Kafka是一个使用越来越广的消息系统,尤其是在大数据开发中(实时数据处理和分析)。为何集成其他系统和解耦应用,经常使用Producer来发送消息到Broker,并使用Consumer来消费Broker中的消息。Kafka Connect是到0.9版本才提供的并极大的简化了其他系统与Kafka的集成。Kafka Connect运用用户快速定义并实现各种Connector(File,Jdbc,Hdfs等),这些功能让大批量数据导入/导出Kafka很方便。
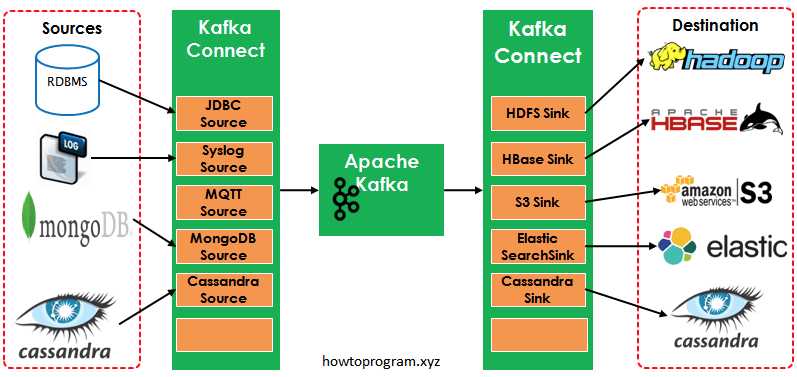
如图中所示,左侧的Sources负责从其他异构系统中读取数据并导入到Kafka中;右侧的Sinks是把Kafka中的数据写入到其他的系统中。
Kafka Connector很多,包括开源和商业版本的。如下列表中是常用的开源Connector
| Connectors | References |
| Jdbc | Source, Sink |
| Elastic Search | Sink1, Sink2, Sink3 |
| Cassandra | Source1, Source 2, Sink1, Sink2 |
| MongoDB | Source |
| HBase | Sink |
| Syslog | Source |
| MQTT (Source) | Source |
| Twitter (Source) | Source, Sink |
| S3 | Sink1, Sink2 |
商业版的可以通过Confluent.io获得
本例演示如何使用Kafka Connect把Source(test.txt)转为流数据再写入到Destination(test.sink.txt)中。如下图所示:
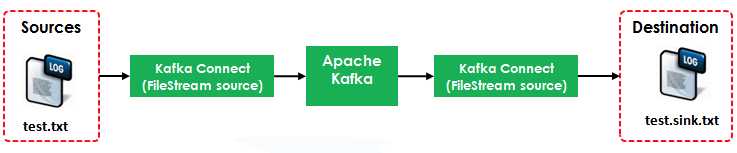
本例使用到了两个Connector:
其中的Source使用到的配置文件是${KAFKA_HOME}/config/connect-file-source.properties
name=local-file-source connector.class=FileStreamSource tasks.max=1 file=test.txt topic=connect-test
其中的Sink使用到的配置文件是${KAFKA_HOME}/config/connect-file-sink.properties
name=local-file-sink connector.class=FileStreamSink tasks.max=1 file=test.sink.txt topics=connect-test
Broker使用到的配置文件是${KAFKA_HOME}/config/connect-standalone.properties
bootstrap.servers=localhost:9092key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter.schemas.enable=trueinternal.key.converter=org.apache.kafka.connect.json.JsonConverter internal.value.converter=org.apache.kafka.connect.json.JsonConverter internal.key.converter.schemas.enable=false internal.value.converter.schemas.enable=false offset.storage.file.filename=/tmp/connect.offsets offset.flush.interval.ms=10000
需要熟悉Kafka的一些命令行,参考本系列之前的文章Apache Kafka系列(二) 命令行工具(CLI)
3.2.1 启动Kafka Broker
[root@localhost bin]# cd /opt/kafka_2.11-0.11.0.0/ [root@localhost kafka_2.11-0.11.0.0]# ls bin config libs LICENSE logs NOTICE site-docs [root@localhost kafka_2.11-0.11.0.0]# ./bin/zookeeper-server-start.sh ./config/zookeeper.properties &
[root@localhost kafka_2.11-0.11.0.0]# ./bin/kafka-server-start.sh ./config/server.properties &
3.2.2 启动Source Connector和Sink Connector
[root@localhost kafka_2.11-0.11.0.0]# ./bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
3.3.3 打开console-consumer
./kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic connect-test
3.3.4 写入到test.txt文件中,并观察3.3.3中的变化
[root@Server4 kafka_2.12-0.11.0.0]# echo ‘firest line‘ >> test.txt [root@Server4 kafka_2.12-0.11.0.0]# echo ‘second line‘ >> test.txt 3.3.3中打开的窗口输出如下 {"schema":{"type":"string","optional":false},"payload":"firest line"} {"schema":{"type":"string","optional":false},"payload":"second line"}
3.3.5 查看test.sink.txt
[root@Server4 kafka_2.12-0.11.0.0]# cat test.sink.txt firest line second line
本例仅仅演示了Kafka自带的File Connector,后续文章会完成JndiConnector,HdfsConnector,并且会使用CDC(Changed Data Capture)集成Kafka来完成一个ETL的例子
PS:
相比编译过Kafka-Manager都知道各种坑,经过了3个小时的努力,我终于把Kafka-Manager编译通过并打包了,并且新增了Kafka0.11.0版本支持。
附下载地址: 链接: https://pan.baidu.com/s/1miiMsAk 密码: 866q
Apache Kafka系列(五) Kafka Connect及FileConnector示例
原文:http://www.cnblogs.com/qizhelongdeyang/p/7407273.html