C++基础复习
面向对象的三个基本特征是:封装、继承、多态。其中,封装可以隐藏实现细节,使得代码模块化;继承可以扩展已存在的代码模块(类);它们的目的都是为了代码重用。而多态则是为了实现接口重用。
封装
它是指对象只对外提供有限的接口,隐藏对象内部状态和实现细节。
继承
它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。其继承的过程,就是从一般到特殊的过程。
通过继承创建的新类称为“子类”或“派生类”。被继承的类称为“基类”、“父类”或“超类”。要实现继承,可以通过“继承”(Inheritance)和“组合”(Composition)来实现。
多重继承
C++允许多重继承,但是菱形继承会有二义性,需要用虚继承解决二义性问题。
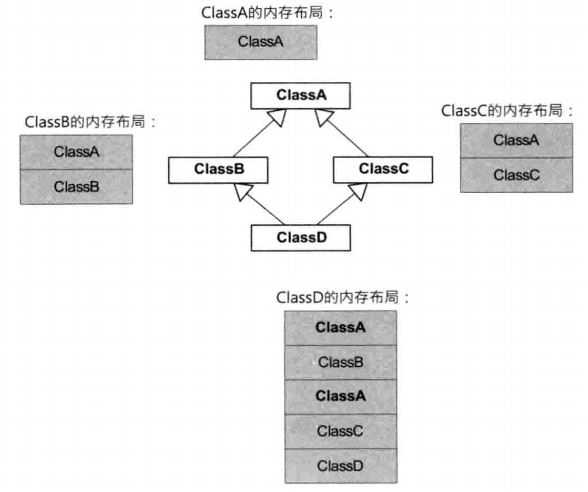
菱形继承的定义是:两个子类继承同一父类,而又有子类同时继承这两个子类。
使用虚继承消除二义性,但是虚继承的开销是增加虚函数指针。虚基类实例地址 = 派生类虚函数指针+派生类虚函数指针到虚基类实例地址的偏移量
多重继承细节参考:
多态
单一共同的接口操作一组不同类型的对象
实现多态,有二种方式。重写(使用虚函数,动态的):是指子类重新定义父类的虚函数的做法。重载(编译期间区分,静态的):是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不同,或许两者都不同)。
细节参考:
组合和聚合
继承是“is-a”的关系,而组合是“contains-a”的关系,聚合是“has-a”的关系。
关联:指的是模型元素之间的一种语义联系,是类之间的一种很弱的联系。关联可以有方向,可以是单向关联,也可以是双向关联。例如一个类的成员方法中,另一个类作为它的参数。
class A{...} class B{ ...} A::Function1(B &b) //或A::Function1(B b) //或A::Function1(B *b)
组合关系(Composition):部分和整体之间具有相同的生命周期,当整体消亡后,部分也将消亡。
class A{...} class B{ A a; ...}
聚合关系(Aggregation):部分与整体之间并没有相同的生命周期,整体消亡后部分可以独立存在。
class A {...} class B { A* a; .....}
设计模式
三种通用的设计模式:单例模式、迭代器模式、抽象工厂模式。
单例模式(singleton)
保证某个类只有一个实例,并提供该单例的全局存取方法。
迭代器模式(iterator)
提供高效存取一个集合的方法,同时不需要暴露集合的内部实现。
抽象工厂模式(abstract factory)
抽象工厂提供一个接口,创造一组相关或互相依赖的类,但是不需要指明那些类的concrete class。
详细参考:
编码标准
数据
基本数据类型的长度(32位和64位相同的):
char :1个字节
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long long: 8个字节
32位机器上的数据类型的长度:
*(指针变量): 4个字节(32位机的寻址空间是4个字节)
long: 4个字节
unsigned long: 4个字节
64位机器上的数据类型的长度:
*(指针变量): 8个字节(64位机的寻址空间是4个字节)
long: 8个字节
unsigned long: 8个字节
编译器专属特定大小类型
Visual S脱掉的C/C++编译器定义了下面的扩展关键字去大亨名特定位数的变量:__int8、__int16、__int32、__int64。
SIMD类型
游戏编程中常用的SIMD寄存器格式是4个32位IEEE-754浮点数值打包,存进128位SIMD寄存器。SIMD表示单指令多数据(single instruction,multiple data,SIMD)。
大端和小端
