既然有了Ashx,为什么还要有Aspx?
如果每次输出网页都 一般处理程序(ashx) 的话太痛苦了,所以一般生成html的时候都直接创建aspx(Web窗体,WebForm) WebForm分为两个文件aspx和aspx.cs,aspx是页面模板,是页面描述文件,就是html+js+css的内容,和aspx.cs结合的更好,不用像一般处理程序那样程序员自己去输出HTML字符串或读取填充模板,控件都是定义在aspx中,内联的JavaScript、CSS也是写在aspx中的,服务端的C#代码是定义在aspx.cs中。aspx控制页面长相,cs控制程序逻辑,这种“前aspx后cs”的方式就被称为CodeBehind(代码后置-为什么要后置?)。 浏览器如果报错“***行错误”(js脚本错误),不要看aspx,要看生成的源代码。
WebForm
cs可以调用aspx中的runat=server的控件(根本原因),aspx中也可以访问cs中定义的字段、函数,还可以编写复杂的C#代码, for等所有C#代码都可以写在aspx中(不推荐) 前面 <%=UserName %> <%=SayHello(); %> <%if (UserName == "aaa") { UserName = "bbb"; } %> 后面 在当前位置输出表达式的值的时候使用<%=UserName %>,不要丢了=,相当于在当前位置调用Response.Write(UserName) 使用的函数、代码相当于在这个位置调用函数、执行代码。注意aspx中调用cs的只能是非私有成员(非private修饰-因为继承关系) <%%>中的代码是运行在服务器端的,是C#语法,在服务端运行完成才输出到浏览器,其他部分是运行在浏览器端的,是html、JavaScript语法。
为什么cs可以调用aspx中的控件原因:
在编译之后,前台文件中的所有runat=server的html标签控件都会在生成的后台文件类中产生一个对应的 HTML服务器端控件(protected HtmlGenericControl div1; ) 对象,而且所有的 服务器端控件标签(<ASP:Button/>) 都也会在后台文件类生成 对应的 服务器端控件(protected Button Button1; ) 对象。
为什么aspx中也可以访问cs中定义的非私有成员:因为aspx所编译生成的类集成了cs类
aspx、cs、dll之间的关系(*)
聊、考CodeBehind的时候可以顺带吹的点。
在WebForm的页面中执行下面的代码
Response.Write(this.GetType() + "<br/>"); Response.Write(this.GetType().Assembly.Location + "<br/>");
发现当前执行页面的类名是ASP.webform1_aspx这样的类名,父类才是ASPNETTest1.WebForm1 使用Reflector打开这个临时dll,反编译这两个类,发现ASPNETTest1.WebForm1是在VS中编写的aspx.cs类,而ASP.webform1_aspx则是一个继承自ASPNETTest1.WebForm1的子类,ASP.webform1_aspx代码是根据aspx内容动态生成的构建网页内容的类。
综上,aspx最终也会生成一个类,这个类是继承自aspx.cs中的类。查看反编译以后的代码,可以看到就是编译生成了普通的.Net 代码。因为aspx生成的代码是cs类的子类,所以就明白了为什么“aspx中调用cs的成员级别必须是protected或者public,不能是private的。”
aspx和ashx
aspx和ashx关系:aspx就是一个特殊的ashx,微软在aspx中帮我们封装了很多操作,我们可以“傻瓜”化的进行开发。 aspx和JavaScript和css混合写。
aspx是什么。 aspx的文件路径中不能有“#”符号的bug。
登录流程
用户打开登录页面,填入用户名密码,点击【登录】按钮,浏览器将用户输入的用户名、密码发送给网站服务器,网站服务器让负责处理登录请求的ASP.Net程序来处理这个登录请求,处理程序判断用户名、密码是否正确,然后将判断结果返回给浏览器。
开发一个登录页面需要做两个工作:
1.显示在浏览器中的页面、Dom特效,和C#代码没关系,也就是前端(前台)页面,相当于这个页面要生成的HTML代码模板;
2.处理浏览器请求的服务器端代码,C#代码,也就是后台代码。

练习
练习:做一个加法计算器
步骤:
1.新建网站
2.添加新建项->Web窗体(Cul.aspx)
