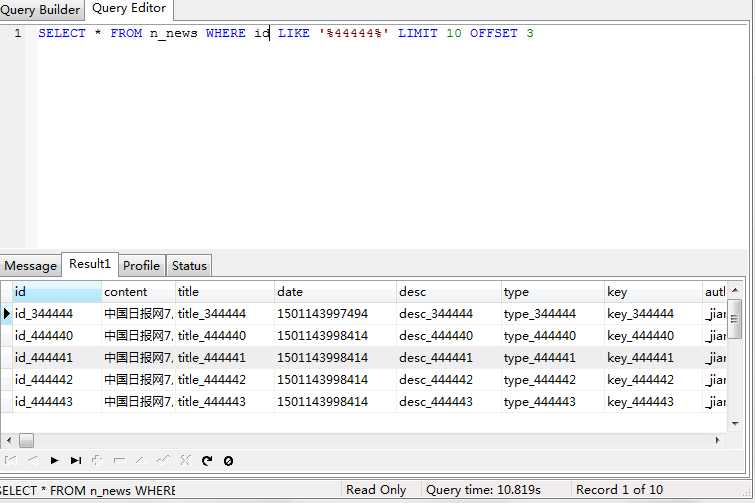
但是作用不大。
同时对于优化也看了其他方法,都是没有效果的,例如:
SELECT * FROM n_news WHERE locate(‘44444‘, id ) >0 LIMIT 10 OFFSET 3
SELECT * FROM n_news WHERE instr(id ,‘44444‘) >0 LIMIT 10 OFFSET 3;
时间也是在10秒多,于是感受到深深的绝望。
如何优化?真是急,在线等!
原文:http://www.cnblogs.com/jiang-z/p/sql.html