转:https://comsecuris.com/blog/posts/vmware_vgpu_shader_vulnerabilities/
In mid-January, the Zero Day Initiative announced the rules for the 2017 version of the contest, including considerably high rewards for owning VMware and performing an escape from the guest to the host. VMware itself is not a new target, but was first included as a target in 2016. VMware as a target already suffered from various exploits in the past and has a reasonably large attack surface. Interestingly, a fair share of serious vulnerabilities that could be used for guest escapes was uncovered back in 2006-2009 and then again starting in roughly 2015 again with work by Kostya Kortchinsky and lokihardt targeting VMware’s virtual printing and drag-and-drop/copy-and-paste functionality. Since then, researchers continued to hammer on VMware’s ThinPrint by Cortado and Drag’n’Drop. These developments are interesting from a passive observer’s point of view. At least to us, this raised the question of how rich VMware’s attack surface is these days and which parts are good targets for vulnerability discovery.
Despite a continuous flow of such vulnerabilities, none of the teams demonstrated a guest escape back in 2016 Pwn2Own. Even though typical desktop software such as VMware would usually not fit into our areas of research, we were quite interested in the challenge of figuring out how hard it actually would be to find vulnerabilities in VMware. At that time we have given ourselves the rough scope of a month in part-time(利用一个月业余时间来分析) work to peak into this. While unfortunately, we did not finish exploits in time for Pwn2Own, we did find serious vulnerabilities and wanted to use the chance to outline our road to finding exploitable bugs in VMware.(虽然没有及时利用成功,但是发现几个严重漏洞)
Without any prior detailed knowledge of VMware, it was actually not clear to us what makes sense to attack. Does it make sense to look for issues in instruction emulation? How much is emulated anyway given that there is CPU support for virtualization? Since we did want to reduce the likelihood of crashes, what else is there between printing and guest/host interaction such as DnD/C&P? Following is roughly what we have found. As per the Pwn2Own 2017 rules, all vulnerabilities must be reachable from an unprivileged user within the guest OS.
VMWare Workstation and Fusion consist of multiple parts of which the GUI is the least interesting. Under the hood, it consists of kernel modules both on the host and the guest side (vmnet/VMCI at least), thnuclnt (virtual printing), vmnet-dhcpd, vmnet-natd, vmnet-netifup, vmware-authdlauncher, vmnet-bridge, vmware-usbarbitrator, vmware-hostd and most importantly, vmware-tools within the guest. Almost all the host processes run as privileged processes, making them an interesting target for exploitation. Virtual printing has been exploited multiple times in the past.
vmnet-dhcpd caught our interest because it contained traces from ISC-DHCPD and runs as root. More interestingly, a very old version of it. Specifically, vmware-dhcpd is based off isc-dhcp2 from around 1999. Our early hopes for it being a good target however were destroyed by verifying the presence of known old vulnerabilities (CVE-2011-2749, CVE-2011-2748). It became clear that VMware does seem to be aware of this attack surface and invested the time to backport fixes from newer isc-dhcp releases to its fork. Not giving up early on this, we additionally decided to do a fuzz-run based on QEMU, AFL and small set of binary patches to vmware-dhcpd. After a month of fuzzing, this did not yield any interesting bugs however besides a few minor hangs. vmware-hostd is also an interesting process as it provides a webserver that is reachable from within the VM and mostly used for VM sharing. However, instead of drilling deeper into additional host software, we decided to turn our interest back to core parts of VMware.
vmware-vmx is the main hypervisor application running on the host and as most VMware processes, runs as root/SYSTEM and exposes several interesting features. In fact, this exists in two flavors: vmware-vmx and vmware-vmx-debug. The latter being used if debugging is enabled within the VMware settings. This is important, because when reverse engineering VMware, it is actually a lot easier to start off with vmware-vmx-debug due to its excessive(过多) presence of debug strings. It is not best suited however for actual vulnerability hunting as we will see later.debug适合逆向,vmx适合fuzz.
Did you ever wonder how you can drag-and-drop a file from your VM to your host desktop? This is where RPC comes into play. VMware internally offers a so-called backdoor interface on port 0x5658. It provides means for a guest to communicate with vmware-vmx APIs by issuing I/O instructions (IN/OUT) from within a guest. When passing a VMware specific magic value in a register, VMware internally evaluates additional passed arguments. I/O instructions are usually privileged. However, this particular port on the backdoor interface is one exception. The number of additional exceptions however is very limited and there are numerous additional validations when issuing backdoor commands (e.g. absMouseCommand) to determine if execution originates from a privileged guest account.
