原文链接:The internals of Python string interning
由于本人能力有限,如有翻译出错的,望指明。
这篇文章是讲Python string interning是如何工作的,代码基于CPython2.7.7这个版本。
前一段时间,我向同事解释了python的buil-in函数 intern背后到底做了什么。我给他看了下面这个例子:
>>> s1 = ‘foo!‘ >>> s2 = ‘foo!‘ >>> s1 is s2 False >>> s1 = intern(‘foo!‘) >>> s1 ‘foo!‘ >>> s2 = intern(‘foo!‘) >>> s1 is s2 True
你也许能大致猜出这段代码的运行结果,但这里面具体做了什么?正是今天要说的。
PyStringObject 结构体 让我们深入到CPython源码看一下 PyStringObject,这个c结构体代表着Python的string对象,其文件位于stringobject.h:
typedef struct { PyObject_VAR_HEAD long ob_shash; int ob_sstate; char ob_sval[1]; /* Invariants: * ob_sval contains space for ‘ob_size+1‘ elements. * ob_sval[ob_size] == 0. * ob_shash is the hash of the string or -1 if not computed yet. * ob_sstate != 0 iff the string object is in stringobject.c‘s * ‘interned‘ dictionary; in this case the two references * from ‘interned‘ to this object are *not counted* in ob_refcnt. */ } PyStringObject;
根据注释可得知,变量ob_sstate值不为0当前仅当这个字符串对象被interned。这个变量不会被直接读写,而是通过一个宏PyString_CHECK_INTERNED,其定义如下:
#define PyString_CHECK_INTERNED(op) (((PyStringObject *)(op))->ob_sstate)
interned 字典接下来让打开stringobject.c。看到第24行,这里声明了一个对象用于存储被interned的字符串对象:
static PyObject *interned;
事实上这个对象Python的字典对象,它在第4745行被初始化:
interned = PyDict_New();
最后,所有的魔法发生在函数PyString_InternInPlace的定义,第4732行代码。这里的实现十分简洁直观:
PyString_InternInPlace(PyObject **p) { register PyStringObject *s = (PyStringObject *)(*p); PyObject *t; if (s == NULL || !PyString_Check(s)) Py_FatalError("PyString_InternInPlace: strings only please!"); /* If it‘s a string subclass, we don‘t really know what putting it in the interned dict might do. */ if (!PyString_CheckExact(s)) return; if (PyString_CHECK_INTERNED(s)) return; if (interned == NULL) { interned = PyDict_New(); if (interned == NULL) { PyErr_Clear(); /* Don‘t leave an exception */ return; } } t = PyDict_GetItem(interned, (PyObject *)s); if (t) { Py_INCREF(t); Py_DECREF(*p); *p = t; return; } if (PyDict_SetItem(interned, (PyObject *)s, (PyObject *)s) < 0) { PyErr_Clear(); return; } /* The two references in interned are not counted by refcnt. The string deallocator will take care of this */ Py_REFCNT(s) -= 2; PyString_CHECK_INTERNED(s) = SSTATE_INTERNED_MORTAL; }
正如你所见,interned字典中存储的是键值均为指向string对象的指针。此外需要说明的是,string的派生类是不能被interned的。
用Python重写上述c代码如下:
interned = None def intern(string): if string is None or not type(string) is str: raise TypeError if string.is_interned: return string if interned is None: global interned interned = {} t = interned.get(string) if t is not None: return t interned[string] = string string.is_interned = True return string
十分简洁直观!
首先,显而易见的是,共享对象使得内存占用量更少了!让我们看回第一个例子,最初变量 s1和s2引用了两个不同的对象:
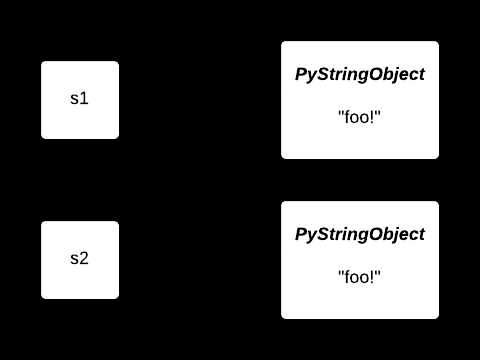
在调用了interned函数后,这两个变量都引用了同一个string对象,因此原来第二份string对象所占的内存就被节省下来了:
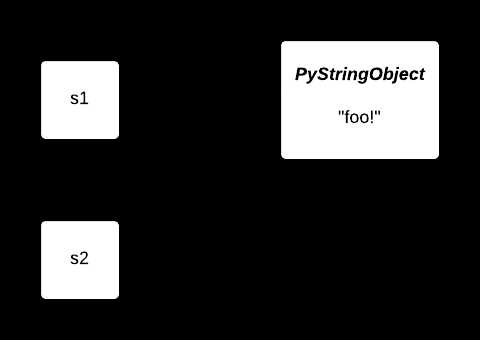
当处理大部分具有重复度高的特点的数据时(low entropy),interning的优势更为显著!
