相比较于非线性逼近,线性逼近的好处是只有一个最优值,因此可以收敛到全局最优。其中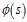 为状态s处的特征函数,或者称为基函数。
为状态s处的特征函数,或者称为基函数。
常用的基函数的类型为:
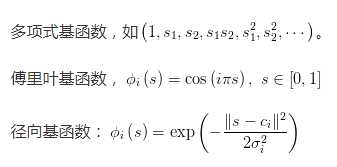
增量式方法参数更新过程随机性比较大,尽管计算简单,但样本数据的利用效率并不高。而批的方法,尽管计算复杂,但计算效率高。
批处理方法:


所谓时间差分方法,是指利用时间差分目标来更新当前行为值函数。在图1.1 Q-learning伪代码中,时间差分目标为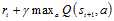 。
。
原文:http://www.cnblogs.com/imagef/p/7434995.html