On top of this backdoor interface, VMware implements RPC services to be used to exchange data between the host and the guest. On the guest side, this RPC service is used by issuing backdoor commands from vmware-toolsd. In case you ever wondered why certain features just work when installed vmware-tools, this is why. The combination of X (on Linux) driver code and userspace utilities makes this possible.
The original backdoor interface just allows passing data in registers, which for large amounts of data is quite slow. To account for that, VMware introduced another backdoor port (0x5659) to host a “high-bandwidth” backdoor, which is actually used these days for RPC. This allows passing pointers to data, which vmware-vmx can use for read/writes rather than repeatedly issuing IN instructions. Derek also once found a pretty interesting vulnerability in this.
The idea behind the RPC interface is to provide commands for:
You might wonder what prevents processes to mess with RPC interaction of others. When opening a channel, VMware creates two cookie values, which are required to be sent with further send and receive commands. As far as we can judge, these are generated securely. As they are simply two uint32 dwords, they are also not compared using memcmp or other comparison routines with security impact.
On top of this, VMware implemented RPC command handlers for DnD, CnP, Unity (used for using windows as native host windows), setting of information and much more. A subset of these commands is again only available to privileged guest users. On the guest side, the rpctool provided by vmware-tools/open-vm-tools (most importantly, the RpcOut_sendOne() function) can be used to interact with API. A simple example to store and obtain guest information with this is:
rpctool ‘info-set guestinfo.foobar baz‘
rpctool ‘info-get guestinfo.foobar‘ -> baz
This illustrates storing information within vmware-vmx and later retrieving it. The details of data storage goes beyond the scope of this post, but VMware internally uses VMDB, which is a key value store working on paths and having the ability to attach callbacks to certain pieces of data.
The number of RPC commands that are allowed to unprivileged guest users however is quite limited. It is not easy to come up with a complete list of RPC commands as this is not only version and OS specific, but also subject to configuration settings(根据os版本和配置的不同,rpc命令列表也不同). The easiest way to get a list of currently active commands is by dumping the commands table at runtime from memory(最简单方式从内存dump出来). Kindly enough, the Linux version of vmware-vmx actually offers a symbol(有符号表?) that makes it very easy to do that: commands_ptr/commands.(分析下)
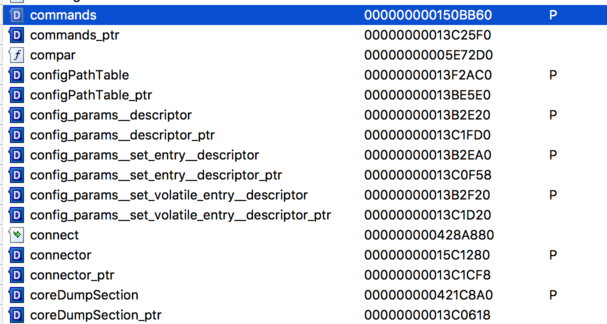
The most interesting attack surface for us on this interface seemed to be indeed Drag&Drop, C&P, and Unity. The reasons we did not go for these are two-fold(两个方面). First, this is what lokihardt was already targeting in his Pwnfest success. We expected others to further explore this particular area and find bugs. More importantly though, for Pwn2Own 2016 features such as Unity and Virtual printing were not allowed. Because of this and the documented risk, we expected that in 2017 VMware and ZDI are mostly interested in guest escapes that do not require features that can be switched off for security conscious users through isolations settings. The Pwn2Own 2017 rules did not provide further details here with regard to configuration settings and intention, but as a result, we turned our interest away from RPC.
It is worth mentioning though that irrespectively of that, the RPC interface can be of general use for VMware exploitation, as it provides a useful primitive for heap massaging (as also documented by the Marvel team).
So what is left attack-surface wise? Besides VMware’s core code around virtualization of instructions, it has to provide virtualization layers for various peripherals to a guest. This includes network, audio, USB, Bluetooth, disks, graphics, and more.
A combination of user-space services, guest kernel drivers, and code within vmware-vmx is responsible to provide virtualized devices for such features. For example, VMware provides an SVGA graphics card adapter within the guest, which acts as PCI display device driver (for both 2D and 3G). On Linux this comes with modifications to X code that is part of mesa/gallium, a kernel driver called vmwgfx, which issues ioctl system calls, and ultimately an SVGA3D/2D layer in vmware-vmx, which acts on these commands. The latter also provides an interesting set of commands that was previously targeted by Kostya in 2009. Our assumption was that virtualized peripherals provide enough attack surface that is activated by default on modern systems. Since we were looking for a feature rich attack surface that is enabled by default, non-trivial (but not impossible) to fuzz, and reasonably easy to dive into, we decided to further look into graphics.
