一般用户用CLI(命令行界面)接口,元数据库含有表结构

单用户、多用户、远程服务
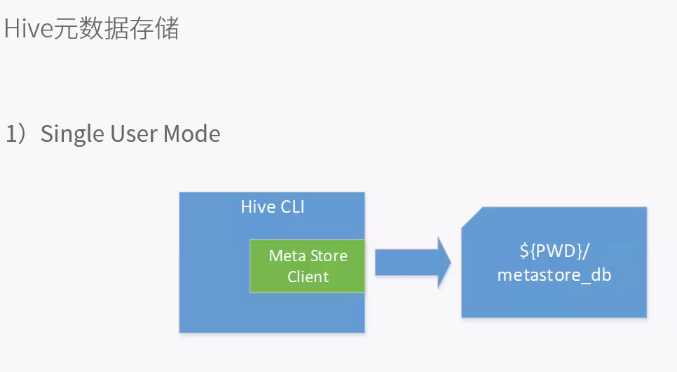
生成db文件,只能单客户端使用数据库

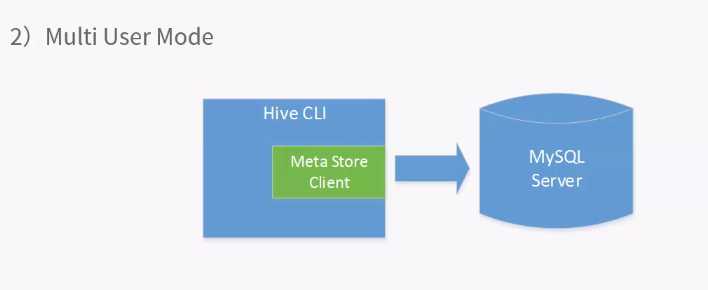
多用户是最常用的使用模式

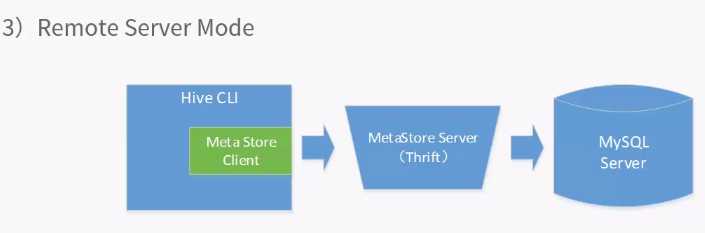
配置与多用户一致

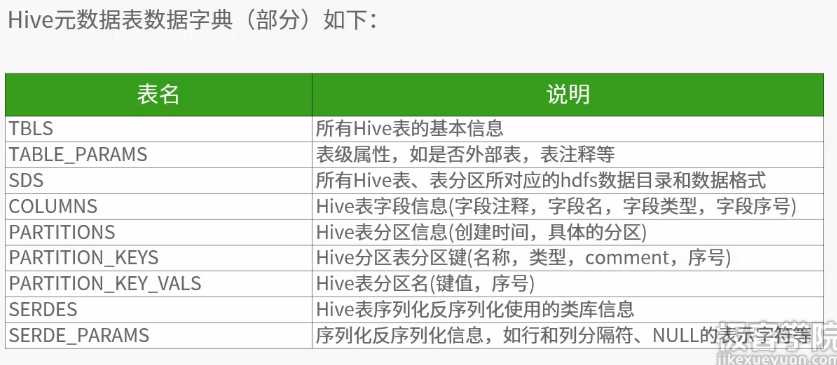

数据格式用户自定义


所有的表都存于改配置路径下,除了外部表



外部表指定location则可,删除一个表只会删除元数据(元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能),表中的数据不会删除

