音频数字信号详解
整理者:赤勇玄心行天道
QQ号:280604597
微信号:qq280604597
QQ群:511046632
博客:www.cnblogs.com/gaoyaguo
大家有什么不明白的地方,或者想要详细了解的地方可以联系我,我会认真回复的!
你可以随意转载,无需注明出处!
写文档实属不易,我希望大家能支持我、捐助我,金额随意,1块也是支持,我会继续帮助大家解决问题!


信号就是信息的物理表现形式,或者定义为携载信息的自变量函数,信息是信号的具体内容。
根据载体的不同,信号可以分为电的、声的、光的、磁的、机械的、热的、生物医学的等各类信号。根据一个或多个产生源,信号可分为单通道信号和多通道信号,例如单声道音频、双声道立体声音频、五通道环绕声音频。信号表现上可分为任意时刻都能精确确定信号取值的确定信号,及任意时刻信号取值不能精确确定的随机信号。信号的自变量可以是时间、频率、控件或者其他物理量,按自变量数划分,可以有一维的(多数是以时间或频率为自变量表示,例如音频、心跳等)、二维的(例如黑白图像信号的x,y坐标)、多维的(例如黑白视频信号的x,y坐标及时间t,彩色视频信号的红、绿、蓝三原色的三个三维信号组成的三通道信号)。还有其他划分方法,例如周期信号与非周期信号,功率信号与能量信号等。
在自变量的指定值上信号的取值称为信号的振幅值,也叫幅值或函数值,作为自变量的函数的振幅值变化称为波形。
声音就是先由物体振动产生的声波,声波再通过介质(空气或固体、液体)传播并能被人或动物听觉器官所感知的波动现象。最初发出振动的物体叫声源。振动引起的气压变化的大小称为声压,声压是决定声强即响度的主要因素。气压具有一定的频率,即声波每秒变化的次数,以Hz(赫兹)表示。它决定了声音的高低。声压的测量单位是帕(斯卡)。
人耳只能感受到16Hz至20000Hz的声波,低于16Hz的叫次声波,高于20000Hz的叫超声波。人耳对2000Hz至5000HZ的声波感受力最强,但人说话声音频率一般在300Hz至700HZ。
音频是个专业术语,音频一词已用作一般性描述音频范围内和声音有关的设备及其作用。人类能够听到的所有声音都称之为音频,它可能包括噪音等。
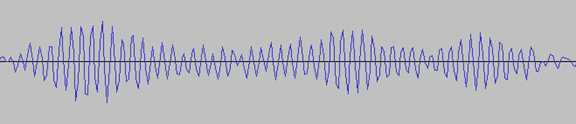
音频信号是指声波的频率、幅度变化信息载体。下图就是一段音频信号的频谱图:
连续时间连续幅值信号是指在以时间为自变量的一维信号中,除个别不连续点外,信号在所讨论的时间段内的任意时间点都有确定的振幅值,且振幅值在取值范围内也有任意种取值。该信号也叫模拟信号。
连续时间离散幅值信号是指在以时间为自变量的一维信号中,除个别不连续点外,信号在所讨论的时间段内的任意时间点都有确定的振幅值,但振幅值在取值范围内只有特定种取值。该信号也叫量化信号。
连续时间连续幅值信号和连续时间离散幅值信号都称为连续时间信号。
例如:信号 的时间和幅值都是连续的,即为模拟信号。
?
离散时间连续幅值信号是指在以时间为自变量的一维信号中,只在离散时间瞬间才有幅值,在其它时间没有,但振幅值在取值范围内有任意种取值。该信号也叫采样信号、抽样信号、取样信号、脉冲信号。
离散时间离散幅值信号是指在以时间为自变量的一维信号中,只在离散时间瞬间才有幅值,在其它时间没有,且振幅值在取值范围内也只有特定种取值。该信号也叫数字信号。
离散时间连续幅值信号和离散时间离散幅值信号都称为离散时间信号,也常称为序列。
?
确定信号是指能用确定的数学函数表示的信号,任意时刻都有确定的幅值,预先可以知道该信号的变化规律。
随机信号是指不能数学函数表示的信号,不能预先可以知道该信号的变化规律。
?