Since the competition platform was going to be running VMware Workstation on Windows 10, we focused on graphics interaction on Windows rather than Linux. It is worth noting(注意)though that the presence of an Open Source implementation of VMware’s graphics driver portion within Gallium’s svga code helped tremendously in analyzing this portion within vmware-vmx. Likewise, Microsoft’s graphic driver samples helped in understanding how display drivers work on Windows in the first place.//shader着色器,有开源实现,同时windows有示例可以分析图形驱动如何工作
As others have targeted SVGA commands itself before, we wanted to dig a level deeper and look at parts of the featured functionality rather that itself included significant complexity: translation of GPU shader programs. Furthermore, a significant advantage of targetting shader bytecode over raw SVGA commands is that shader bytecode can be fed to vmware-vmx from guest userland. While on Linux and Mac OS, shaders are translated into OpenGL, on Windows they are translated into Direct3D actions. As VMware supports a number of different guest operating systems, different kinds of native shader code needs to be translated to host shader actions, which we expected to come with significant complexity and space for introducing vulnerabilities.//之前的研究聚焦与svga命令,我们关注在部分功能:gpu着色程序翻译。由于其在不同系统有不同实现,具有足够复杂性。
Our original analysis was based on VMware Workstation 12.5.3.
Two different virtual GPU implementations exist in VMware, a so-called VGPU9 (corresponding to DirectX 9.0) implementation that is used by older Windows guests and Linux guests and a VGPU 10 implementation that is used by Windows 10 guests.
For 3D accelerated graphics, VMware uses a WDDM (Windows Display Driver Model) driver in Windows 10 guests. This driver consists of a user-space and a kernel space part. The user-space portion is implemented within vm3dum64_10.dll, while the kernel-space driver is vm3dp.sys. When using a Direct3D 10 shader, the actual shader code goes through several layers of translation. Usually, the shader is first compiled from a so-called HLSL (High Level Shader Language) file to a bytecode representation. As VMware is providing virtualized 3D support, this bytecode cannot be used directly, but instead it needs to be further translated and the Direct 3D API needs to make use of the respective vendor-specific implementations for shader code. For this, the user-space driver implements callbacks that are stored in a D3D10DDI_DEVICEFUNCS structure. These are used to communicate and transform byte-code into a vendor-specific API, in this case VMware SVGA3D, which provides an API to define and set shaders. When flushing the shader code, the user-space driver goes through the pfnRenderCB callback of the kernel-space driver.
So any Windows application making use of GPU shaders will first and foremost utilize the Windows D3D11 API. This provides APIs to compile shader code from files, set them for different types of shaders (e.g. vertex), and render a scene. The rough translation path looks as follows:
There are a number of additional small details under the hood and the number of internal D3D11 APIs that are involved is quite large. The interested reader can get a better idea about this by looking at the Direct3D11 examples provided by Microsoft in Windbg and tracing its execution path (Windbg’s wt command).
0:000> x /D /f Tutorial03!i*
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
00000000`00da1900 Tutorial03!InitDevice (void)
00000000`00da28f0 Tutorial03!InitWindow (struct HINSTANCE__ *, int)
00000000`00da3630 Tutorial03!invoke_main (void)
00000000`00da3620 Tutorial03!initialize_environment (void)
00000000`00da4680 Tutorial03!is_potentially_valid_image_base (void *)
00000000`00da637a Tutorial03!IsDebuggerPresent (<no parameter info>)
00000000`00da63c8 Tutorial03!InitializeSListHead (<no parameter info>)
00000000`00da63aa Tutorial03!IsProcessorFeaturePresent (<no parameter info>)
0:000> bp Tutorial03!InitDevice
0:000> g
Breakpoint 0 hit
Tutorial03!InitDevice:
00da1900 55 push ebp
0:000:x86> wt -l 8
Tracing Tutorial03!InitDevice to return address 00da2dfe
259 0 [ 0] Tutorial03!InitDevice
100 0 [ 1] USER32!GetClientRect
...
When interacting with VMware’s shader implementation, it is important to understand how to write shaders in the first place.
Writing shaders for DirectX is done using the High Level Shading Language (HLSL) and compiled into bytecode using the D3D11 API or the fxc.exe program. Depending on which Shader Model is used, HLSL provides different types of shader features. The Shader Model assembly in bytecode form is the output of the HLSL compilation. VMware currently seems to support up to SM4 and SM3 internally, but not SM5 and SM6. This is important for reviewing translation implementations within vmware-vmx.
