本文介绍的是HDFS的一种HA方案。虽然有checkpoint node \backup node等,但是不能实现自动的failover.
1.在2.0.0版本以下,namenode是单个的,如果namenode宕机,就会导致整个集群不可用。QJM 是HA的一种实现方式,通过master/slave方式启动多个namenode。
2.结构
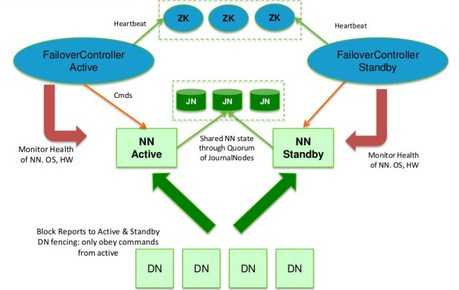
一般情况下,两个namenode组成master/slave结构,这两个namenode再连接到一组JNs(JournalNodes).master把集群的修改记录写到大多数据的JNs上,slave从JNS上读取修改信息并合并到本地的命名空间中。当master namenode故障后,slave在合并完所有修改记录后切换为active 状态的namenode.
为了尽快的实现灾难切换,slave还需要实时的从datanode上读取块的最新信息。因此所有的datanode都要同时连接到master/slave 的namenode上。
任一时刻必须只有一个namenode 是active状态,不然datanode会读取到混乱的数据。JNS集群保证在任一时刻只有一个namenode能修改(JNS上的数据)
3.硬件
namenode:两台配置一样的物理机,一台master 一台slave
JNS :奇数个机器集群(满足majority)。最多允许(N-1)/2个节点失效。
4.部署
一)、配置 和HDFS Federation类似,HA配置向后兼容,运行只有一个Namenode运行而无需做任何修改。新的配置中,要求集群中所有的Nodes都有相同的配置文件,而不是根据不同的Node设定不同的配置文件。 和HDFS Federation一样,HA集群重用了“nameservice ID”来标识一个HDFS 实例(事实上它可能包含多个HA Namenods);此外,“NameNode ID”概念被添加到HA中,集群中每个Namenode都有一个不同的ID;为了能够让一个配置文件支持所有的Namenodes(适用与Federation环境),那么相关的配置参数都以“nameservice ID”或“Namenode ID”作为后缀。 修改hdfs-site.xml,增加如下几个配置参数,其参数的顺序无关。 1、dfs.nameservices:nameservice的逻辑名称。可以为任意可读字符串;如果在Federation中使用,那么还应该包含其他的nameservices,以","分割。- <property>
- <name>dfs.nameservices</name>
- <value>hadoop-ha,hadoop-federation</value>
- </property>
- <property>
- <name>dfs.ha.namenodes.hadoop-ha</name>
- <value>nn1,nn2</value>
- </property>
- <property>
- <name>dfs.namenode.rpc-address.hadoop-ha.nn1</name>
- <value>machine1.example.com:8020</value>
- </property>
- <property>
- <name>dfs.namenode.rpc-address.hadoop-ha.nn2</name>
- <value>machine2.example.com:8020</value>
- </property>
- <property>
- <name>dfs.namenode.http-address.hadoop-ha.nn1</name>
- <value>machine1.example.com:50070</value>
- </property>
- <property>
- <name>dfs.namenode.http-address.hadoop-ha.nn2</name>
- <value>machine2.example.com:50070</value>
- </property>
- <property>
- <name>dfs.namenode.shared.edits.dir</name>
- <value>qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/hadoop-ha</value>
- </property>
- <property>
- <name>dfs.journalnode.rpc-address</name>
- <value>0.0.0.0:8485</value>
- </property>
- <property>
- <name>dfs.journalnode.http-address</name>
- <value>0.0.0.0:8480</value>
- </property>
- <property>
- <name>dfs.client.failover.proxy.provider.hadoop-ha</name>
- <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
- </property>
- <property>
- <name>dfs.ha.fencing.methods</name>
- <value>shell(/path/to/my/script.sh arg1 arg2 ...)</value>
- </property>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://hadoop-ha</value>
- </property>
- <property>
- <name>dfs.ha.automatic-failover.enabled</name>
- <value>true</value>
- </property>
- <property>
- <name>ha.zookeeper.quorum</name>
- <value>zk1.example.com:2181,zk2.example.com:2181,zk3.example.com:2181</value>
- </property>
三:QJM HDFS高可用
原文:http://www.cnblogs.com/skyrim/p/7455548.html