3.打开Cul.aspx,进入设计视图,从工具栏选择html控件拖入到页面适当的位置(可以使用适当的HTML代码布局--Table)
5.在Form_Load事件中编写代码
Request其它成员
1、Request.UrlReferrer 请求的来源,可以根据这个判断从百度搜的哪个关键词、防下载盗链、防图片盗链,可以伪造(比如迅雷)。"本图片仅供如鹏网内部交流使用",在DZ中测试。全局防盗链用Globals.asax
2、Request.UserHostAddress获得访问者的IP地址
3、Request.Cookies 获取浏览器发过来的浏览器端的Cookie,从它里面读取Cookie值,比如context.Request.Cookies["mysessionid"],使用Request.Cookies 的时候只是读取,将Cookie写回浏览器要用Response.Cookies
4、Request.MapPath(virtulPath)将虚拟路径转换为磁盘上的物理路径,Request.MapPath("~/a/b.aspx")就会得到D:\2008\WebSites\WebSite4\a\b.aspx
1、 (*) Request.AppRelativeCurrentExecutionFilePath,获取当前执行请求相对于应用根目录的虚拟路径,以~开头,比如“~/Handler.ashx”,
2、 (*) Request.PhysicalApplicationPath,获取当前应用的物理路径,比如D:\我的文档\Visual Studio 2008\WebSites\WebSite4\
3、 (*) Request.PhysicalPath,获取当前请求的物理路径,比如D:\我的文档\Visual Studio 2008\WebSites\WebSite4\Handler.ashx
4、 (*) Request.RawUrl获得原始请求URL、Request.Url获得请求的URL,区别涉及到URL重写的问题
5、 (*) Request.UserLanguages获得访问者浏览器支持的语言,可以通过这个实现对不同语言的人显示不同语言的页面。
Response其它成员
响应的缓冲输出:为了提高服务器的性能,ASP.Net向浏览器Write的时候默认并不会每Write一次都会立即输出到浏览器,而是会缓存数据,到合适的时机或者响应结束才会将缓冲区中的数据一起发送到浏览器。
Response对象的主要成员:
1、Response.Buffer、Response.BufferOutput:经过Reflector反编译,发现两个属性是一样的,Buffer内部就是调用的BufferOutput。这个属性用来控制是否采用响应缓存,默认是true。
2、Response.Flush()将缓冲区中的数据发送给浏览器。这在需要将Write出来的内容立即输出到浏览器的场合非常适用。
案例:大批量数据的导入,显示正在导入第*条数据,用Thread.Sleep模拟耗时。
3、Response.Clear()清空缓存区中的数据,这样在缓存区中的没有发送到浏览器端的数据被清空,不会被发送到浏览器。
4、Response.ContentEncoding输出流的编码。
5、Response.ContentType 输出流的内容类型,比如是html(text/html)还是普通文本(text/plain)还是JPEG图片(image/JPEG)。
context.Response.ContentType = "text/html"; for (int i = 0; i < 20; i++) { System.Threading.Thread.Sleep(500); context.Response.Write("第"+i+"步执行完成!<br/>"); context.Response.Flush(); }
6、Response.Cookies 返回给浏览器的Cookie的集合,可以通过它设置Cookie
7、Response.OutputStream 输出流,在输出图片、Excel文件等非文本内容的时候要使用它
8、Response.End() 终止响应,将之前缓存中的数据发给浏览器,End()之后的代码不会被继续执行,End方法里调用了Flush()方法。在终止一些非法请求的时候,比如盗链等可以用End()立即终止请求。