It is a little unfortunate that on current versions of Windows, there is no support anymore to write shader code in assembly instead of HLSL. As a result, crafting precise input for triggering vulnerabilities turns out to be a bit tricky. It is also important to note that D3D11 performs some sanitization of shader input so that fiddling with compiled shader objects (CSO files) can be tricky. Specifically, CSO files contain checksums that would need to be fixed. The API that checks these is D3D11_3SDKLayers!DXBCVerifyHash.
To get into a position to feed VMware with arbitrary shader bytecode, we instead leveraged the excellent Frida tool to hook and modify shader bytecode once all these steps have been taken. Specifically, we fed arbitrary shader bytecode into VMware by changing the compiled bytecode in memory once the vm3dum64_10.dll moves it in memory. Through reverse engineering, we determined the location of the respective memmove() and hooked that. Following is an excerpt from the Frida code that we used for that:
var vm3d_base = Module.findBaseAddress("vm3dum64_10.dll");
console.log("base address: " + vm3d_base);
function ida2win(addr) {
var idaBase = ptr(‘0x180000000‘);
var off = ptr(addr).sub(idaBase);
var res = vm3d_base.add(off);
console.log("translated " + ptr(addr) + " -> " + res);
return res;
}
function start() {
var memmove_addr = ida2win(0x180012840);
var setShader_return = ida2win(0x180009bf4);
Interceptor.attach(memmove_addr, {
onLeave : function (retval) {
if (!this.hit) {
return;
}
Memory.writeU32(this.dest_addr.add(...), ...);
....
},
onEnter : function (args) {
var shaderType = Memory.readU8(args[1].add(2));
if (!this.returnAddress.compare(setShader_return)) {
if (shaderType != 1) { return; }
this.dest_addr = args[0];
this.src_addr = args[1];
this.len = args[2].toInt32();
this.hit = 1;
...
});
}
The above code listing uses Frida’s Interceptor feature to hijack the flow of execution when calling memmove() inside vm3dum64_10. Every time the code enters memmove(), its return value is compared to match an address within the setShader() function. On a match, destination memory is patched with crafted shader bytecode when leaving memmove().
While we did not want to compete with other fuzz farms, due to this rather convoluted setup and the various translation steps, fuzzing was somewhat inconvenient for approaching this target, at least with the current setup and on Windows as the host OS.
It is worth noting that during our research, we noticed that Marco Grassi & Peter Hlavaty had given a presentation on shader fuzzing. While it is not obvious from the presentation we later found out that VMware released a small bare-metal OS called metalkit that also comes with some shader examples; this seems to have been the basis for their fuzzing approach. Their findings can be found here.
VMware is still quite a large piece of software so that we did not know how hard it will be to identify the shader translation routines within vmware-vmx. There is essentially two directions to approach this problem: identify shader translation directly or follow SVGA3D command handlers, specifically handlers such as DXDefineShader, DXBindShader, DefineSurface etc.
These are relatively easy to find as a string table containing these can be found within the binary. These are used in a function translating SVGA3d command ids to strings.
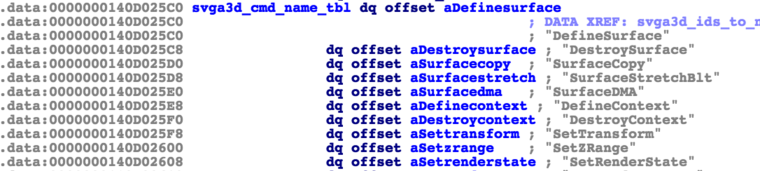
This doesn’t lead directly to their respective handlers, but looking e.g. for “svgaDXCmd” strings finds several functions, which have a cross reference in another large table in memory (only).

Labeling these in a table, using the same offset as in the string table, reveals the concrete handlers. As these are ultimately used to control shader operations, following them leads us to shader parsing and translation code. Internally, there is a command FIFO between the kernel driver and vmware-vmx, which is used to push SVGA3D commands to the hypervisor. These routines first pull data from it and then call further internal processing routines.
To get directly to the shader code instead there are two ways. The first, utilizing strings contained in vmware-vmx-debug allows to go directly to the shader parsing and translation code – we followed cross-references to the strings “shaderParseSM4.c” and “shaderTransSM4.c”. While we did this initially, auditing the debug version of vmware-vmx for shader vulnerabilities has a big drawback: it contains checks that are not present in vmware-vmx.
We are not quite sure whether this is an oversight of VMware or what caused this, but at the time of auditing vmware-vmx, it seemed to be an omnipresent pattern to have numerous of security critical checks in shader parsing and translation code that would only be present in the -debug variant.
