欢迎转载,转载请注明出处,徽沪一郎。
本文就standalone部署方式下的容错性问题做比较细致的分析,主要回答standalone部署方式下的包含哪些主要节点,当某一类节点出现问题时,系统是如何处理的。
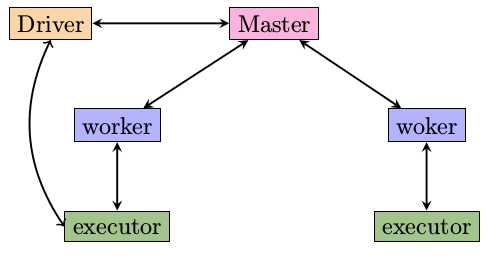
介绍Spark的资料中对于RDD这个概念涉及的比较多,但对于RDD如何运行起来,如何对应到进程和线程的,着墨的不是很多。
在实际的生产环境中,Spark总是会以集群的方式进行运行的,其中standalone的部署方式是所有集群方式中最为精简的一种,另外是Mesos和YARN,要理解其内部运行机理,显然要花更多的时间才能了解清楚。
standalone集群由三个不同级别的节点组成,分别是
这三种不同类型的节点各自运行于自己的JVM进程之中。
提交到standalone集群的应用程序称之为Driver Applicaton。
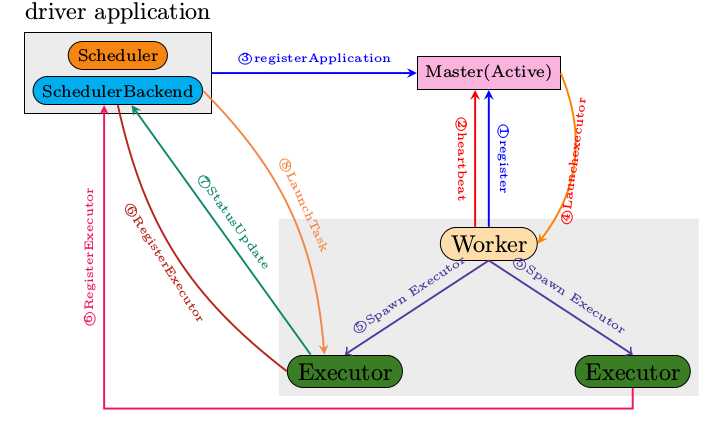
上图总结了正常情况下Standalone集群的启动以及应用提交时,各节点之间有哪些消息交互。下面分集群启动和应用提交两个过程来作详细说明。
正常启动过程如下所述
$SPARK_HOME/sbin/start-master.sh
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
worker启动之后,会做两件事情
利用如下指令来启动spark-shell
MASTER=spark://127.0.0.1:7077 $SPARK_HOME/bin/spark-shell
运行spark-shell时,会向Master发送RegisterApplication请求
日志位置: master运行产生的日志在$SPARK_HOME/logs目录下
收到RegisterApplication请求之后,Mastet会做如下处理
Worker在收到LaunchExecutor指令之后,会启动Executor进程
启动的Executor进程会根据启动时的入参,将自己注册到Driver中的SchedulerBackend
日志位置: executor的运行日志在$SPARK_HOME/work目录下
SchedulerBackend收到Executor的注册消息之后,会将提交到的Spark Job分解为多个具体的Task,然后通过LaunchTask指令将这些Task分散到各个Executor上真正的运行
如果在调用runJob的时候,没有任何的Executor注册到SchedulerBackend,相应的处理逻辑是什么呢?
任务运行结束时,会将相应的Executor停掉。
可以做如下的试验
通过上面的控制消息原语之间的先后顺序可以看出
上面说明的是正常情况下,各节点的消息分发细节。那么如果在运行中,集群中的某些节点出现了问题,整个集群是否还能够正常处理Application中的任务呢?
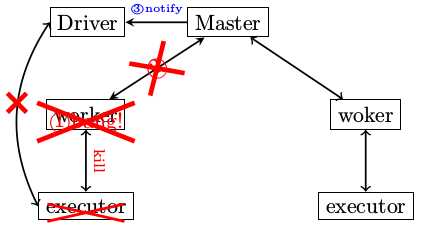
在Spark运行过程中,经常碰到的问题就是worker异常退出,当worker退出时,整个集群会有哪些故事发生呢? 请看下面的具体描述
worker异常退出会带来哪些影响
定义于ExecutorRunner.scala的start函数
def start() {
workerThread = new Thread("ExecutorRunner for " + fullId) {
override def run() { fetchAndRunExecutor() }
}
workerThread.start()
// Shutdown hook that kills actors on shutdown.
shutdownHook = new Thread() {
override def run() {
killProcess(Some("Worker shutting down"))
}
}
Runtime.getRuntime.addShutdownHook(shutdownHook)
}
killProcess的过程就是停止相应CoarseGrainedExecutorBackend的过程。
worker停止的时候,一定要先将自己启动的Executor停止掉。这是不是很像水浒中宋江的手段,李逵就是这样不明不白的把命给丢了。
需要特别指出的是,当worker在启动Executor的时候,是通过ExecutorRunner来完成的,ExecutorRunner是一个独立的线程,和Executor是一对一的关系,这很重要。Executor作为一个独立的进程在运行,但会受到ExecutorRunner的严密监控。
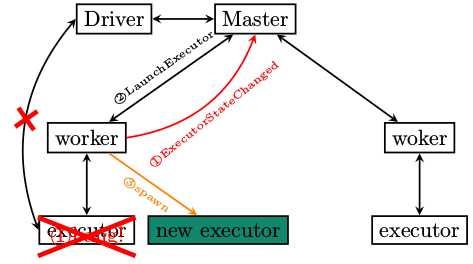
Executor作为Standalone集群部署方式下的最底层员工,一旦异常退出,其后果会是什么呢?