9、Response.Redirect(url) 重定向浏览器到新的网址。即可以重定向到站外网址也可以重定向到站内网址。Response.Redirect("http://www.rupeng.com")、Response.Redirect("a.htm")。Redirect是向浏览器发回302重定向(还有一个Location告诉浏览器要重定向到哪个页面),是通知浏览器“请重新访问url这个网址”,这个过程经历了服务器通知浏览器“请重新访问url这个网址”和浏览器接到命令访问新网址的过程。
使用HttpWatch查看整个响应过程的Http报文。用Redirect因为是浏览器自己去重新访问新网址的,所以在地址栏中是可以看到网址的变化的。后面会用来防止刷新浏览器时提示“重试”。
10、Response.SetCookie(HttpCookie cookie),向输出流中更新写到浏览器中的Cookie,如果Cookie存在就更新不存在就增加。是对Response.Cookies的简化调用。
11、Response.Write()向浏览器输出内容。
Server 属性
Server属性是HttpServerUtility的一个实例,它提供对服务器上的方法和属性的访问。
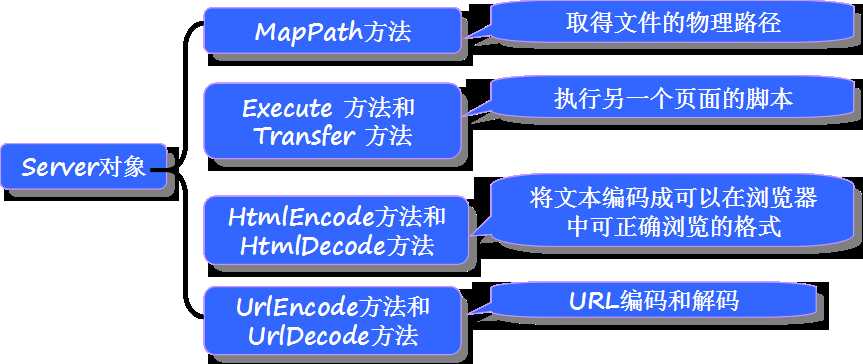
Transfer:第一个页面直接调用第二个页面,执行完第二个页面后不再返回第一个页面,立即响应到客户端浏览器。
Execute:第一个页面直接调用第二个页面,执行完第二个页面后再返回第一个页面执行,最后响应到客户端浏览器。
Server(HttpServerUtility)
Server是上下文对象context的一个属性,是HttpServerUtility类的一个对象
Server.HtmlDecode()、Server.HtmlEncode() Server.UrlEncode()、 Server.UrlDecode()是对HttpUtility类中相应方法的一个代理调用。推荐总是使用HttpUtility,因为有的地方很难拿到Server对象,而且Server的存在是为以前ASP程序员习惯而留的。别把HtmlEncode、UrlEncode混了,UrlEncode是处理超链接中的中文问题, HtmlEncode是处理html代码的。还是推荐用HttpUtility.HtmlEncode。
Server.Transfer(path) 内部重定向请求,Server.Transfer(“JieBanRen.aspx”)将用户的请求重定向给JieBanRen.aspx处理,是服务器内部的接管(不能重定向到外部网站),浏览器是意识不到这个接管的,不是象Response.Redirect那样经历“通知浏览器‘请重新访问url这个网址’和浏览器接到命令访问新网址的过程”,是一次http请求,因此浏览器地址栏不会变化。
因为是内部接管,所以在被重定向到的页面中是可以访问到Request、Cookies等这些来源页面接受的参数的,就像这些参数是传递给他的,而Redirect则不行,因为是让浏览器去访问的。
注意Transfer是内部接管,因此不能像Redirect那样重定向到外部网站。 (常考)Response.Redirect就可以重定向到外部网站。 使用Server.Transfer不能直接重定向到ashx,否则会报错“执行子请求出错”. 有的时候不能拿到HttpContext对象,比如在Global.asax中(后面讲),可以通过HttpContext.Current拿到当前的HttpContext,进而拿到Response/Request/Server等 Server.MapPath。
无状态Http
无状态的根本原因是:浏览器和服务器使用Socket通信,服务器将请求结果返回给浏览器后,会关闭当前Socket连接。而且服务器会在处理页面完毕后销毁页面对象。
应用层面的原因是:浏览器和服务器之间通信都遵守HTTP协议。
一个浏览者发出的请求都是由实现了IHttpHandler接口的对象进行响应,由于下次访问不一定还是上次那个对象进行响应,上次响应完毕对象可能已经被销毁了,写的类变量值早就不存在了,因此不要将状态信息保存到类变量中。
编写一个ashx
private int i;
public void ProcessRequest(HttpContext context)
{
context.Response.ContentType = "text/plain";
context.Response.Write(i++);
}
多次刷新我们发现,变量根本不会记忆上次的值。
为什么 aspx和一般处理程序 都必须实现 IHttpHandler接口?