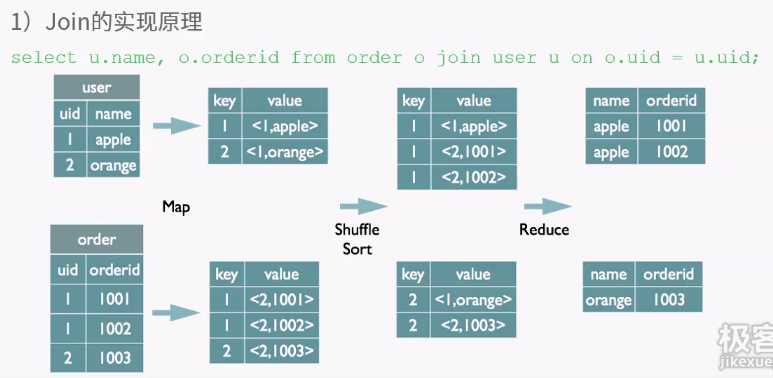
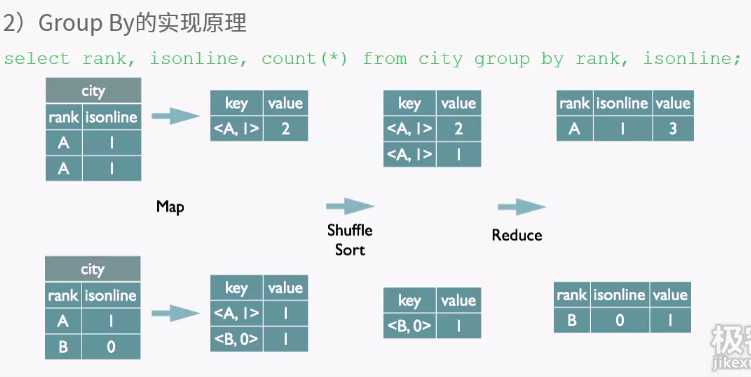
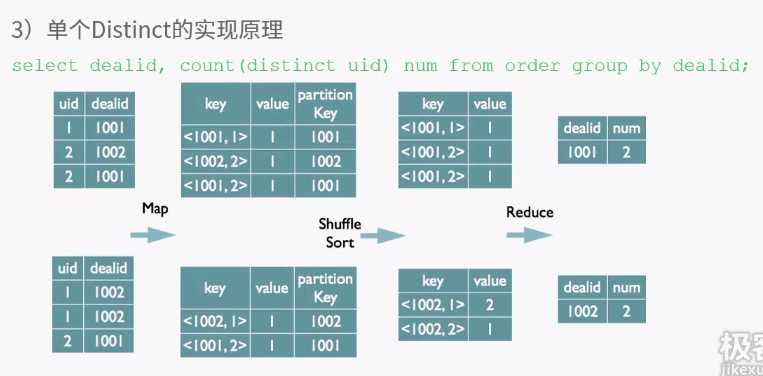

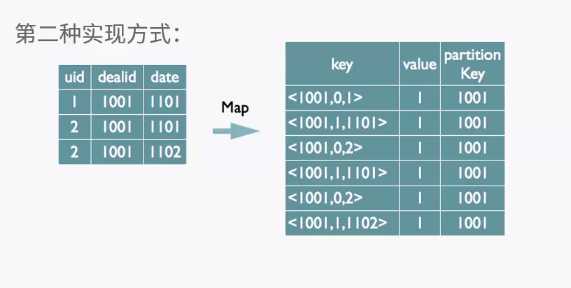
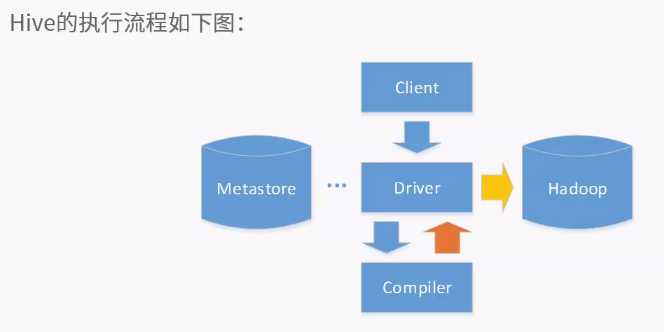
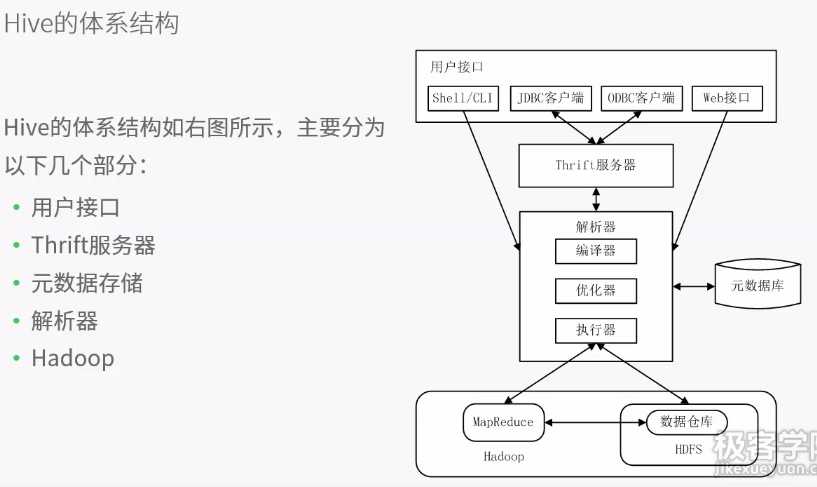
客户端提供查询语序,给hive,hive交给driver处理,分为四步
1.编译机编译,从metastore中获取元数据,生成逻辑计划
2.执行物理计划
3.Driver进行优化
4.执行器执行时对物理计划分解为job,并提交给jobtracker,