其次,string对象interned使得字符串比较可以更为高效。传统的字符串比较是逐个字节进行比较的(原文中这个说法不准确,实际上可以通过类似于memcpy的优化方式做到一次性比较多个字节),其时间复杂度为O(n)。而当string对象interned之后,只需要一次指针的比较操作即可,时间复杂度是O(1)。
在特定的条件下,string对象可以在编译期被interned(natively interned)。还是看回第一个例子,如果我们用 ‘foo‘ 取代 ‘foo!‘,结果是string对象 s1和s2被“自动”interned:
>>> s1 = ‘foo‘ >>> s2 = ‘foo‘ >>> s1 is s2 True
在写这篇博客之前,我一直认为,一个string对象是否能在编译期被interned,取决于这个string对象的长度以及构成的字符。(strings were natively interned according to a rule taking into account their length and the characters composing them.)
虽然实际上我离真相不远,但不幸的是,当我对各种以千奇百怪方式构成的字符串对进行观察时,我几乎不能猜出这里面的规则!你的话能猜出吗?
>>> ‘foo‘ is ‘foo‘ True >>> ‘foo!‘ is ‘foo!‘ False >>> ‘foo‘ + ‘bar‘ is ‘foobar‘ True >>> ‘‘.join([‘f‘]) is ‘‘.join([‘f‘]) True >>> ‘‘.join([‘f‘, ‘o‘, ‘o‘]) is ‘‘.join([‘f‘, ‘o‘, ‘o‘]) False >>> ‘a‘ * 20 is ‘aaaaaaaaaaaaaaaaaaaa‘ True >>> ‘a‘ * 21 is ‘aaaaaaaaaaaaaaaaaaaaa‘ False >>> ‘foooooooooooooooooooooooooooooo‘ is ‘foooooooooooooooooooooooooooooo‘ True
在看完上述例子后,你不得不承认确实很难分辨一个string对象何时会被interned。因此我们还是告别瞎猜,从CPython的源码中看答案吧:)
仍旧是stringobject.c文件,这一次我们将会看一下出现在函数PyString_FromStringAndSize和PyString_FromString的几行代码:
/* share short strings */ if (size == 0) { PyObject *t = (PyObject *)op; PyString_InternInPlace(&t); op = (PyStringObject *)t; nullstring = op; Py_INCREF(op); } else if (size == 1 && str != NULL) { PyObject *t = (PyObject *)op; PyString_InternInPlace(&t);
毫无疑问,所有长度为0或是为1的string对象都会被interned。
众所周知,Python的源码并不是直接的被解释执行的,而是通过一系列编译生成一种中间代码,称之为字节码的东西。Python字节码是一系列可以被Python虚拟机执行的指令集合。这些指令的文档在此,并且你可以通过dis这个模块来查看一个函数或是module被翻译成的字节码是如何的:
>>> import dis >>> def foo(): ... print ‘foo!‘ ... >>> dis.dis(foo) 2 0 LOAD_CONST 1 (‘foo!‘) 3 PRINT_ITEM 4 PRINT_NEWLINE 5 LOAD_CONST 0 (None) 8 RETURN_VALUE
正如你所知的,在Python里万物皆对象,而code对象是代表着一段可被执行的字节码。一个code对象执行字节码所需的所有必要的信息,比如:常量表(constants)以及符号表(variable names)等等。
事实证明,当在CPython中构建一个code对象时,一些额外的string对象被interned:
PyCodeObject * PyCode_New(int argcount, int nlocals, int stacksize, int flags, PyObject *code, PyObject *consts, PyObject *names, PyObject *varnames, PyObject *freevars, PyObject *cellvars, PyObject *filename, PyObject *name, int firstlineno, PyObject *lnotab) ... /* Intern selected string constants */ for (i = PyTuple_Size(consts); --i >= 0; ) { PyObject *v = PyTuple_GetItem(consts, i); if (!PyString_Check(v)) continue; if (!all_name_chars((unsigned char *)PyString_AS_STRING(v))) continue; PyString_InternInPlace(&PyTuple_GET_ITEM(consts, i)); }
在codeobject.c中,元组consts编译期定义的所有字面量(literals):程序中的所有布尔值、浮点数、整数以及字符串。存储在这其中的字符串会仅函数all_name_chars做一次筛选,剩下的将会被interned。
在下面这个例子中,s1属于编译期,而s2则属于运行时:
s1 = ‘foo‘ s2 = ‘‘.join([‘f‘, ‘o‘, ‘o‘])
结果是,s1将会被interned而s2不会。
函数all_name_chars将会把所有不是ascii字母、数字、下划线组成的字符串过滤掉:
#define NAME_CHARS "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz" /* all_name_chars(s): true iff all chars in s are valid NAME_CHARS */ static int all_name_chars(unsigned char *s) { static char ok_name_char[256]; static unsigned char *name_chars = (unsigned char *)NAME_CHARS; if (ok_name_char[*name_chars] == 0) { unsigned char *p; for (p = name_chars; *p; p++) ok_name_char[*p] = 1; } while (*s) { if (ok_name_char[*s++] == 0) return 0; } return 1; }
这也就解释了之前我列举的例子,为什么表达式 ‘foo!‘ is ‘foo!‘的值为False,而表达式 ‘foo‘ is ‘foo‘为True!