周期信号是指按照一定的时间间隔周而复始,并且无始无终的信号。
他们的表达式可以写作:
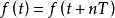 ,
,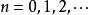 (任意整数)
(任意整数)
其中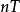 称为
称为 的周期,而满足关系式的最小
的周期,而满足关系式的最小 值则称为是信号的基本周期。
值则称为是信号的基本周期。
非周期信号是指该信号在时间上不具有周而复始的特性,即周期信号的周期趋于无限大。
?
连续时间信号和离散时间信号与周期信号和非周期信号彼此包含,即连续时间信号和离散时间信号中有周期信号和非周期信号,同理,周期信号和非周期信号中也包含连续时间信号和离散时间信号。
?
模拟信号是指用连续变化的物理量所表达的信息,其信号的幅度,或频率,或相位随时间作连续变化,如温度、湿度、压力、长度、电流、电压等等,我们通常又把模拟信号称为连续信号,它在一定的时间范围内可以有无限多个不同的取值。而数字信号是指在取值上是离散的、不连续的信号。
数字信号处理利用计算机的信号处理设备,采用数值计算的方法对信号进行处理的一门学科,包括滤波、变换、压缩、扩展、增强、复原、估计、识别、分析、综合等加工处理,已达到提取有用信息、便于应用的目的。
在数字信号处理领域,量化是指将信号的连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程。量化主要应用于从连续信号到数字信号的转换中。连续信号经过采样成为离散信号,离散信号经过量化即成为数字信号。注意离散信号通常情况下并不需要经过量化的过程,但可能在值域上并不离散,还是需要经过量化的过程。信号的采样和量化通常都是由模数转换器实现的。

?
防混叠模拟低通滤波器:把会造成混叠失真的高频分量滤除掉。
模拟信号转换成数字信号的过程叫做模数转换,简写成A/D,完成这种功能的电路叫做模数转换器,简称ADC。模数转换器的框图如图所示:
?
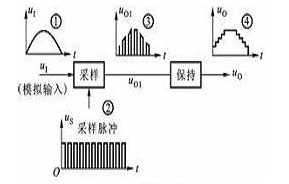
输入端输入的模拟信号,经采样、保持、量化和编码四个过程的处理,转换成对应的二进制数码输出。采样就是利用模拟开关将连续变化的模拟量变成离散的数字量,如上图中波形③所示。由于经采样后形成的数字量宽度较窄,经过保持电路可将窄脉冲展宽,形成梯形波,如波形④所示。量化就是将阶梯形模拟信号中各个值转化为某个最小单位的整数倍,便于用数字量来表示。编码就是将量化的结果(即整数倍值)用二进制数码来表示。这个过程就实现了模数转换。目前集成模数转换器种类较多,有8位、10位模数转换器。
?
?

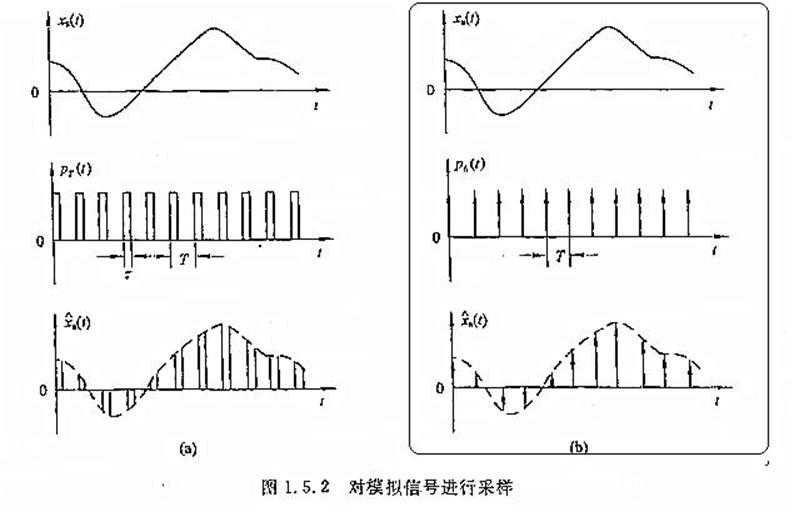
实例:

数字信号转换成模拟信号的过程叫做数模转换,简写成D/A,完成这种功能的电路叫做数模转换器,简称DAC。
?


