1.下载一中文长篇小说,并转换成UTF-8编码。
2.使用jieba库,进行中文词频统计,输出TOP20的词及出现次数。
3.排除一些无意义词、合并同一词。
import jieba
txt=open(‘kobe.txt‘,‘r‘,encoding=‘UTF-8‘).read()for i in ‘,。!?:“”……()‘: txt=txt.replace(i,‘‘)words=list(jieba.cut(txt))dic={}for i in words: if len(i)==1: continue else: dic[i]=dic.get(i,0)+1wc=list(dic.items())wc.sort(key=lambda x:x[1],reverse=True)#print(a)for i in range(20): print(wc[i])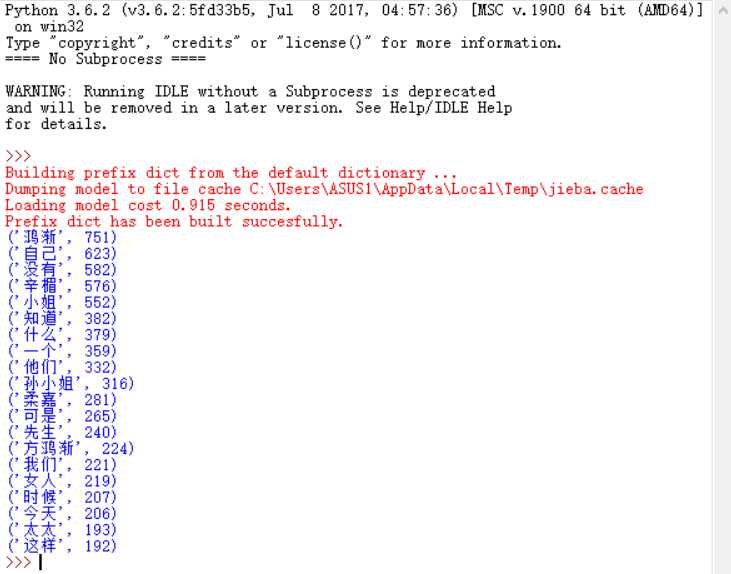
原文:http://www.cnblogs.com/z1-z/p/7613577.html