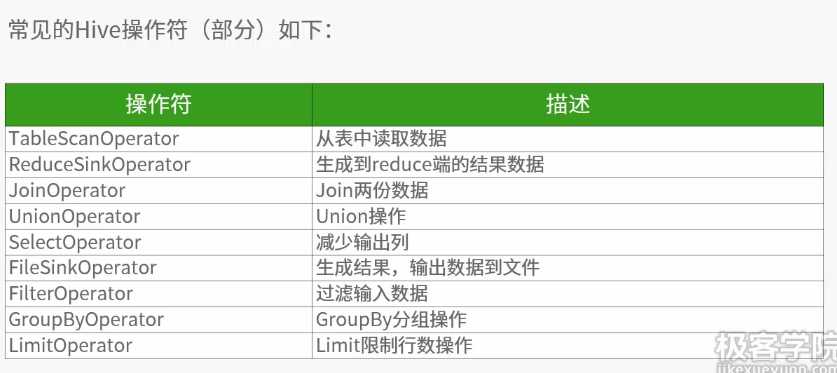
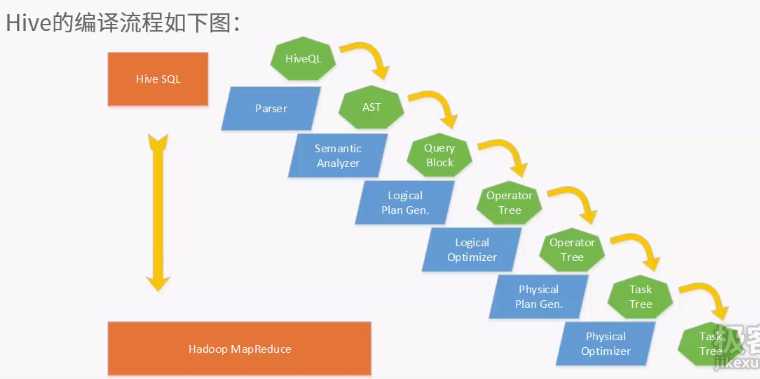
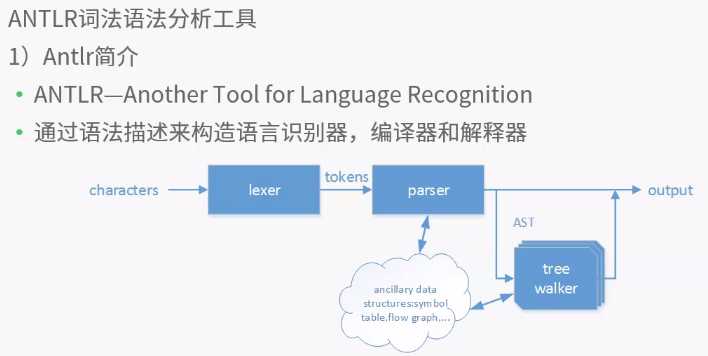


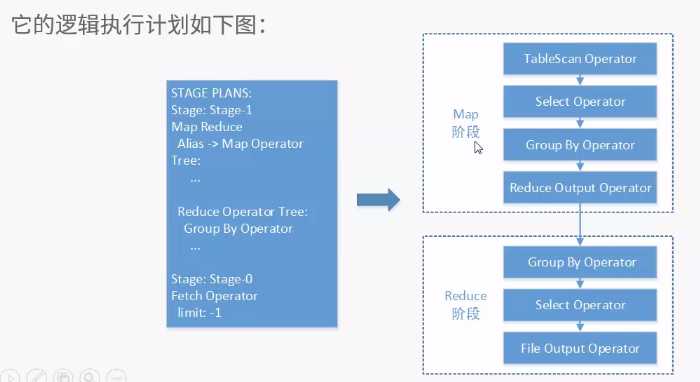
原文:http://www.cnblogs.com/liuxiaopang/p/7792888.html