原始信号

采样并转化后的数字信号
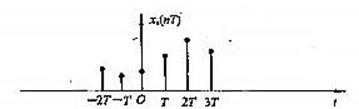
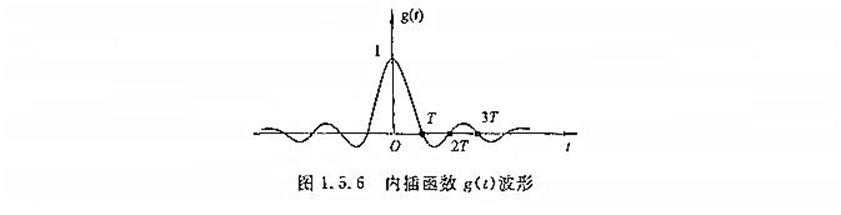
理想滤波器滤波(1.5.9式的实现过程)
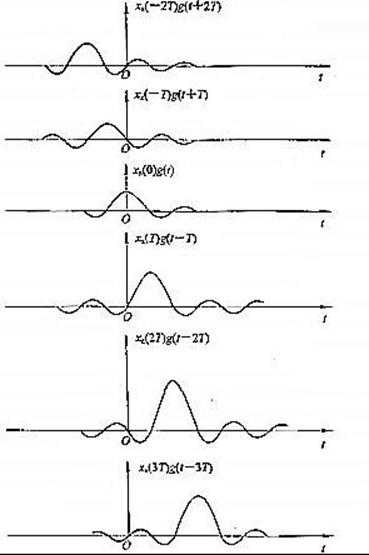
最终还原后的信号
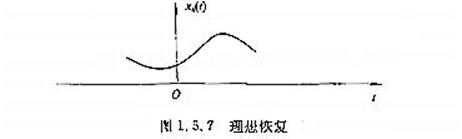
??? M:理论上,满足采样定理采样得到的数字信号,忽略量化误差,经过理想低通滤波器的滤波,能过无误差的恢复(完全恢复)原始信号。但实际上,有量化误差,而且理想低通滤波器是不存在的(非因果系统),所以需要找到能够逼近理性低通滤波器的可行方案。
?
零阶保持器的单位冲击响应(DAC的单位冲击响应)
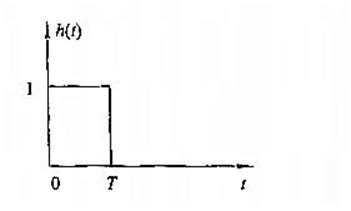
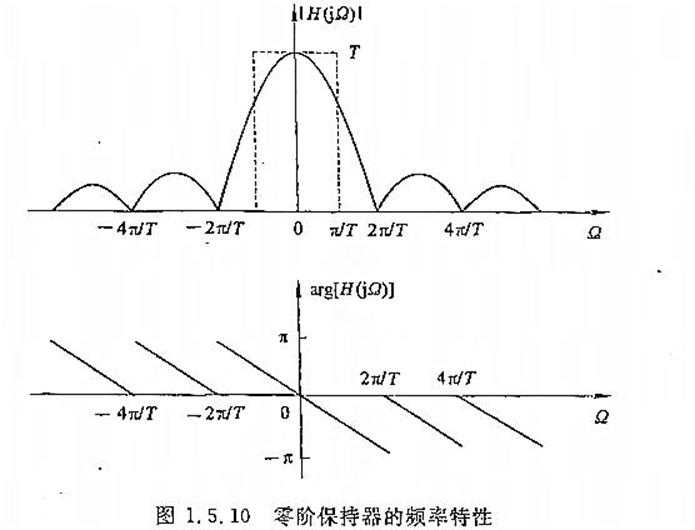
零阶保持器的频率特性(理想低通滤波器的一种逼近方式)
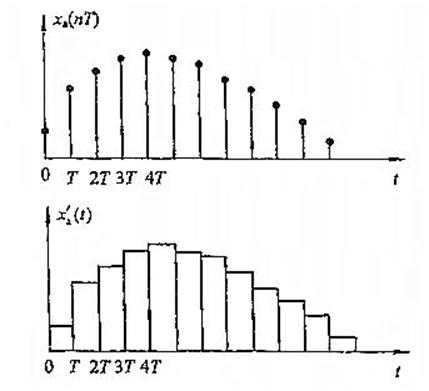
零阶保持器对一个数字信号的恢复过程
?