因为服务器 不知道用户会编写什么样的类,类里面会编写什么方法;
所以微软就规定,凡是可以被外部请求访问的类,必须实现IHttpHandler接口;
一旦用户编写的类实现了此接口,就一定会包含接口中的ProcessRequest方法,那么服务器就可以统一调用了。
Http协议是无状态的,不会记得上次和网页“发生了什么”(故事:24小时记忆)。服务器不记得上次给了浏览器什么。
对网站造成的影响:如果用户录入了一些信息,当跳转到下一个页面时,数据丢失,再也不能获得那些数据。
如果要知道上一次的状态信息,我们就得把这个状态信息记录在某个地方:
a.服务器端
b.浏览器端
c. 表单元素中—如:隐藏域<input type=“hidden”/>(Http报文)
画图.思考:如果要保持用户登录状态怎么办?
如果用户录入了一些信息,当跳转到下一个页面时,数据丢失,再也不能获得那些数据。 通过问题引出状态保持。
ASP.NET中的状态(信息)保持方案
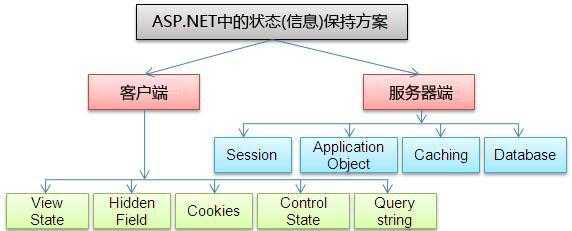
客户端的状态保持方案:ViewState、隐藏域、Cookies、控件状态、URL查询参数
服务端的状态保持方案:Session(会话)、Application、Caching(缓存)、DataBase(数据库)
常用的状态(信息)保持方式(重点)
ViewState:
ASP.NET 的 .aspx页面特有,页面级的; 就是在页面上的一个隐藏域中保存客户端单独使用的数据的一种方式; 服务器端控件的值都自动保存在ViewState中;
Cookie:
HTTP协议下的一种方式,通过该方式,服务器或脚本能够在客户机上维护状态信息; 就是在客户端保存客户端单独使用的数据的一种方式; 就像你的病历本一样,医院直接给你带回家;
Session:和进程相关。
在服务器端保存客户端单独使用的数据的一种方式; 就像银行账户,钱都存在银行里,你就拿一张银行卡回家;
Application: 在服务器端保存共享数据的一种方式; 就像银行的单人公共卫生间,谁进去都行,但一次去一个,进去了就锁上门,出来再把锁打开;
ViewState(页面级)
使用方式: 作用域---页面级
保存数据方式:
ViewState["myKey"]="MyData";
读取数据方式:
String myData;
if(ViewState["myKey"]!=null)
{
myData=(string)ViewState["myKey"];
}
ViewState不能存储所有的数据类型,仅支持: String、Integer、Boolean、Array、ArrayList、Hashtable
使用ViewState的前提:
页面上必须有一个服务器端窗体标记(<form runat=“server”>)
服务器在接收到用户请求一个页面后,会自动在请求报文中找看是否包含__VIEWSTATE的隐藏域,如果有,则将中间的值解码后添加到页面的ViewState属性中。
服务器在输出的时候,也会自动的将ViewState中的值添加到表单里名叫__VIEWSTATE的隐藏域中。
VIEWSTATE适用于同一个页面在不关闭的情况下多次与服务器交互 跨页面提交的__VIEWSTATE不会被目标页面装入页面的ViewState属性中