Instead, searching for specific immediate operands finds the code in the non-debug version and has the nice side effect that these definitions can be used to make the respective code in IDA much more readable. Thanks to the mesa driver, it is easy to know what values to look for. Specifically, its VPGU10 definitions were quite useful for our analysis and IDB annotations.
Now when vmware-vmx needs to translate guest shader code to host shader code, it first parses the packed shader code created from VMware libraries within the guest. Reverse engineering this functionality and also crafting meaningful input for verification is what took us most of the time, also due to the lack of low level documentation on shader bytecode. A blog post by Tim Jones was very helpful for that: “Parsing Direct3D shader bytecode” (thank you for that!).
The initial parsing of each specific opcode then is relatively simple as for the majority of opcodes, the function ParseSM4() only stores away arguments.

While the parser code operates on raw bytecode data, it is similar to a classic TLV parser. The overall shader code comes with a length that allows the parser to know when to stop parsing, while each opcode comes with a type, an instruction length, and a value. More specifically, each opcode “header” is a dword where bits 0:10 determine the opcode, bits 11:23 can be used to encode opcode-specific data, bits 30:24 encode the opcode data length and bit 31 denotes if the opcode is extended (most opcodes are not).
As most of the opcodes contain values that fit into a single byte, the parser for the most part just copies byte values into an internal custom data structure that is largely unknown to us. The above VGPU10_OPCODE_CUSTOMDATA is one of the tokens/opcodes that is an exception to this as it contains a variable-length buffer for constants as can be seen in the dcl_immediateConstantBuffer description.
As mentioned, the internal data structure that is used is for the most part unknown to us. However, for finding vulnerabilities within the translation step this does not matter, because the used offsets within that data structure are the same. As a result, it is mostly straight-forward to audit TransSM4 in binary while knowing what its “inputs” are.
Altogether, this was still a very time consuming step for multiple reasons. First, without any prior knowledge about shader code and VMware’s graphic virtualization, it took some time to arrive at this point in the first place. Second, testing a hypothesis by crafting test shader bytecode was not straight forward due to the lack of an ability to write SM4 assembly directly. Instead, we manually patched bytecode in memory using the aforementioned Frida approach. Lastly, understanding SM4 instruction details and mapping understanding to encoding of opcodes is a beast on its own. Besides having a debugger on the host, there was one aspect here that also helped us during our reverse engineering work. Namely, the -debug variant of vmware-vmx has a lot of ASSERT statements that help in understanding errors. The function ParseSM4 also features a shader disassembler that can dump shader code to the VMware log.
Now lets look at the issues we found during our manual reverse engineering work. After Pwn2Own, we reported these issues and PoCs to ZDI on March 17th 2017.
When parsing a VGPU10_OPCODE_CUSTOMDATA token that defines an immediate constant buffer, the following pseudo-code snippet is executed:
case VGPU10_OPCODE_CUSTOMDATA:
v41 = v23 >> 11;
*(_DWORD *)(_out_p_16_ptr + op_idx + 16) = v41;
if ( (_DWORD)v41 == VGPU10_CUSTOMDATA_DCL_IMMEDIATE_CONSTANT_BUFFER )
{
*(_DWORD *)(_out_p_16_ptr + op_idx + 32) = insn_l;
custom_data_alloc = (void *)mksMemMgr_alloc(v41, 0x10009u, 4LL * (unsigned int)insn_l);// int overflow safe
*(_QWORD *)(_out_p_16_ptr + op_idx + 24) = custom_data_alloc;
memcpy(custom_data_alloc, bc_tmp_ptr, 4LL * *(unsigned int *)(_out_p_16_ptr + op_idx + 32));
v37 = 0;
insn_start = (int *)bc_tmp_ptr;
}
In this case insn_l represents a 32-bit immediate encoded in the customdata instruction. This is a special case as regular shader instructions do not use 32-bit length values. This length value denotes the number of dwords to follow within the customdata block. There are no restrictions on the length on this code path other than making sure that no out-of-bounds reads occur on the original shader bytecode.
Using the custom allocator wrapper mksMemMgr_alloc, which internally uses calloc, a heap-buffer of size 159384 is allocated. The function calloc is provided by msvcr90.dll; interestingly we observed this library to always be mapped into the lowest 4GByte of virtual memory. Subsequently, the immediate constant data is copied into this buffer. The calloc function on Windows 10 goes through RtlAllocateHeap and ends up allocating on the NT Heap. We shall refer to allocated buffer as outbuf in the following. The constant data itself is also under control of the attacker here.