网络电话,也称互联网电话、IP电话,是指通话双方将语音信号以数据包的形式在互联网上进行传输,从而实现打电话的功能。网络电话的优点就是资费很低,甚至是免费的,缺点就是网络信号稳定性比电话网要差。
网络电话通常是双向同时进行的,也就是全双工的。一方说话,另一方则听到声音,看似简单,但是其背后的流程却十分复杂,其各个主要环节简化后如下图所示:
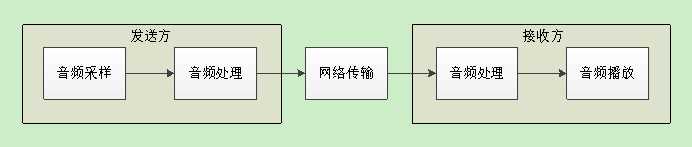
音频数字信号采样是指,从麦克风采样音频模拟信号,然后转换成数字信号,俗称录音。
麦克风其实是通过声波带动振膜一起震动来采样音频信号的。下图就是一个麦克风的振膜:

振膜在震动时会有幅度,这个幅度会随着时间的推移而变化,我们把这个幅度值用二维坐标图画出来就是:
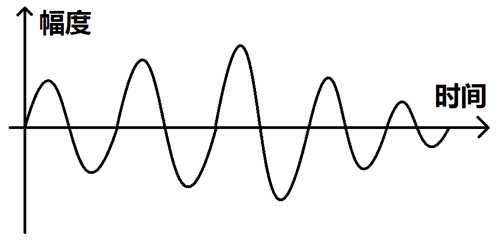
上图所表示的其实就是音频模拟信号了,由于计算机不能处理模拟信号,只能处理一个一个的数据,所以我们要将这个模拟信号转换为数字信号。转换过程就是每隔一小段时间就采样一次这个时刻的幅度值,如下图:
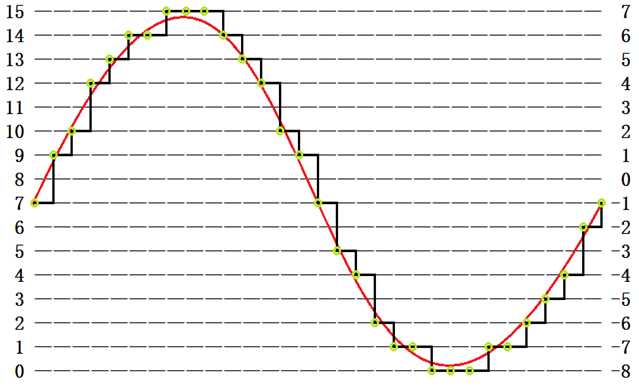
经过转换后,这个信号就可以表示成一个4位无符号整型序列:{7,9,10,12,13,14,14,15,15,15,14,13,12,10,9,7,5,4,2,1,1,0,0,0,1,1,2,3,4,6,7},也可以为表示成一个4位有符号整型序列:{-1,1,2,4,5,6,6,7,7,7,6,5,4,2,1,-1,-3,-4,-6,-7,-7,-8,-8,-8,-7,-7,-6,-5,-4,-2,-1},这个序列就是数字信号了。
转换后的数字信号和转换前的模拟信号是有一定的误差的,这就意味着误差越大,音质越差,误差越小,音质越好。
我们可以简单的理解为通过一个振膜采样到的音频数据就是一个声道,两个振膜就是两个声道,以此类推。
振膜一般有大、中、小三种尺寸,尺寸越大,对声波越敏感,成本也越高。
一个麦克风里面有的有一个振膜,有的有两个振膜。一个振膜的麦克风进行的是Mono单声道录音,两个振膜的麦克风进行的是Stereo双声道立体声录音。五声道环绕立体声录音就是麦克风1录取东北方向的声音,麦克风2录取西北方向的声音,麦克风3录取西南方向的声音,麦克风4录取东南方向的声音,麦克风5录取正前方的声音。另外还有四声道环绕立体声录音和七声道环绕立体声录音。
单声道麦克风: ,双声道立体声麦克风:
,双声道立体声麦克风: 。
。
?