缺点:加大网站的流量、降低访问速度、机密数据放到表单中会有数据欺骗等安全性问题。
故事:自行打印存折,因为余额不是写到存折这个隐藏字段中的,唯一的关联就是卡号。要把机密数据放到服务器,并且区别不同的访问者的私密区域,那么就要一个唯一的标识。
ViewState图
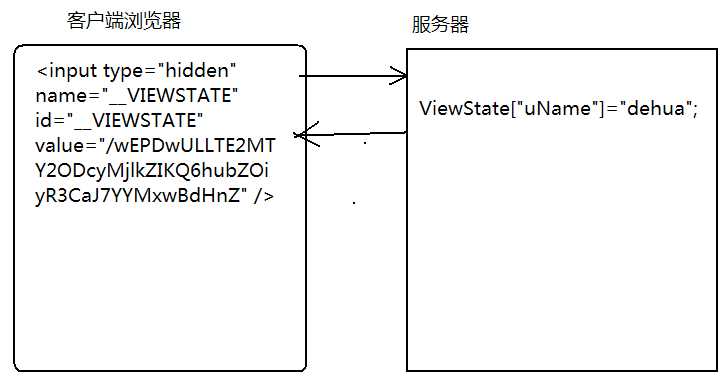
服务器将ViewState里保存的值经过Base64编码后,自动添加到页面的隐藏域中。
使用ViewState可以方便的在服务器端将数据输出保存到客户端页面的一个隐藏域中
Aspx里的ViewState初探(重点,常考)
查看生成的源代码,ASP.Net将所有隐藏内容统一放到了名字为__VIEWSTATE的隐藏字段中,使用序列化算法将所有隐藏内容放到一个字符串中。
点击几次在使用ViewStateDecoder这个工具查看ViewState内容,发现了确实将这些改变的内容放到了ViewState中。存储非表单域、非value值的容器。
禁用ViewState的方法,禁用单个控件的ViewState设定enableviewstate=false,禁用ViewState以后TextBox版本不受影响,Div版本受影响,因为input的value不依靠ViewState。
禁用整个页面的,在aspx的Page指令区加上EnableViewState="false" 。内网系统、互联网的后台可以尽情的用ViewState。 回答ViewState原理的时候:说Input版本(TextBox)自增和Div版本(Label)的不同。(完美!!!)
-- 当某些控件的某些属性不属于浏览器表单的提交范围时,fw将会把这些属性添加到ViewState中保存。 WebForm的IsPostBack依赖于ViewState
Response.Write("Label2的值是:"+Label2.Text+"<br/>");//禁用了ViewState就读不到上次给客户端的值
Label2.Text = "100";//即使禁用ViewState,写入到浏览器中的值不会受影响
Response.Write("Label2的值是2:" + Label2.Text + "<br/>");//即使禁用ViewState在请求没有结束之前也能读出来设置的值
Cookie(小甜饼)—病历本
Cookie是一种能够让网站服务器把少量数据(4kb左右)储存到客户端的硬盘或内存,并且读取出来的一种技术。
当你浏览某网站时,由Web服务器放置于你硬盘上的一个非常小的文本文件,它可以记录你的用户ID、浏览过的网页或者停留的时间等网站想要你保存的信息。当你再次通过浏览器访问该网站时,浏览器会自动将属于该网站的Cookie发送到服务器去,服务器通过读取Cookie,得知你的相关信息,就可以做出相应的动作。
如在页面显示欢迎你的标语,或者让你不用输入ID、密码就直接登录等等。
浏览器访问一个站点时,只将属于当前站点的Cookie发过到服务器。(根据域名)—(没必要把每家医院的病历本都带过去。)
最好是将要保存的内容在服务器端加密,为什么?
在硬盘中存放的位置与使用的操作系统和浏览器密切相关。
浏览器保存Cookie有两种方式:
1—浏览器的内存中;
2—浏览器所在的电脑的硬盘中。
