希望老师讲一下python技术在哪些地方、哪些项目部分有所应用,可以的话展示一下部分的实际项目。
import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt f0 = open(‘全职法师.txt‘,‘r‘,encoding=‘utf-8‘) qz = f0.read() f0.close() words = list(jieba.cut(qz)) ul={‘那个‘, ‘但‘, ‘整个‘, ‘控‘,‘跟‘,‘再‘, ‘我们‘,‘个‘,‘看‘,‘没‘,‘们‘, ‘对‘, ‘怎么‘, ‘能够‘,‘颗‘,‘他们‘, ‘你们‘,‘知道‘, ‘什么‘,‘把‘, ‘一个‘,‘吧‘,‘系‘, ‘她‘,‘没有‘,‘已经‘,‘就是‘,‘可以‘,‘被‘,‘说‘,‘这个‘,‘得‘,‘给‘,‘还‘, ‘说道‘, ‘去‘,‘下‘, ‘上‘,‘好‘,‘里‘,‘会‘,‘要‘,‘到‘,‘和‘,‘让‘,‘不‘,‘那‘, ‘啊‘,‘很‘, ‘有‘,‘着‘,‘都‘,‘在‘, ‘这‘,‘的‘,‘了‘,‘是‘,‘就‘,‘我‘,‘也‘,‘他‘,‘你‘,‘、‘,‘”‘ ,‘“‘,‘。‘,‘!‘,‘?‘,‘ ‘,‘\u3000‘,‘,‘,‘\n‘} dic={} keys = set(words)-ul for i in keys: dic[i]=words.count(i) c = list(dic.items()) c.sort(key=lambda x:x[1],reverse=True) f1 = open(‘词云.txt‘,‘w‘) for i in range(20): print(c[i]) for words_count in range(c[i][1]): f1.write(c[i][0]+‘ ‘) f1.close() f3 = open(‘词云.txt‘,‘r‘) cy_file = f3.read() f3.close() cy = WordCloud().generate(cy_file) plt.imshow(cy) plt.axis("off") plt.show()
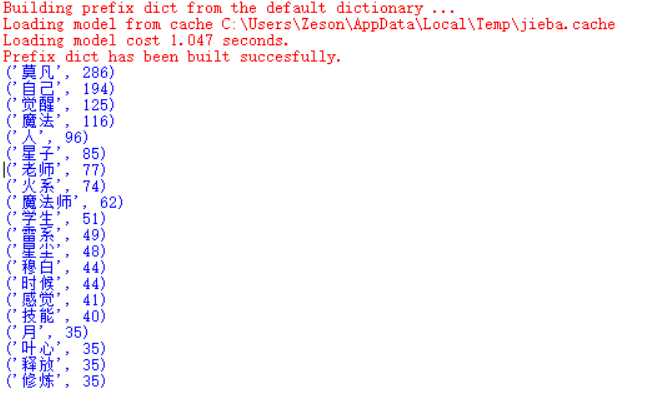
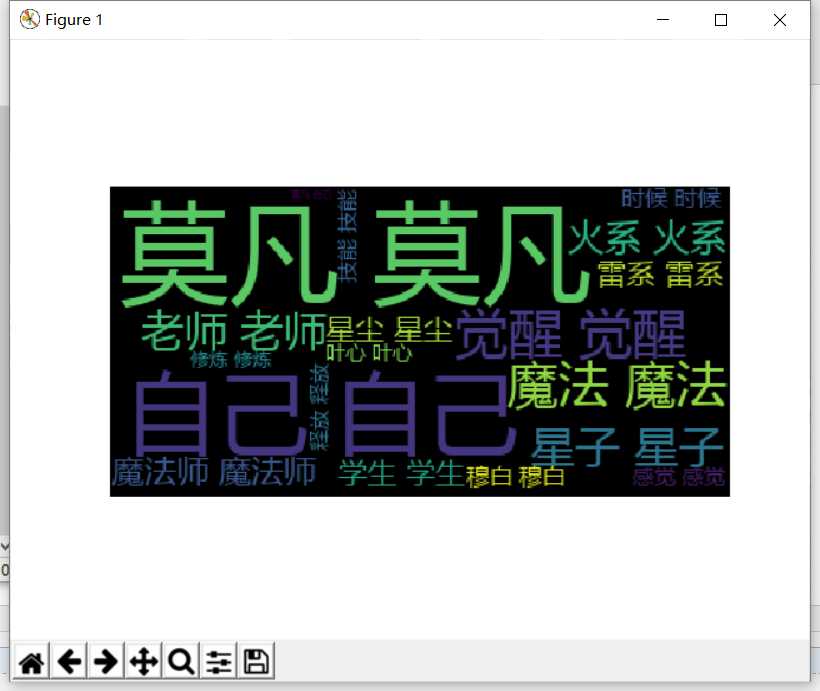
原文:http://www.cnblogs.com/zeson/p/7592560.html