采样频率就是每秒对音频模拟信号的采样次数,常见音频采样频率有8000Hz、16000Hz、22050Hz、32000Hz、44100Hz、48000Hz、96000Hz等。
采样频率越高,音频数字信号就越接近之前的音频模拟信号,音质也就越好,硬件成本也就越高,存储空间占用也就越大。
采样位数可以理解数字音频设备处理声音的解析度,即对声音的辨析度。采样位数一般有8位、16位、24位等,就像表示颜色的表示位数一样(8位能表示256种颜色,16位能表示65536种颜色)。
如果采样位数为8位,则有256个级别的采样数据,其动态范围为20×log(256)分贝,大约是48db。
如果采样位数为16位,则有65535个级别的采样数据,其动态范围为20×log(65536)分贝,大约是96 db。
如果采样位数为24位,则有16777216个级别的采样数据,其动态范围为20×log(16777216)分贝,大约是144db。
采样位数越高,采样数据的级别越密集,幅值采样就越精准,音质也就越好,但硬件成本也就越高,存储空间占用也就越高。16位采样已经接近了人听觉极限和痛苦极限,是音乐的理想范围,一般采样位数都是这么高了。
采样数据就是指每一次采样所得到的那个振幅值。具体取值范围如下:
采样位数 | 数据类型 | 取值范围 |
8位 | 无符号整型 | 0~255 |
8位 | 有符号整型 | -128~127 |
16位 | 无符号整型 | 0~65535 |
16位 | 有符号整型 | -32768~32767 |
24位 | 无符号整型 | 0~16777216 |
24位 | 有符号整型 | -8388608~8388607 |
?
采样数据帧就是将多个连续的采样数据分为一组,主要是为了便于处理采样数据。
采样数据帧一般是以时间为单位进行分组,例如:将8000hz的音频数据流按20ms为一个单位划分为一帧,则每帧包含160个采样数据。
一般音频编码都是以音频数据帧为单位进行的,每次编码一个音频数据帧。
音频数据帧的大小计算公式:(采样频率×采样位数×声道数×时间)÷8。
例如:一个采样数据帧的时长为20ms,即每20ms的音频数据构成一个音频数据帧。假设:采样频率为16000Hz、采样位数为16位、声道数为1,则这个音频数据帧的大小为:(16000×16×1×0.02)÷8 = 640字节。算式中的0.02为秒,即20ms。
采样数据帧长度就是每个采样数据帧包含多少个采样数据。
采样数据帧的长度计算公式:采样频率×时间
例如:采样频率为16000Hz,一个采样数据帧的时长为20ms,那么这个采样数据帧的长度为:16000×0.02=320个采样数据。算式中的0.02为秒,即20ms。
我们采样到的最原始的音频数字信号的那一串数列就是脉冲编码调制格式的,也叫PCM格式。具体格式如下:
声道数 | 采样位数 | 字节1 | 字节2 | 字节3 | 字节4 | 字节5 | 字节6 | 字节7 | 字节8 |
单声道 | 8位 | FRONT 前声道 采样数据 | FRONT 前声道 采样数据 | FRONT 前声道 采样数据 | FRONT 前声道 采样数据 | FRONT 前声道 采样数据 | FRONT 前声道 采样数据 | FRONT 前声道 采样数据 | FRONT 前声道 采样数据 |
单声道 | 16位 | FRONT 前声道 采样数据 | FRONT 前声道 采样数据 | FRONT 前声道 采样数据 | FRONT 前声道 采样数据 | ||||
双声道 | 8位 | LEFT 左声道 采样数据 | RIGHT 右声道 采样数据 | LEFT 左声道 采样数据 | RIGHT 右声道 采样数据 | LEFT 左声道 采样数据 | RIGHT 右声道 采样数据 | LEFT 左声道 采样数据 | RIGHT 右声道 采样数据 |
双声道 | 16位 | LEFT 左声道 采样数据 | RIGHT 右声道 采样数据 | LEFT 左声道 采样数据 | RIGHT 右声道 采样数据 | ||||
?