为将要写入到浏览器的Cookie对象设置失效时间:
cook.Expires = DateTime.Now.AddMinutes(5);//设置cook5分钟后失效
开发场景:常用于登录和保存用户最近浏览商品
Cookie的Expires属性不可读.(只有在向浏览器写出的时候能设置)
补充: 不同浏览器间cookie总大小也不同:
Firefox和Safari允许cookie多达4097个字节,包括名(name)、值(value)和等号。
Opera允许cookie多达4096个字节,包括:名(name)、值(value)和等号。
InternetExplorer允许cookie多达4095个字节,包括:名(name)、值(value)和等号。
浏览器允许每个域名所包含的cookie数:
Microsoft指出InternetExplorer8增加cookie限制为每个域名50个,但IE7似乎也允许每个域名50个cookie。
Firefox每个域名cookie限制为50个。
Opera每个域名cookie限制为30个。
Safari/WebKit貌似没有cookie限制。但是如果cookie很多,则会使header大小超过服务器的处理的限制,会导致错误发生。
注:“每个域名cookie限制为20个”将不再正确! 当很多的cookie被设置,浏览器如何去响应。 除Safari(可以设置全部cookie,不管数量多少),
有两个方法:
最少最近使用(leastrecentlyused(LRU))的方法:当Cookie已达到限额,自动踢除最老的Cookie,以使给最新的Cookie一些空间。InternetExplorer和Opera使用此方法。 Firefox很独特:虽然最后的设置的Cookie始终保留,但似乎随机决定哪些cookie被保留。似乎没有任何计划(建议:在Firefox中不要超过Cookie限制)。
Cookie图
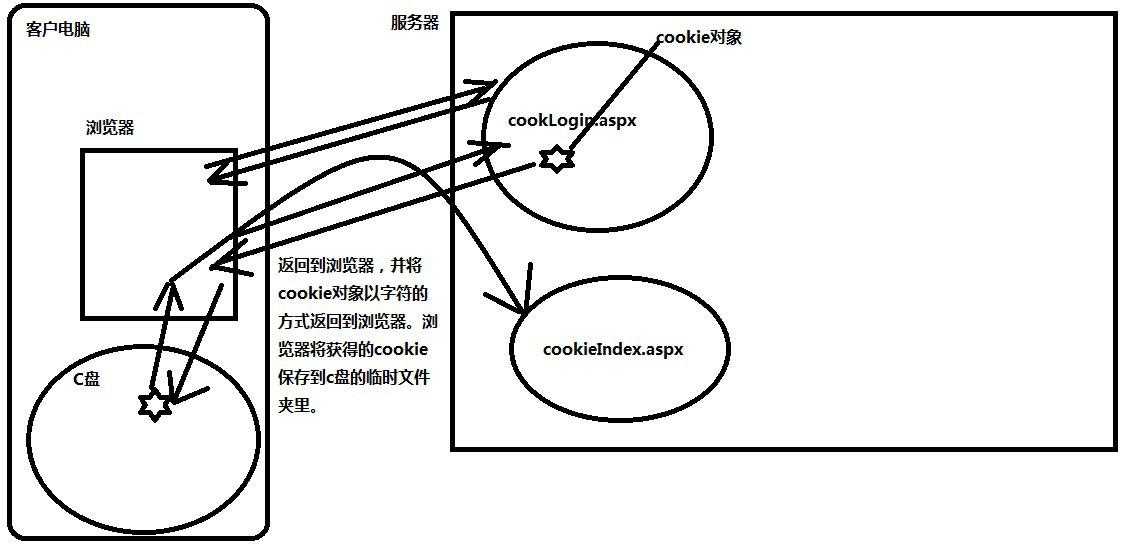
注意:Cookie储存在客户端
请求由上至下:
第一次访问网站,请求cookLogin.aspx页面,服务器将页面的执行结果(html+css+js)发回到浏览器。浏览器翻译执行html+css+js,用户看到界面。
第二次当用户点击登录按钮,将用户名密码提交到服务器后,服务器验证通过,并讲用户ID存入一个Cookie对象,最后将Cookie对象随响应信息一同发回浏览器。浏览器根据情况储存cookie文本。
第三次当用户访问该网站任何页面时,浏览器会自动根据域名将cookie信息一同发往服务器。(注意:浏览器自动完成此操作)
Cookie的操作
服务器设置Cookie:
HttpCookie cok = new HttpCookie(“uId”, “10001”);//(“键”,”值”)
cok.Expires = DateTime.Now.AddDays(18);//设置失效日期-现在之后的18天后
context.Response.Cookies.Add(cok); //添加到响应中
服务器获得客户端传来的Cookie:
string strUName=context.Request.Cookies[“uId”].Value;//从请求中获得Cookie
Cookie原理 --具体如何往返的?