After allocation of this buffer, the translation stage is entered. Upon encountering a VGPU10_OPCODE_CUSTOMDATA token, a function is called that performs the following memcpy without further checks:
result = memcpy(outbuf + 106228, custom_data_alloc, 4 * len);
where custom_data_alloc is the buffer allocated in the parsing stage indicated above. This allows writing controlled data into adjacent heap chunks and values stored within the aforementioned internal data structure for parsed opcodes, which resides in this area as well.
When processing a dcl_indexabletemp instruction, the shader parsing routine first uses the following pseudo-code:
case VGPU10_OPCODE_DCL_INDEXABLE_TEMP:
*(_DWORD *)(_out_p_16_ptr + op_idx + 16) = *insn_start;// index
*(_DWORD *)(_out_p_16_ptr + op_idx + 20) = insn_start[1];// index + value for array write operation in Trans
bc_tmp_ptr = insn_start + 3;
*(_DWORD *)(_out_p_16_ptr + op_idx + 24) = insn_start[2];
As you can see above, the values that are written at op_idx are part of the encoded instruction itself and reused later during the translation phase. There are no further restriction on the actual values during the parsing stage.
The following code shows the translation step:
case VGPU10_OPCODE_DCL_INDEXABLE_TEMP:
v87 = *(_DWORD *)(bytecode_ptr + op_idx + 24);
svga3d_dcl_indexable_temp((__int64)__out,
*(_DWORD *)(bytecode_ptr + op_idx + 16),// idx
*(_DWORD *)(bytecode_ptr + op_idx + 20),// val
(1 << v87) - 1); // val2
As we can see, the exact same index values are reused here (20, 16, 24) when calling svga3d_dcl_indexable_temp(). The variables idx and val are directly under attacker control while the 4th parameter to the function is derived from the third dword of the original instruction ((1 << val2) - 1).
Following is the code of the function svga3d_dcl_indexable_temp().
__int64 __fastcall svga3d_dcl_indexable_temp(__int64 a1, unsigned int idx, int val, char val2)
{
__int64 result; // rax@5
const char *v5; // rcx@7
const char *v6; // rsi@7
signed __int64 v7; // rdx@7
*(_DWORD *)(a1 + 8LL * idx + 0x1ED80) = val;
*(_BYTE *)(a1 + 8LL * idx + 0x1ED84) = val2;
*(_BYTE *)(a1 + 8LL * idx + 0x1ED85) = 1;
result = idx;
return result;
In the above listing, a1 is a heap-buffer that comes from the translation routine. It is the same structure that is allocated and used in the aforementioned custom data case. What’s different to this bug is that this issue allows us to use a 32-bit dword as a write-offset within this buffer starting at offset 0x1ed80.
So this vulnerability gives us the capability of writing a controlled dword at an arbitrary dword index from within the aforementioned heap-structure. The next written 2 bytes will be the aforementioned val2 value based on the original shader code instruction content with one byte being 1 (and 2 bytes remaining zero).
When the translation stage is processing a dcl_resource instruction, the following code snippet is executed:
int hitme[128]; // [rsp+1620h] [rbp-258h]@196
int v144; // [rsp+1820h] [rbp-58h]@204
char v145; // [rsp+1824h] [rbp-54h]@303
bool v146; // [rsp+1830h] [rbp-48h]@14
char v147; // [rsp+1831h] [rbp-47h]@14
int v148; // [rsp+1880h] [rbp+8h]@1
__int64 v149; // [rsp+1890h] [rbp+18h]@1
__int64 v150; // [rsp+1898h] [rbp+20h]@14
...
case VGPU10_OPCODE_DCL_RESOURCE:
v87 = sub_1403C2200(*(_DWORD *)(v14 + 32));
v88 = sub_1403C2200(*(_DWORD *)(v14 + 28));
v89 = sub_1403C2200(*(_DWORD *)(v14 + 24));
v90 = sub_1403C2200(*(_DWORD *)(v14 + 20));
sub_1402FCF10(&v107, (__int64)outptr, *(_DWORD *)(v14 + 80), v86, v90, v89, v88, v87);
v11 = 0i64;
hitme[(unsigned __int64)*(unsigned int *)(v14 + 80)] = *(_DWORD *)(v14 + 16);
We did not fully dive into the details of sub_1403C2200() here, but these calls hardly matter as they have no influence on the stack overwrite targeting the hitme variable. In this case, the index (v14+80) again is a dword fully controlled by the input shader bytecode, while the value written is partially controlled and can hold values from 0 to 31. This means we can write aligned dwords. We use the plural here, since the bug can be triggered multiple times with values 0–31 to addresses that are up to 4Gbytes located above the address of hitme.
