中文分词
import jieba #导入jieba库 txt=open(‘weicheng.txt‘,‘r‘,encoding=‘utf-8‘).read()#读文件,把文件改为utf-8编码 words=list(jieba.cut(txt)) #对中文小说进行词语切分 exp={‘,‘,‘。‘,‘?‘,‘!‘} keys=set(words)-exp #排除一些无意义的标点符号,合并同一词 dic={} for k in keys: if len(k)>1: #去除无意义词 dic[k]=words.count(k) #统计词数 wc=list(dic.items()) wc.sort(key=lambda x:x[1],reverse=True) #对词进行排序 for i in range(20): print(wc[i]) #输出前20出现次数最多的词
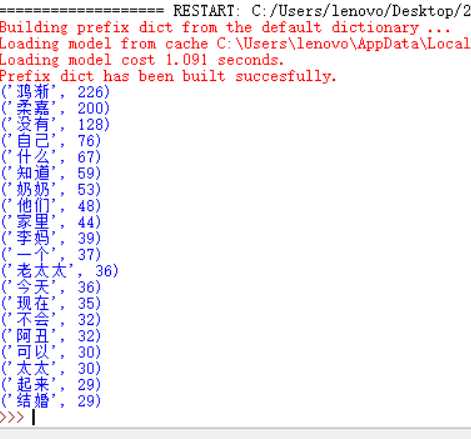
这是围城第九章时,鸿渐和柔嘉结婚之后的一些矛盾,还有和方老太太之间的一些矛盾和讨论。
原文:http://www.cnblogs.com/gdlyzx/p/7611605.html