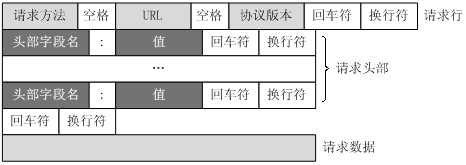
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图给出了请求报文的一般格式。
请求行
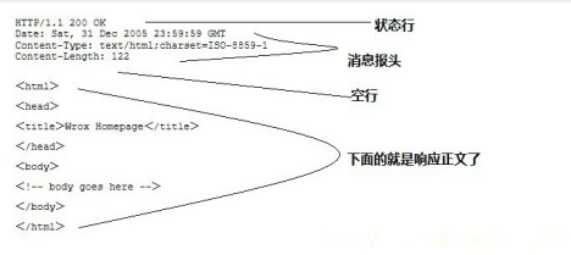
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
下面是一些最常见的请求头:
Accept:浏览器可接受的MIME类型。
Accept - Charset:浏览器可接受的字符集。
Accept - Encoding:浏览器能够进行解码的数据编码方式,比如gzip。Servlet能够向支持gzip的浏览器返回经gzip编码的HTML页面。许多情形下这可以减少5到10倍的下载时间。
Accept - Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到。
Authorization:授权信息,通常出现在对服务器发送的WWW - Authenticate头的应答中。
Connection:表示是否需要持久连接。如果Servlet看到这里的值为“Keep - Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点,Servlet需要在应答中发送一个Content - Length头,最简单的实现方法是:先把内容写入ByteArrayOutputStream,然后在正式写出内容之前计算它的大小。
Content - Length:表示请求消息正文的长度。
Cookie:这是最重要的请求头信息之一,参见后面《Cookie处理》一章中的讨论。
From:请求发送者的email地址,由一些特殊的Web客户程序使用,浏览器不会用到它。
Host:初始URL中的主机和端口。
If - Modified - Since:只有当所请求的内容在指定的日期之后又经过修改才返回它,否则返回304“Not Modified”应答。
Pragma:指定“no - cache”值表示服务器必须返回一个刷新后的文档,即使它是代理服务器而且已经有了页面的本地拷贝。
Referer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面。
User - Agent:浏览器类型,如果Servlet返回的内容与浏览器类型有关则该值非常有用。
UA - Pixels,UA - Color,UA - OS,UA - CPU:由某些版本的IE浏览器所发送的非标准的请求头,表示屏幕大小、颜色深度、操作系统和CPU类型。
HTTP状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
HTTP状态码的英文为HTTP Status Code。
下面是常见的HTTP状态码:
200 - 请求成功
301 - 资源(网页等)被永久转移到其它URL
404 - 请求的资源(网页等)不存在
500 - 内部服务器错误
·HTTP请求流程
首先,http属于Tcp/Ip模型中的应用层协议,而两个应用程序(我们这里指的就是浏览器与服务器)之间要进行互相通信,首先得建立Tcp连接,然后浏览器才能向服务器发送请求信息,服务器在接受到请求信息后,返回相应的应答信息,浏览器接收到来自服务器的应答信息后,对这些数据进行解释执行。
在http 1.0的版本中,浏览器的每次请求(也就是对每一个页面的访问)都要求建立一次单独的连接,在处理完每一次的请求后,就自动释放连接。(这点我们应该都有感觉,比如我们访问一个页面,当该页面在浏览器中显示出来的时候,我们可以拔掉网线,此时该页面上的信息并不会丢失。)而当我们请求的网页文件中有很多图片、音乐、电影等信息时,服务器返回的信息中并不直接包含图片数据,而只是保存该图片的链接,当浏览器进行解释的时候,遇到图片的url时,才向服务器发出对图片的请求信息。可见如果一个网页中包含多个图片数据时,将会频繁的与服务器建立连接,与释放连接,这无疑会造成资源的浪费。
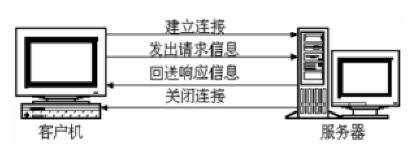
http 1.0 请求模式
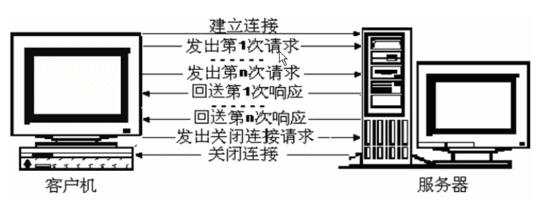
而http 1.1则可以在一次连接中处理多个请求,并且多个请求可以重叠进行,不需要等待一个请求结束后再发送下一个请求。
原文:http://www.cnblogs.com/home123/p/7487415.html