ResNet网络,本文获得2016 CVPR best paper,获得了ILSVRC2015的分类任务第一名。
本篇文章解决了深度神经网络中产生的退化问题(degradation problem)。什么是退化问题呢?如下图:
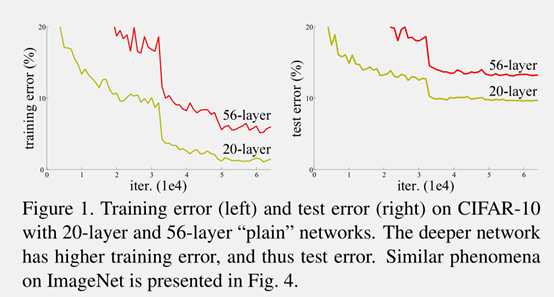
上图所示,网络随着深度的增加(从20层增加到56层),训练误差和测试误差非但没有降低,反而变大了。然而这种问题的出现并不是因为过拟合(overfitting)。
照理来说,如果我们有一个浅层的网络,然后我们可以构造一个这样的深层的网络:前面一部分的网络和浅层网络一模一样,后面一部分的网络采用恒等映射(identity mapping),那么,深层网络的产生的误差至少不会比浅层网络的高。但是目前却不能找到一个更好的方法比用刚才的方法构造的网络效果要好。
于是,作者就提出了deep residual learning framework。结构如下:
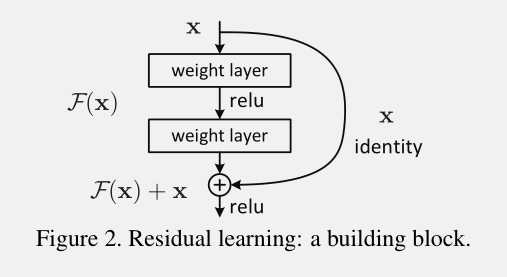
其实就是在原来网络的基础上,每隔2层(或者3层,或者更多,这篇文章作者只做了2层和3层)的输出F(x)上再加上之前的输入x。这样做,不会增加额外的参数和计算复杂度,整个网络也可以用SGD方法进行端对端的训练,用目前流行的深度学习库(caffe等)也可以很容易的实现。
这种网络的优点有:
1) 更容易优化(easier to optimize)
2) can gain accuracy from increased depth,即能够做到网络越深,准确率越高
对于作者提出的网络结构,有2种情形。
1) 当F和x相同维度时,直接相加,公式如下:
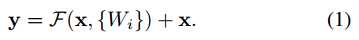
这种方法不会增加网络的参数以及计算复杂度。
2) 当F和x维度不同时,需要先将x做一个变换,然后再相加,公式如下:
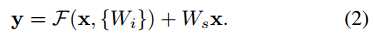
Ws仅仅用于维度匹配上。
对于x的维度变换,一种是zero-padding,另一种是通过1x1的卷积。
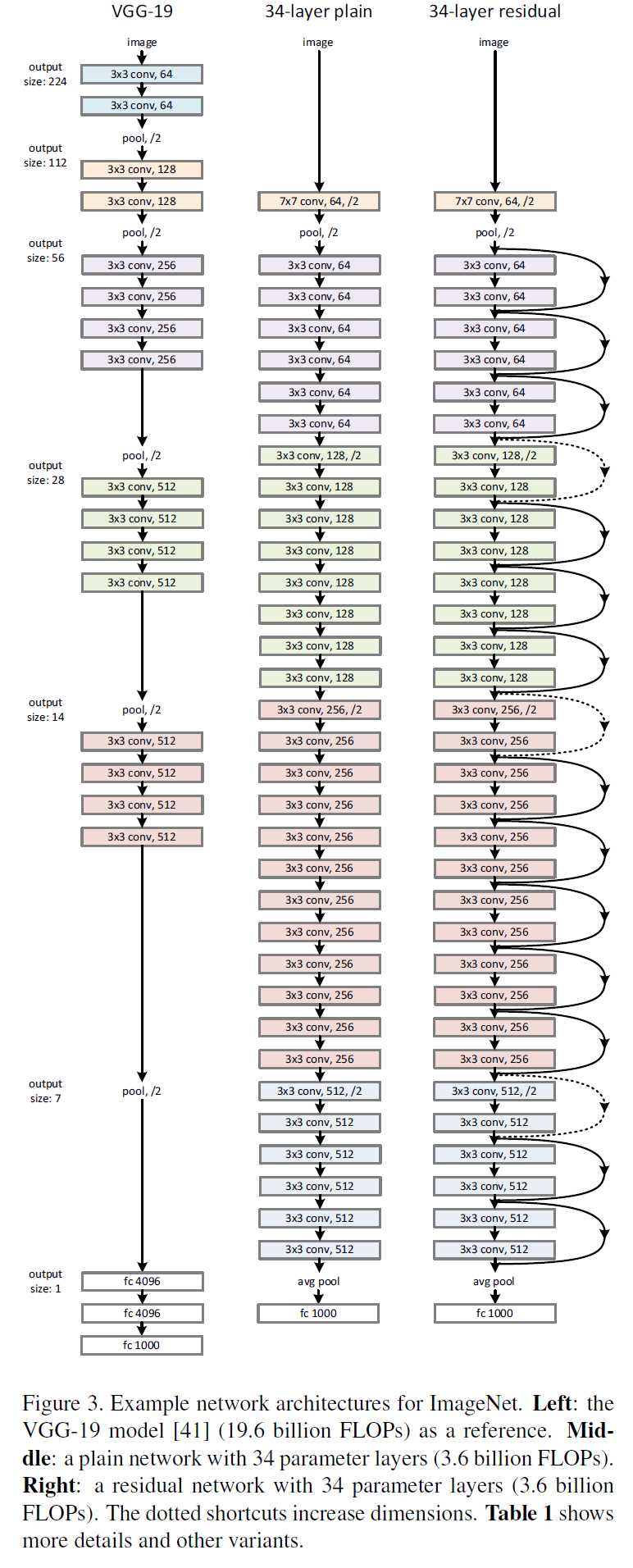
网络结构
测试网络如下:
基准网络为:基于VGGNet,采用的卷积核为3x3,其中有两个设计原则,1)对于有相同的输出feature map尺寸,filter的个数相同;2)当feature map尺寸减半时,filter的数量加倍。下采样的策略是直接用stride=2的卷积核。网络最后末尾是一个global average pooling layer(不需要参数,参考http://www.cnblogs.com/hejunlin1992/articles/7750759.html)和一个1000的全连接层(后面接softmax)。