作为一名底层员工,想轻易摞挑子不干是不成的。"人在江湖,身不由己“啊。
fetchAndRunExecutor负责启动具体的Executor,并监控其运行状态,具体代码逻辑如下所示
def fetchAndRunExecutor() {
try {
// Create the executor‘s working directory
val executorDir = new File(workDir, appId + "/" + execId)
if (!executorDir.mkdirs()) {
throw new IOException("Failed to create directory " + executorDir)
}
// Launch the process
val command = getCommandSeq
logInfo("Launch command: " + command.mkString("\"", "\" \"", "\""))
val builder = new ProcessBuilder(command: _*).directory(executorDir)
val env = builder.environment()
for ((key, value) {
logInfo("Runner thread for executor " + fullId + " interrupted")
state = ExecutorState.KILLED
killProcess(None)
}
case e: Exception => {
logError("Error running executor", e)
state = ExecutorState.FAILED
killProcess(Some(e.toString))
}
}
}
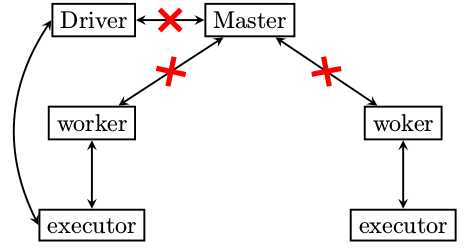
worker和executor异常退出的场景都讲到了,我们剩下最后一种情况了,master挂掉了怎么办?
带头大哥如果不在了,会是什么后果呢?
怎么样,知道后果很严重了吧?别看老大平时不干活,要真的不在,仅凭小弟们是不行的。
那么怎么解决Master单点失效的问题呢?
你说再加一个Master就是了,两个老大。两个老大如果同时具有指挥权,结果也将是灾难性的。设立一个副职人员,当目前的正职挂掉之后,副职接管。也就是同一时刻,有且只有一个active master。
注意不错,如何实现呢?使用zookeeper的ElectLeader功能,效果图如下
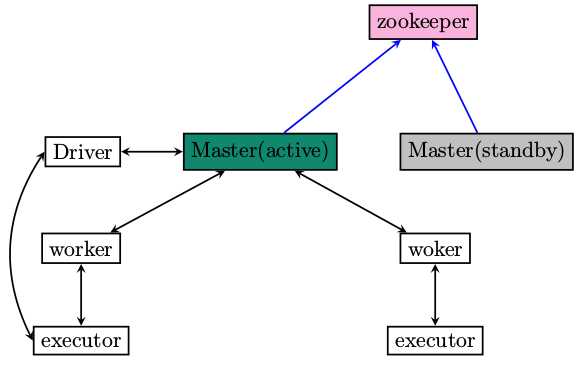
如何搭建zookeeper集群,这里不再废话,哪天有空的话再整一整,或者可以参考写的storm系列中谈到的zookeeper的集群安装步骤。
假设zookeeper集群已经设置成功,那么如何启动standalone集群中的节点呢?有哪些特别的地方?
在conf/spark-env.sh中,为SPARK_DAEMON_JAVA_OPTS添加如下选项
| System property | Meaning |
| spark.deploy.recoveryMode | Set to ZOOKEEPER to enable standby Master recovery mode (default: NONE). |
| spark.deploy.zookeeper.url | The ZooKeeper cluster url (e.g., 192.168.1.100:2181,192.168.1.101:2181). |
| spark.deploy.zookeeper.dir | The directory in ZooKeeper to store recovery state (default: /spark). |
设置SPARK_DAEMON_JAVA_OPTS的实际例子
SPARK_DAEMON_JAVA_OPTS="$SPARK_DAEMON_JAVA_OPTS -Dspark.deploy.recoveryMode=ZOOKEEPER"
应用程序运行的时候,指定多个master地址,用逗号分开,如下所示
MASTER=spark://192.168.100.101:7077,spark://192.168.100.102:7077 bin/spark-shell
Standalone集群部署方式下的容错性分析让我们对于Spark的任务分发过程又有了进一处的认识。前面的篇章从整体上匆匆过了一遍Spark所涉及的知识点,分析的不够深,不够细。
此篇尝试着就某一具体问题做深入的分析。套用书画中的说法,在框架分析的时候,我们可以”大开大合,疏可走马,计白当黑“,在细节分析的时候,又要做到“密不透风,条分缕析,层层递进”。
Apache Spark源码走读之15 -- Standalone部署模式下的容错性分析,布布扣,bubuko.com
Apache Spark源码走读之15 -- Standalone部署模式下的容错性分析
原文:http://www.cnblogs.com/downtjs/p/3815325.html