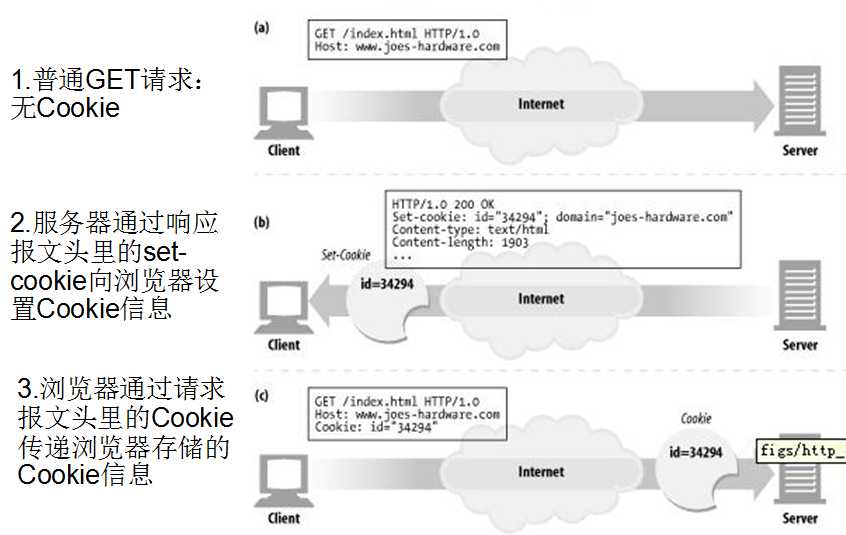
* 服务器向浏览器写出Cookie实际上就是在 响应报文中 生成响应行:
* Set-Cookie: uinfo2=123; expires=Mon, 06-Jun-2011 06:48:47 GMT; path=/
* 浏览器读取此 响应行后 会自动在客户端硬盘中产生一个Cookie文件,名为:
* Cookie:administrator@localhost/,注意@后的 localhoust/ ,实际上是颁发此Cookie网站的域名;
* 当浏览器下次再访问此域名时,就会自动将 后缀为 localhoust/ 的cookie文件内容发送到服务器。
提问:
如果服务器两次都输出同一个名称的Cookie,浏览器会怎么办?
如果服务器输出两个不同名的Cookie,浏览器怎么办?
如何删除浏览器Cookie?
补充:
cookie.Path(为指定的文件夹生成Cookie)
cookie.Domain (域/域名) www.oumind.com book.oumind.com
Response.Cookies和Request.Cookies中间的关系 – 有共用部分
Cookie在浏览器硬盘的存储位置:
C:\Documents and Settings\登录帐户名\Cookies
可以通过 开始-运行-cookies 自动打开。
//建设浏览器有两个Cookie文件:
cookie:aaa@oumind.com(泛域名的Cookie) cookie:aaa@zhaopin.oumind.com(二级域名的Cookie)
当你访问oumind.com域名时,浏览器将 cookie:aaa@oumind.com 内容发送到服务器;
当你访问的是以oumind.com结尾的域名时(如:zhaopin.oumind.com),浏览器除了发送 cookie:aaa@zhaopin.oumind.com之外还会将cookie:aaa@oumind.com也发送到服务器。
//向Response.Cookies中添加Cookie对象的同时也向Request.Cookies集合中添加了Cookie
Cookie详解
表单是和页面相关的,只有浏览器端提交了这些数据,服务器端才能得到。而有时候希望在服务端任意的地方存取一些和访问者相关的信息,这时候就不方便将这些信息保存到表单中了,因为如果那样的话必须随时注意在所有页面表单中都保存这些信息。Cookie是和站点相关的,并且每次向服务器请求的时候除了发送表单参数外,还会将和站点相关的所有Cookie都提交给服务器,是强制性的。Cookie也是保存在浏览器端的,而且浏览器会在每次请求的时候都会把和这个站点的相关的Cookie提交到服务器,并且将服务端返回的Cookie更新到硬盘,因此可以将信息保存在Cookie中,然后在服务器端读取、修改。服务器返回数据除了普通的html数据以外,还会返回修改的Cookie,浏览器把拿到的Cookie值更新本地浏览器的Cookie就可以。 哪怕请求jpg、js、css这种文件也会带着Cookie,因为服务器端可能要进行Session的操作,比如判断是否登录。互联网优化的案例:图片服务器和主站域名不一样,降低Cookie流量的传输。面试时聊网站调优 在服务器端控制Cookie案例,一个页面设置Cookie,一个页面读取Cookie 设置值的页面:Response.SetCookie(new HttpCookie("UserName", TextBox1.Text)); 读取值的页面:Label1.Text = Request.Cookies["UserName"].Value; Cookie的缺点和表单一样,而且还不能存储过多信息。客户端、服务器端设置的Cookie双方都能读。
原文:http://www.cnblogs.com/fanhongshuo/p/3817457.html