发送方依次将各个音频数据帧通过网络发送给通话的对方。由于语音对讲对实时性要求比较高,所以低延迟和平稳连续是非常重要的,这样语音对讲才能顺畅。
网络传输必须要注意的问题就是,一个是乱序到达,一个是丢包。
一般常用的网络传输协议是实时传输协议(Real-time Transport Protocol、RTP),也有用TCP协议的。
音频数字信号还原是指,将得到的PCM格式音频数据帧提交给声卡,声卡会把音频数字信号再转换为音频模拟信号,并输出到扬声器,扬声器就会根据音频模拟信号而振动起来,然后就会产生声波,最后我们就能听还原后的声音了。
仅仅只是实现网络电话,那就只需要进行采样、传输、播放就好了,但是实际使用过程中我们会发现语音对讲中的各种问题会严重影响我们的对讲体验,正是有很多现实的因素给我们带来了众多挑战,使得网络电话系统的实现不是那么简单,其中涉及到很多专业技术。
我觉得"效果良好"的网络电话系统应该达到如下几点:
如果我们将采样到的PCM格式音频数据直接发送或者存储,那么每秒需要占用的带宽就是16000Hz×16bit=31.25 KB/S,这就要占用很大的带宽了。那么我们就需要对PCM格式进行压缩了,将压缩后的音频数据再进行发送或者存储,当需要播放的时候,再解压缩成PCM格式进行播放。我们把音频数据压缩的过程称之为编码,把音频数据解压缩的过程称之为解码。
音频编码分为两大类,一类是无损压缩,一类是有损压缩。无损压缩是指编码前的PCM格式音频数据和解码后的PCM格式音频数据是完全一样的,音频信号没有任何的损失。有损压缩是指解码后的PCM格式音频数据只是近似于编码前的PCM格式音频数据,并不完全一样。所以无损压缩的音质是最好的,压缩率也是最低的,有损压缩的音质会受压缩率的高低影响好坏。
音频编码算法一般有三种方式:固定比特率、可变比特率、平均比特率。不同的编码方式的区别主要在于压缩率不一样。
目前常用的无损音频编码格式有:AAL、APE、FLAC、等等,有损音频编码格式有:G.729、iLBC、AAC、Speex、Opus、等等。
对于视频编码来说,CBR编码指的是编码器每秒钟的输出码数据量(或者解码器的输入码率)应该是固定制(常数)。编码器检测每一帧图像的复杂程度,然后计算出码率。如果码率过小,就填充无用数据,使之与指定码率保持一致;如果码率过大,就适当降低码率,也使之与指定码率保持一致。因此,固定码率模式的编码效率比较低。在快速运动画面部分,画面细节较多,一般需要更多的比特来描述,但由于强行降低码率,因此会丢失部分画面的细节信息,而出现画面模糊、不清晰现象。对于音频压缩来说,比如MP3,比特率是最重要的因素,它用来表示每秒钟的音频数据占用了多少个比特,这个值越高,音质就越好。CBR使用固定比特率编码音频,一首MP3从头至尾为某固定值,如128 kbps进行编码。