残差网络为:在基准网络的基础上,插入了shortcut connections。当输入输出具有相同尺寸时,identity shortcuts可以直接使用(实线部分),就是公式1;当维度增加时(虚线部分),有以下两种选择:A)仍然采用恒等映射(identity mapping),超出部分的维度使用0填充;B) 利用1x1卷积核来匹配维度,就是公式2。对于上面两种方案,当shortcuts通过两种大小的feature map时,采取A或B方案的同时,stride=2。
实现细节:
Our implementation for ImageNet follows the practice in [21, 41]. The image is resized with its shorter side randomly sampled in [256, 480] for scale augmentation [41]. A 224×224 crop is randomly sampled from an image or its horizontal flip, with the per-pixel mean subtracted [21]. The standard color augmentation in [21] is used. We adopt batch normalization (BN) [16] right after each convolution and before activation, following [16]. We initialize the weights as in [13] and train all plain/residual nets from scratch. We use SGD with a mini-batch size of 256. The learning rate starts from 0.1 and is divided by 10 when the error plateaus, and the models are trained for up to 60 × 104 iterations. We use a weight decay of 0.0001 and a momentum of 0.9. We do not use dropout [14], following the practice in [16]. In testing, for comparison studies we adopt the standard 10-crop testing [21]. For best results, we adopt the fullyconvolutional form as in [41, 13], and average the scores at multiple scales (images are resized such that the shorter side is in {224, 256, 384, 480, 640}).
