一、实验目的
1.熟悉体系结构的风格的概念
2.理解和应用管道过滤器型的风格。
3、理解解释器的原理
4、理解编译器模型
二、实验环境
硬件:
软件:Python或任何一种自己喜欢的语言
三、实验内容
1、实现“四则运算”的简易翻译器。
结果要求:
1)实现加减乘除四则运算,允许同时又多个操作数,如:2+3*5-6 结果是11
2)被操作数为整数,整数可以有多位
3)处理空格
4)输入错误显示错误提示,并返回命令状态“CALC”
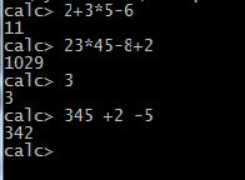
图1 实验结果示例
加强练习:
1、有能力的同学,可以尝试实现赋值语句,例如x=2+3*5-6,返回x=11。(注意:要实现解释器的功能,而不是只是显示)
2、尝试实现自增和自减符号,例如x++
2、采用管道-过滤器(Pipes and Filters)风格实现解释器
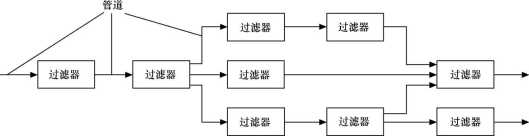
图2 管道-过滤器风格
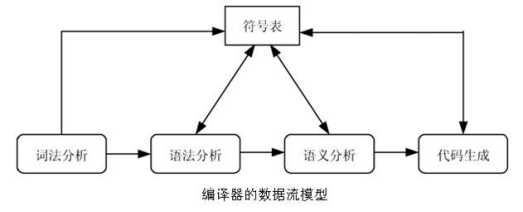
图 3 编译器模型示意图
本实验,实现的是词法分析和语法分析两个部分。
四、实验步骤:
要求写具体实现代码,并根据实际程序,画出程序的总体体系结构图和算法结构图。
总体结构图参照体系结构风格。
算法结构图参照如下:
源代码:
1 INTEGER,PLUS,MINUS,MUL,DIV,LPAREN,RPAREN,EOF=( 2 ‘INTEGER‘,‘PLUS‘,‘MINUS‘,‘MUL‘,‘DIV‘,‘LPAREN‘,‘RPAREN‘,‘EOF‘) 3 4 class Token(object): 5 def __init__(self,type,value): 6 self.type=type 7 self.value=value 8 def __str__(self): 9 return ‘Token({type},{value})‘.format( 10 type=self.type, 11 value=self.value 12 ) 13 14 class Lexer(object): 15 #词法分析器 16 #给每个词打标记 17 def __init__(self,text): 18 self.text=text 19 self.pos=0 20 self.current_char=self.text[self.pos] 21 22 23 def error(self): 24 raise Exception(‘Invalid Char‘) 25 26 def advance(self): 27 #往下走,取值 28 self.pos+=1 29 if self.pos>len(self.text)-1: 30 self.current_char=None 31 else: 32 self.current_char=self.text[self.pos] 33 34 def integer(self): 35 #多位整数处理 36 result=‘‘ 37 while self.current_char is not None and self.current_char.isdigit(): 38 result=result+self.current_char 39 #往下走,取值 40 self.advance() 41 return int(result) 42 def deal_space(self): 43 while self.current_char is not None and self.current_char.isspace(): 44 self.advance() 45 46 def get_next_token(self): 47 #打标记:1)pos+1,2)返回Token(类型,数值) 48 while self.current_char is not None: 49 if self.current_char.isspace(): 50 self.deal_space() 51 52 if self.current_char.isdigit(): 53 return Token(INTEGER,self.integer()) 54 if self.current_char==‘+‘: 55 self.advance() 56 return Token(PLUS,‘+‘) 57 if self.current_char==‘-‘: 58 self.advance() 59 return Token(MINUS,‘-‘) 60 if self.current_char==‘*‘: 61 self.advance() 62 return Token(MUL,‘*‘) 63 if self.current_char==‘/‘: 64 self.advance() 65 return Token(DIV,‘/‘) 66 if self.current_char==‘(‘: 67 self.advance() 68 return Token(LPAREN,‘(‘) 69 if self.current_char==‘)‘: 70 self.advance() 71 return Token(RPAREN,‘)‘) 72 self.error() 73 return Token(EOF,None) 74 75 76 class Interpreter(object): 77 #句法分析 78 #语法树 79 def __init__(self,lexer): 80 self.lexer=lexer 81 self.current_token=self.lexer.get_next_token() 82 def error(self): 83 raise Exception(‘Invalid Syntax‘) 84 85 def eat(self,token_type): 86 if self.current_token.type==token_type: 87 self.current_token=self.lexer.get_next_token() 88 else: 89 self.error() 90 def factor(self): 91 token=self.current_token 92 if token.type==INTEGER: 93 self.eat(INTEGER) 94 return token.value 95 elif token.type==LPAREN: 96 self.eat(LPAREN) 97 result=self.expr() 98 self.eat(RPAREN) 99 return result 100 101 def term(self): 102 result=self.factor() 103 while self.current_token.type in (MUL,DIV): 104 token=self.current_token 105 if token.type==MUL: 106 self.eat(MUL) 107 result=result*self.factor() 108 if token.type==DIV: 109 self.eat(DIV) 110 result=result/self.factor() 111 return result 112 def expr(self): 113 result=self.term() 114 while self.current_token.type in (PLUS,MINUS): 115 token=self.current_token 116 if token.type==PLUS: 117 self.eat(PLUS) 118 result=result+self.term() 119 if token.type==MINUS: 120 self.eat(MINUS) 121 result=result-self.term() 122 return result 123 124 125 126 127 def main(): 128 while True: 129 try: 130 text=input(‘calc_> ‘) 131 except EOFError: 132 break 133 if not text: 134 continue 135 lexer=Lexer(text) 136 result=Interpreter(lexer).expr() 137 print(result) 138 139 if __name__==‘__main__‘: 140 main()
截图:
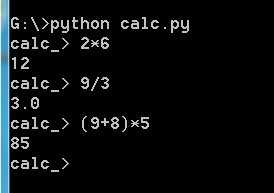
原文:http://www.cnblogs.com/izhangyu/p/7748490.html