大端(big-endian)是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
小端(little_endian)是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中。
不同CPU有不同的字节序类型,而网络字节序统一都是大端,因此,网络地址需要先转换成网络字节序。
字节序的转换
整数字节序转换
#define U32 unsigned int #define U16 short int #define F32 float inline U16 swapU16(U16 value){ return ((value & 0x00ff) << 8) | ((value & 0xff00) >> 8);//截取前后8位,通过移位交换 } inline U32 swapU32(U32 value){ return ((value & 0x000000ff) << 24) | ((value & 0x0000ff00) << 8) | ((value & 0x00ff0000) >> 8) | ((value & 0xff000000) >> 24); }
浮点数字节序转换
union U32F32{ U32 m_asU32; F32 m_asF32; }; inline F32 swapF32(F32 value){ U32F32 u; u.m_asF32 = value;//使用union结构,将float转成int,在通过swapU32转换大端小端 u.m_asU32 = swapU32(u.m_asU32); return u.m_asF32; }
翻译单元
编译器编译一个.cpp文件生成一个object file,此时object file中可能含有为解决引用,这是因为,编译器每次操作只针对一个翻译单元,遇到为解决引用的外部变量和函数,只能学案则相信它真的存在。
而解决外部引用主要是链接器,它可能会报两种错误:
对象和函数可以有多个声明,但是只能有一个定义;
inline只是给编译器的提示,编译器会根据函数的效率等因素最终决定是否内联;因此,内联函数的实现和声明都应该在.h文件中,否则编译器只看到声明,看不到实现。
每个C/C++定义都有链接规范属性;它分为外部链接和内部链接。外部链接的定义可被定义处以外的翻译单元看见并引用;内部链接的定义只能被该定义所处的翻译单元看见。
声明不分配空间,所以没有连接属性;内联函数默认是内部链接。
内存

上图以从上到下地址递增的顺序列出,在全局数据区分为已初始化的全局变量和static数据和未初始化的BSS段
对齐
以结构体为例,内存对齐的原则如下:
1:结构体变量的首地址能被其他最宽基本类型成员的大小所整除。
2:结构体所占用的总的内存必须是其中(最大数据类型所占内存和按照#pragma pack(编译器设定的内存对齐数目)指定的数值中)较小的那个值的整数倍。
3:结构体中某个数据内存的起始地址与结构体起始地址之间的差值必须是(该数据所占内存和按照#pragma pack指定的数值中)较小的那个值的整数倍。
#pragma pack(n)作为一个预编译指令用来设置多少个字节对齐的。值得注意的是,n的缺省数值是按照编译器自身设置,一般为8,合法的数值分别是1、2、4、8、16。
即编译器只会按照1、2、4、8、16的方式分割内存。若n为其他值,是无效的。
异常
返回错误是,更好的方法是返回一个枚举类型,这样能更清楚的表示出它的状态。
抛出异常是一个解决异常错误的方法,但是异常会为程序添加许多额外的开销,每个调用帧会变大,用来承载堆栈辗转开解时所需的额外信息。并且,堆栈的辗转开解通常很慢,相比简单的返回,前者用时,大约多一两倍。而且,就算程序中仅有一两个函数使用了异常,整个程序都必须要使用。所以,在游戏引擎中有理由去完全关闭异常处理。
当断言失败时,应该总是终止整个程序;断言应该只用来捕捉严重错误。
原文:http://www.cnblogs.com/yeqluofwupheng/p/7682383.html