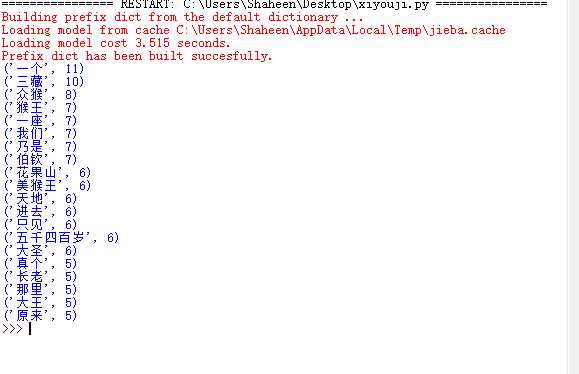
import jieba #打开文件,转换成UTF-8编码 fo=open(r‘C:\Users\Shaheen\AppData\Local\Programs\Python\Python36\西游记.txt‘,‘r‘,encoding=‘utf-8‘) a=fo.read() fo.close() #断词 words=list(jieba.cut(a)) s=set(words) dic={} #排除一些无意义词、合并同一词。 for i in s: if(i==" "): continue if(i==""): continue if len(i)==1: continue else: dic[i]=words.count(i) lis=list(dic.items()) lis.sort(key=lambda x:x[1],reverse=True) #输出TOP20的词及出现次数 for i in range(20): print(lis[i])
原文:http://www.cnblogs.com/pys965085265/p/7610513.html