Exploitability depends on target and VMWare version here as obviously the stack layout is different on different platforms/versions.
When the vmware-vmx hypervisor process first starts, several memory mappings are created. Surprisingly, one of the mappings is created with read,write, and execute permissions and remains so during the lifetime of the process. This is the only memory segment for which this holds true. The mapping that is created here is the first page of the data segment of the vmware-vmx process.
Obviously, this significantly easens exploitation of vmware-vmx during a guest/host escape by providing a nice area to place and execute shellcode from.
7ff7`36b53000 7ff7`36b54000 0`00001000 MEM_IMAGE MEM_COMMIT PAGE_EXECUTE_READWRITE Image [vmware_vmx; "C:\Program Files (x86)\VMware\VMware Workstation\x64\vmware-vmx.exe"]
0:018> dq 7ff7`36b53000 L 0n1000/8
00007ff7`36b53000 ffffffff`ffffffff 00000001`fffffffe
00007ff7`36b53010 00009f56`1b68b8ce ffff60a9`e4974731
00007ff7`36b53020 00007ff7`36780a18 00007ff7`36780a08
00007ff7`36b53030 00007ff7`367809f8 00007ff7`367809e8
00007ff7`36b53040 00007ff7`367809d8 00000000`00000000
00007ff7`36b53050 00007ff7`36780990 00007ff7`36780940
00007ff7`36b53060 00007ff7`367808f0 00007ff7`367808a0
00007ff7`36b53070 00007ff7`36780860 00007ff7`36780820
00007ff7`36b53080 00007ff7`367807f0 00007ff7`367807a0
00007ff7`36b53090 00007ff7`36780750 00007ff7`36780700
As visible, the memory is mapped read/write/executable. The qword dump in Windbg is just meant to show that this is indeed matching the data section as seen in IDA:
.data:0000000140B33000 _data segment para public ‘DATA‘ use64
...
0000000140B33000 FF FF FF FF FF FF FF FF FE FF FF FF 01 00 00 00 ................
0000000140B33010 32 A2 DF 2D 99 2B 00 00 CD 5D 20 D2 66 D4 FF FF 2..-.+...] .f...
0000000140B33020 18 0A 76 40 01 00 00 00 08 0A 76 40 01 00 00 00 ..v@......v@....
0000000140B33030 F8 09 76 40 01 00 00 00 E8 09 76 40 01 00 00 00 ..v@......v@....
0000000140B33040 D8 09 76 40 01 00 00 00 00 00 00 00 00 00 00 00 ..v@............
0000000140B33050 90 09 76 40 01 00 00 00 40 09 76 40 01 00 00 00 ..v@....@.v@....
0000000140B33060 F0 08 76 40 01 00 00 00 A0 08 76 40 01 00 00 00 ..v@......v@....
0000000140B33070 60 08 76 40 01 00 00 00 20 08 76 40 01 00 00 00 `.v@.... .v@....
0000000140B33080 F0 07 76 40 01 00 00 00 A0 07 76 40 01 00 00 00 ..v@......v@....
0000000140B33090 50 07 76 40 01 00 00 00 00 07 76 40 01 00 00 00 P.v@......v@....
By the time we found the first two vulnerabilities, these were 0days in 12.5.3. Even after the contest these remained unfixed in 12.5.4.
Shortly after 12.5.4, VMware made another release as part of VMSA-2017-0006 that killed the first two heap-related issues in 12.5.5. As the details in the advisory are rather vague, we do not know if those issues were knowingly fixed or not. This is further the case due to an aspect that we mentioned earlier. Namely, the -debug variant of vmware-vmx has various error checks that the production version does not have. Specifically as we realized when those issues were fixed, it did have ASSERT checks for these two issues. So one theory would be to assume that those were fixed accidentally or internal findings as part of the Pwn2Own clean-up. According to ZDI, these were not clashes with other submissions and VMSA-2017-0006 only mentions ZDI reports.
As a result, we do not know if there are CVE ids for these specific flaws or if any researcher found these.
However, it is worth noting that this ASSERT pattern (or the lack thereof in non-debug) also affected other SM4 instructions. We can confirm that until 12.5.5 at least dcl_indexRange and dcl_constantBuffer had similar heap out-of-bounds writes.
The dcl_resource vulnerability remained unfixed in 12.5.5 and has been addressed after our research in 12.5.7 together with the DoS aspects. VMware ESXi 6.5 is also affected and was patched in ESXi650-201707101-SG. The memory corruption, which is CVE-2017-4924, was also covered in VMSA-2017-0015.
