原文:http://www.linuxidc.com/Linux/2016-07/133508.htm
1.下载Hadoop安装包,笔者学习使用的是Hadoop1.2.1。提供一下下载地址吧: http://apache.fayea.com/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz。
2.创建/usr/local目录,进入此目录,下载安装包后解压,解压后出出现一个hadoop-1.2.1的文件夹,修改目录名为hadoop,进入该文件夹,目录结构如下图所示
#进入/usr/local cd /usr/local #下载hadoop安装包 wget http://apache.fayea.com/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
#等待下载完毕.....
#解压刚下载好的安装包(解压完后安装包可以删除,但建议备份到其他目录下)
tar -zxvf hadoop-1.2.1.tar.gz
mv hadoop-1.2.1 hadoop
cd hadoop
#查看结构
ll
3.下一步我们配置一下环境变量,在/etc目录下新建一个hadoop目录,后期将hadoop相关配置文件放在该目录下,直接使用该目录下的配置文件,然后使用vim编辑/etc/profile文件,追加如下配置并保存,输入source /etc/profile使配置立即生效:
#set hadoop environment export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$PATH
保存修改后执行:
source /etc/profile
4.怎么看是否安装成功呢?现在是单机模式,直接进入/usr/local/hadoop/bin目录中执行start-all.sh命令,过程中会询问是否连接,直接输入yes
cd /usr/local/hadoop/bin
./start-all.sh
5.使用jps命令查看hadoop进程是否启动成功,如下图所示:
6.因为现在是单机模式,NameNode和JobTracker没有启动,现在就使用hadoop fs -ls查看是否安装成功:
hadoop fs -ls
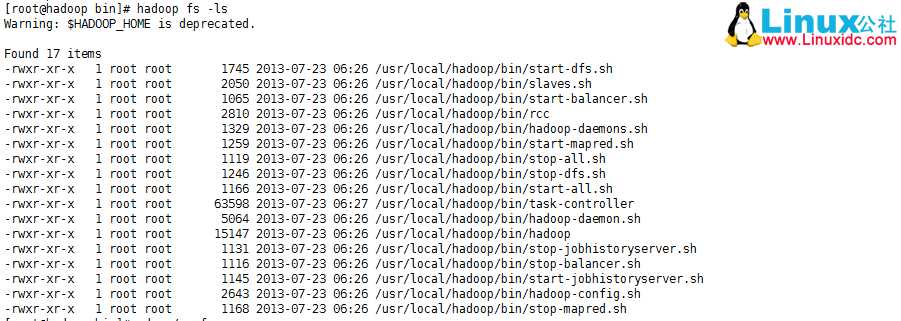
如上图所示,显示的是当前所在目录的目录结构,这样就说明安装成功了.重复以上步骤,为其他三台虚拟机也安装上吧!!
截止以上步骤,Hadoop的安装已经完成了。在下一篇我们在讲如何进行hadoop的集群配置吧!敬请期待哦!
全部系列见:
http://www.linuxidc.com/search.aspx?where=nkey&keyword=44572
更多Hadoop相关信息见:
Hadoop专题页面: http://www.linuxidc.com/topicnews.aspx?tid=13
原文:http://www.cnblogs.com/summersoft/p/7487551.html