题意:有一堆数据,某些是样例数据(假设X个),某些是大数据(假设Y个),但这些数据文件的命名非常混乱。要你给它们一个一个地重命名,保证任意时刻没有重名文件的前提之下,使得样例数据命名为1~X,大数据命名为X+1~X+Y。
先把未使用的名字压进两个栈。
分为三轮:第一轮把占用了对方名字的样例数据以及占用了对方名字的大数据放进两个队列,然后不断反复尝试对这两个队列进行出队操作,每次将占用对方名字的改成一个未被使用的正确名字(从栈里取出),然后将占用的名字压进另一个栈。由于每个数据只会出队一次,所以是O(n)。
第二轮尝试把不正确的文件名尽可能改成正确的,直到栈为空,只需循环一次即可。
剩下的必然是这种情况:
形成了循环占用,假设剩下N个,只需要用N+1次改名即可,类似这样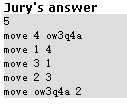 。
。
WA 144的注意:最初文件名可能含前导零。
#include<cstdio>
#include<queue>
#include<stack>
#include<iostream>
#include<string>
using namespace std;
int lim;
bool used[100005];
int trans(string name,int type){
int len=name.length();
for(int i=0;i<len;++i){
if(name[i]<‘0‘ || name[i]>‘9‘){
return -1;
}
}
if(name[0]==‘0‘){
return -1;
}
int shu=0;
for(int i=0;i<len;++i){
shu=shu*10+name[i]-‘0‘;
}
return shu;
}
struct data{
int id;
string name;
int type;
data(const int &id,const string &name,const int &type){
this->id=id;
this->name=name;
this->type=type;
}
data(){}
}a[100005];
stack<int>st[2];
queue<data>q[2];
int n;
bool changed[100005];
queue<string>ans[2];
int path[15],e;
string trans(int x){
e=0;
string res="";
while(x){
path[++e]=x%10;
x/=10;
}
for(int i=e;i>=1;--i){
res+=(path[i]+‘0‘);
}
return res;
}
int anss;
int main(){
//freopen("c.in","r",stdin);
scanf("%d",&n);
for(int i=1;i<=n;++i){
cin>>a[i].name>>a[i].type;
a[i].id=i;
if(a[i].type==1){
++lim;
}
}
for(int i=1;i<=n;++i){
if(a[i].type==1){
int t=trans(a[i].name,a[i].type);
if(t>=1 && t<=n) used[t]=1;
if(t>lim && t<=n){
q[1].push(a[i]);
}
}
else{
int t=trans(a[i].name,a[i].type);
if(t>=1 && t<=n) used[t]=1;
if(t<=lim && t>=1){
q[0].push(a[i]);
}
}
}
for(int i=1;i<=n;++i){
if(!used[i]){
if(i<=lim){
st[1].push(i);
}
else{
st[0].push(i);
}
}
}
while(1){
bool flag=0;
while(!q[1].empty()){
data U=q[1].front();
if(st[1].empty()){
break;
}
int to=st[1].top(); st[1].pop();
ans[0].push(U.name);
ans[1].push(trans(to));
++anss;
changed[U.id]=1;
flag=1;
st[0].push(trans(U.name,U.type));
q[1].pop();
}
while(!q[0].empty()){
data U=q[0].front();
if(st[0].empty()){
break;
}
int to=st[0].top(); st[0].pop();
ans[0].push(U.name);
ans[1].push(trans(to));
++anss;
changed[U.id]=1;
flag=1;
st[1].push(trans(U.name,U.type));
q[0].pop();
}
if(!flag){
break;
}
}
int tmp=0;
for(int i=1;i<=n;++i){
if(!changed[i]){
if(a[i].type==1){
int t=trans(a[i].name,a[i].type);
if(!(t<=lim && t>=1)){
if(!st[1].empty()){
ans[0].push(a[i].name);
ans[1].push(trans(st[1].top()));
++anss;
++tmp;
changed[i]=1;
st[1].pop();
}
}
}
else{
int t=trans(a[i].name,a[i].type);
if(!(t>lim && t<=n)){
if(!st[0].empty()){
ans[0].push(a[i].name);
ans[1].push(trans(st[0].top()));
++anss;
++tmp;
changed[i]=1;
st[0].pop();
}
}
}
}
}
// if(a[1].name=="7x6kel"){
// for(int i=1;i<=n;++i){
// if(trans(a[i].name,a[i].type)>=1 && trans(a[i].name,a[i].type)<=n){
// cout<<a[i].name<<endl;
// }
// }
// printf("%d\n",tmp);
// return 0;
// }
while(!q[1].empty()) q[1].pop();
while(!q[0].empty()) q[0].pop();
for(int i=1;i<=n;++i){
if(!changed[i]){
if(a[i].type==1){
int t=trans(a[i].name,a[i].type);
if(!(t>=1 && t<=lim)){
q[1].push(a[i]);
}
}
else{
int t=trans(a[i].name,a[i].type);
if(!(t>lim && t<=n)){
q[0].push(a[i]);
}
}
}
}
string last;
int cnt=0;
// if(q[0].size()!=q[1].size()){
// return 0;
// }
while(!q[0].empty()){
++cnt;
data U=q[1].front(),V=q[0].front();
ans[0].push(U.name);
if(cnt==1){
ans[1].push(trans(n+1));
}
else{
ans[1].push(last);
}
last=U.name;
ans[0].push(V.name);
ans[1].push(last);
last=V.name;
anss+=2;
q[0].pop(); q[1].pop();
}
if(cnt){
ans[0].push(trans(n+1));
ans[1].push(last);
++anss;
}
printf("%d\n",anss);
while(!ans[0].empty()){
cout<<"move "<<ans[0].front()<<‘ ‘<<ans[1].front()<<endl;
ans[0].pop(); ans[1].pop();
}
return 0;
}
原文:http://www.cnblogs.com/autsky-jadek/p/7542633.html