We currently believe that those initial fixes were due to internal code reorganization and not specifically because of reports. What leads to this belief is the fact that they were fixed with the exact same code as in the -debug version, using ASSERT statements rather than robust error handling. As a result, these could still be used to crash the VMware hypervisor.
PoCs for the issues can be found on https://github.com/comsecuris/vgpu_shader_pocs.
Before closing out this post, we would like to leave a few bits that we found helpful during our work. Hopefully they will be helpful to others as well. Particularly, the following aspects.
The vmware-vmx-debug variant is easier for getting started with reverse engineering. Contrary, the vmware-vmx non-debug variant is more useful for vulnerability hunting.
When reverse engineering vmware-vmx, the Linux version particularly has some oddities related to function inlining that makes RE work much more cumbersome than on Mac and Windows. Ultimately and to our surprise, we found the Windows version the easiest for reverse engineering work.
The Linux version on the flip side contains some symbols that are useful.
VMware has useful settings for interacting with shaders, specifically we found mks.dx11.dumpShaders, mks.shim.dumpShaders, and mks.gl.dumpShaders to be useful. There is likely many more.
The Linux version of vmware-vmx does not work when removing the PIE flag within the ELF binary. On Mac OS X this works when using the change_macho_flags.py script, which makes debugging a lot more convenient.
Now after all of this, we were still wondering where within vmware-vmx there is code related to emulate x86 instructions. We kind of assumed that when approaching such a target, we would quickly stumble upon this by accident. Yet, we have not seen any code early on. One theory was that this is because of hardware virtualization. However, as VMware can run in multiple modes, depending on settings and the underlying host architecture, this needed to be somewhere.
At some point, we noticed something that looks like an ELF header in memory. Simply using binwalk, a tool that you would normally rather not use on a regular PE or ELF executable, turned out something interesting:
binwalk vmware-vmx.exe
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
0 0x0 Microsoft executable, portable (PE)
...
13126548 0xC84B94 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
13126612 0xC84BD4 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
14073118 0xD6BD1E Unix path: /build/mts/release/bora-4638234/bora/vmcore/lock/semaVMM.c
14256073 0xD987C9 Sega MegaDrive/Genesis raw ROM dump, Name: "tSBASE", "E_TABLE_VA",
14283364 0xD9F264 Sega MegaDrive/Genesis raw ROM dump, Name: "ncCRC32B64", "FromMPN",
14942628 0xE401A4 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
14949876 0xE41DF4 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
14954108 0xE42E7C ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
14960892 0xE448FC ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
14991124 0xE4BF14 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
...
This seemed to weird to ignore it even though admittedly, binwalk can have false positives for sure. One of the biggest ELFs looked very interesting then as it contained a significant portion of functionality, but more important, it did contain symbols.
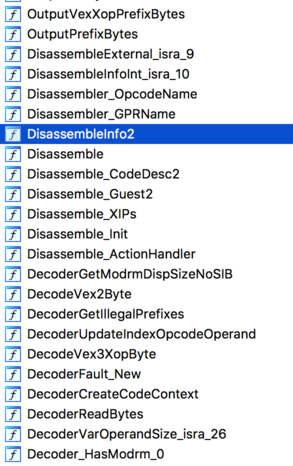
To our surprise, it does seem that this is an embedded ELF carrying an x86 disassembly/translation unit. We did not further drill down into how it is used, because it was not our target and we were mostly curious. We hope that this might be an interesting avenue for others to do further research.
While sadly we did not succeed with our original goal of putting together a full guest-to-host escape in time for Pwn2Own, we were quite satisfied with our findings for the time we set ourselves. We believe that VMware workstation is not only an interesting target for vulnerability discovery (on three major guest/host platforms), but it is also not that different from regular desktop software despite its hypervisor nature. Based on our own findings and screening other parts of its attack surface, we also believe that it remains to be a severely underexplored target considering its complexity and widespread use. For example, we barely scratched the surface of internal shader translation. Many code paths related to more specific shader operations (e.g. emitting new vertex, PS, … shaders) are left to be explored and likely carry significant additional complexity. Similarly, it appears that other components have been and are hit since a long time. Also considering the code we have seen and some of the VMware’s past security advisories, a lot of the defense work appears to be reactive rather than pro-active these days. Besides its core components, there remain interesting host components for further exploration. vmware-hostd, which carries a webserver with SSL support is one example here. We are looking forward to more security research around such hypervisor solutions and invite others to have a look as well.
原文:http://www.cnblogs.com/studyskill/p/7589000.html