Victory? Not quite yet.
也许听上去有悖常理(我并不觉得),下面这个例子,string对象的连接操作是在编译期执行,而不是在运行时:
>>> ‘foo‘ + ‘bar‘ is ‘foobar‘ True
这也正是为什么 ‘foo‘ + ‘bar‘ 会被interned,从而导致了例子中表达式结果为True。
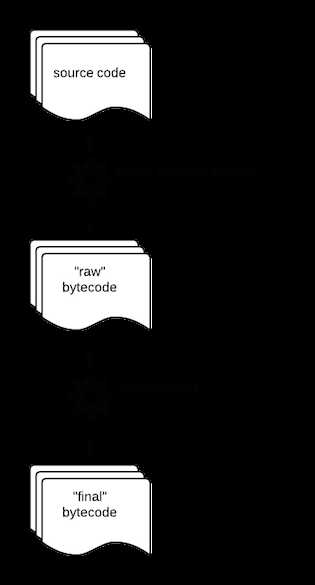
那么,字节码优化到底是怎样的呢?
实际上,源代码会先生成第一版的字节码,称之为 "raw"字节码。这个“raw”字节码还会被再处理一遍以生成更高效的字节码(通常是将某些虚拟机指令替换成更为高效的指令),而这个优化称之为“peephole optimization”。
peephole optimization处理的其中一项就是constant folding,其目的是更进一步的简化常量表达式。想象你是一个编译器,然后你正在处理下面这一行代码:
SECONDS = 24 * 60 * 60
你能为简化运行期的表达式计算、节省CPU时钟做哪些工作呢?显然是,在编译期就把表达式的结果计算出来,其值为86400。而这也正是对表达式 ‘foo‘ + ‘bar‘ 所进行的处理。
让我们写一段测试代码,然后再反汇编字节码看看:
>>> import dis >>> def foobar(): ... return ‘foo‘ + ‘bar‘ >>> dis.dis(foobar) 2 0 LOAD_CONST 3 (‘foobar‘) 3 RETURN_VALUE
看到了吧?实际上执行的字节码中并没有加法操作、也没有‘foo‘和’bar‘这两个字面量。如果CPython没有进行字节码优化,生成的字节码则可能是下面这样的:
>>> dis.dis(foobar) 2 0 LOAD_CONST 1 (‘foo‘) 3 LOAD_CONST 2 (‘bar‘) 6 BINARY_ADD 7 RETURN_VALUE
这也正是为什么下面这段表达式的值为True:
>>> ‘a‘ * 20 is ‘aaaaaaaaaaaaaaaaaaaa‘
好了,接下来的问题是,为什么 ‘a‘ * 21 is ‘aaaaaaaaaaaaaaaaaaaaa‘ 的值不为True呢?有留意你Python包里面出现的.pyc文件吗?实际上,Python的字节码正是存储在这些文件中。 那么,如果某人写出了类似于 [‘foo!‘] * 10**9 的代码,会发生什么事情呢?
结果会导致生成一个庞大的.pyc文件!而为了避免这种情况,peephole optimization将不会对序列长度大于20的做优化。
至此,你已经了解了所有关于Python string interning的知识!
I’m amazed at how deep I dug in CPython in order to understand something as anecdotic as string interning. I’m also surprised by the simplicity of the CPython API. Even though, I’m a poor C developer, the code is very readable, very well documented, and I feel like even I could contribute to it.
同感啊:P
最后,还有一件非常重要的事情,interning之所以能工作,是得益于Python中string对象是不可变的(immutable)。尝试Interning 可改变的(mutable )对象是行不通的也是具有巨大副作用的!
等等...我们知道Python里面还有其它的不可变对象。例如:整数(Integers),猜猜下面会发生什么有趣的事情?
>>> x, y = 256, 256 >>> x is y True >>> x, y = int(‘256‘), int(‘256‘) >>> x is y True >>> 257 is 257 True >>> x, y = int(‘257‘), int(‘257‘) >>> x is y False
;)
原文:http://www.cnblogs.com/adinosaur/p/7532939.html