BeautifulSoup是用于解析html/xml的python库。它将html解析为树结构。每一个接节点都是一个python对象。
在这棵树上,共有四种对象:Tag, NavigableString, BeautifulSoup, Comment.
本随笔仅为学习笔记,欢迎大家交流和指出错误
Tag
<a class="QuestionText";id="6">python bs4 库</a>
这便是一个Tag,html文件便是许多个这样的Tag组成。
Tag有两个属性,一个是name,一个是attributes
上面的Tag中的 a 便是Tag的name, class="QuestionText" id="6" 便是attributes
如以下代码
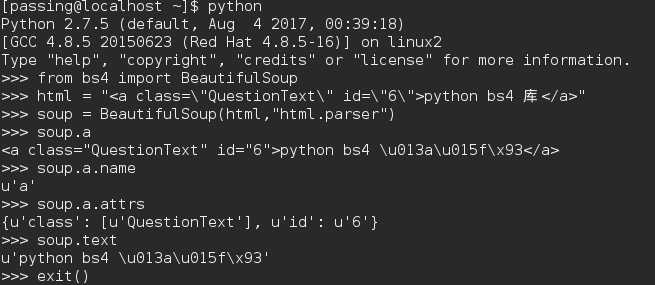
from bs4 import BeautifulSoup html = "<a class=\"QuestionText\" id=\"6\">python bs4 库</a>" soup = BeautifulSoup(html,"html.parser") #html.parser后面会谈到 soup.a #Tag soup.a.name #Tag的name soup.a.attrs #Tag的attrs soup.a.text #NavigableString
此外 soup.contents #将全部的子节点以列表的形式输出
soup.childern #将全部的子节点以生成器的形式输出
soup.parent #将所有的父节点以列表的形式输出
soup.parents #将所有的父节点以生成器的形式输出
soup.next_sibling #输出兄弟节点 带s的是以生成器
soup.previous_sibling
soup.next_siblings
soup.previous_siblings
运行结果如下
BeautifulSoup 表示一个文档的全部内容,大部分时候,可以把它当作是一个Tag.
Comment 注释,是一种特殊的NavigableString.
形如:
<a><!--这是一段注释--></a>
除此之外在爬虫里经常用到的就是
1.soup.find(name,attrs,recursive,text,args**)
soup.find_all(name,attrs,recursive,text,args**)
1. soup.find_all(‘a‘) #查找所有的name为a的Tag
<a class="test">python bs4</a>
2. soup.find_all(rel=‘icon‘) #查找所有含有rel="icon"属性的Tag
<link rel="icon" href="//www.jd.com/favicon.ico" type="imge"></link>
3. soup.find_all(clstag="h|keycount|2016|02a") #类似第二个查找某个attrs为clstag的Tag
<a class="logo_tit_lk" href="//www.jd.com">\u4eac\u4e1c</a></h1>\n<h2 class="logo_subtit">\u4eac\u4e1c,\u591a\u5feb\u597d\u7701</h2>\n<div class="logo_extend"></div>\n</div>
4. soup.find_all(‘li‘,class_=‘spacer‘) #找到所有name=li class=spacer的Tag
[<li class="spacer"></li>, <li class="spacer"></li>, <li class="spacer"></li>, <li class="spacer"></li>, <li class="spacer"></li>, <li class="spacer"></li>, <li class="spacer"></li>]
当添加limits参数时,是对查找结果进行限制。如limits=2,就是只找两个
soup.find() 就相当于 soup.find(limits=1)
通过以上两个函数就可以逐层查找来找到想要的Tag然后逐层的向下寻找,直到获取全部信息。
2.与上面的两个函数类似的就是soup.select() 利用css选择器来搜索
1 1.soup.select(".sister") #按照class的值来查找
2 # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
3 # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
4 # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
5 2.soup.select("#link1") #按照id的值来查找
6 # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
7 soup.select("a#link2")
8 # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
9 3.soup.select(‘a[href]‘) #通过attrs来查找
10 # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
11 # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
12 # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
13 4.soup.select(‘a[href="http://example.com/elsie"]‘) #通过attrs的值来查找
14 # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
原文:http://www.cnblogs.com/liyingning/p/7674952.html