实验
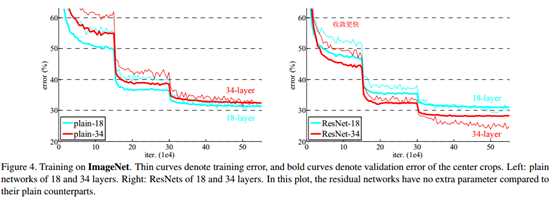
从上图左边,可以看出,plain-34网络不管是训练误差还是验证集上的误差,都要比plain-18要大,由于plain网络采用了BN来训练,并且作者也验证过前向传播或者反向传播中,信号并没有消失,因此说明出现了退化现象(到底为什么会出现这种情况,作者也还在研究之中)。
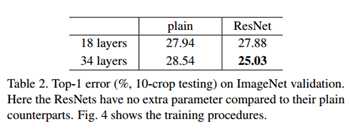
再看上图右边的残差网络,结合下面的表2,34层的resNet比18层的resNet在训练集和验证集上的误差都要小,说明并没有出现退化现象。34层的resNet与34层的plain网络相比,误差减少了3.5%,说明在深度网络中残差学习是有效的。另外,18层的ResNet与18层的plain网络相比,18层的ResNet训练更快了。
Identity vs. Projection Shortcuts.
上面展示了,恒等映射(identity shortcuts)可以帮助训练。下面我们测试一下projection shortcuts(公式2)的效果。有3种测试方案。A)当维度增加时,使用zero-padding shortcuts,这些所有的shortcuts是没有参数的(与Table2和Fig4右侧的图一致);B) projection shortcuts只用于维度增加的情况,其他情况(输入输出维度一致时)还是使用恒等映射(即公式1);C)所有的shortcus都是projection(即公式2)。测试结果如下表:
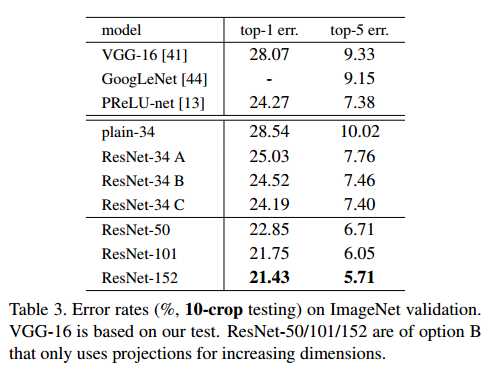
从上表中可以看出,方案A,B和C的效果都要比plain-34要好。B比A稍微好一点,这是因为A的用零填充的那几个维度没有进行残差学习。C要B好的多,这是因为引入了额外的参数。但是总体上A,B和C的差别还是比较小的,说明projection shortcuts在解决退化问题中并不是十分重要。因此,为了减少参数和计算量,我们在这篇文章中不使用方案C。
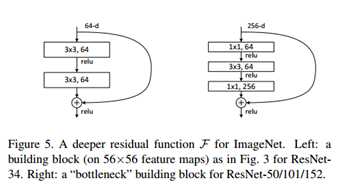
Deeper Bottleneck Architectures
下面描述用于ImageNet的更深的网络结构。考虑到训练时间,我们将下图中左侧的网络改成右侧的网络。1x1的卷积的作用是减少和增加(恢复)维度,使得3x3的卷积核的个数可以减少。
50-layer ResNet
将34层中的每个2-layer block替换为3-layer bottleneck block,就得到了一个50层的ResNet。我们使用B方案来增加维度。
101-layer and 152-layer ResNets
我们使用更多的3-layer bottleneck block,就得到了101层和152层的ResNet。152层的网络深度很深,但是参数量却比VGG16/19要小。
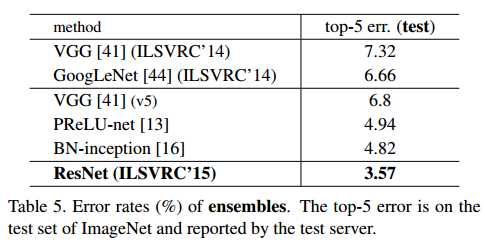
模型之间的比对
如下图所示,下图中的ResNet是使用多个不同深度的ResNet,综合结果而成的,效果非常好。
[论文阅读] Deep Residual Learning for Image Recognition(ResNet)
原文:http://www.cnblogs.com/hejunlin1992/p/7751516.html