可变比特率可以随着图像的复杂程度的不同而变化,因此其编码效率比较高,快速运动画面的马赛克就很少。编码软件在压缩时,根据视频数据,即时确定使用什么比特率,这样既保证了质量,又兼顾了文件大小。使用这种方式时,编码程序可以选择从最差音视频质量(一般此时压缩比最高)到最好音视频质量(一般此时压缩比最低)之间的各种视频质量。在视频文件编码的时候,编码程序会尝试保持所选定的整个文件的品质,对视频文件的不同部分选择不同的比特率来编码。例如,使用MP3格式的音频编解码器,音频文件可以以8~320kbps的可变码率进行压缩,得到相对小的文件来节约存储空间。MP3格式的文件格式是*.mp3。
当形容编解码器的时候,VBR编码指的是编码器的输出码率(或者解码器的输入码率)可以根据编码器的输入源信号的复杂度自适应的调整,目的是达到保持输出质量保持不变而不是保持输出码率保持不变。VBR适用于存储(不太适用于流式传输),可以更好的利用有限的存储空间:用比较多的码字对复杂度高的段进行编码,用比较少的码字对复杂度低的段进行编码。
像Vorbis这样的编解码器和几乎所有的视频编解码器内在的都是VBR的。*.mp3文件也可以以VBR的方式进行编码。
例如:有一段采样频率8000Hz的PCM格式音频数据,一共10帧,每帧20ms,可能其中5帧声音变化较大,其他5帧声音变化较小,那么用VBR来编码时,就会把声音变化较大的那5帧用较高的采样频率编码,编码后体积也较大,另外那声音变化较小的那5帧就用较低的采样频率编码,编码后体积也较小。
平均比特率是VBR的一种插值参数。它针对CBR不佳的文件体积比和VBR生成文件大小不定的特点独创了这种编码模式。ABR在指定的文件大小内,例如以每50帧(30帧约1秒)为一段,低频和不敏感频率使用相对低的流量,高频和大动态表现时使用高流量,可以做为VBR和CBR的一种折衷选择。
当对方接收到编码后的音频数据帧后,需要对其进行解码,以恢复成为可供声卡直接播放的PCM格式音频数据。如果是直接发送PCM格式的音频数据帧,对方就不需要解码,直接就可以播放。
通常情况下没有解码的音频数据是不能播放的,但也有些操作系统可以直接播放某些常用编码格式的音频数据,其实就是操作系统帮我们做了解码。
大家在语音通话时都会用到电脑的扬声器外放功能,或者手机的免提功能。这是一个很方便的功能,但这个小小的功能曾经音频技术提出了很大挑战。当使用外放功能时,扬声器播放的声音会被麦克风再次采集,然后在传给对方时,对方就会听到自己的声音,俗称声学回音。这个声学回音在被循环很多次之后,还有可能会变成啸叫。所以,我们需要将这个声学回音消除掉。
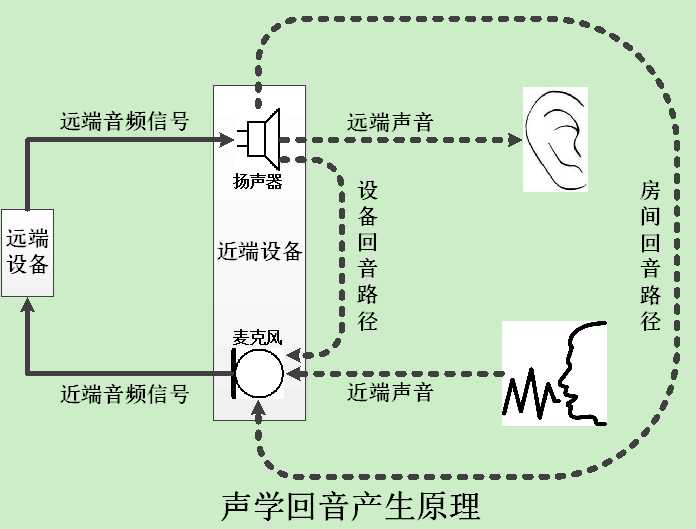
声学回音消除算法的原理就是,根据音频输出数据帧,在音频输入数据帧中做一些类似抵消的运算,从而将声学回音从音频输入数据中过滤掉。这个算法过程是相当复杂的,因为根据你聊天时所处的房间的大小、以及你在房间中的位置,回音的声波反射时长和次数将会不一样,所以声学回音消除算法需要自动调整内部参数来适应当前的环境。
声学回音消除必须注意的问题:
?
声学回音消除算法一般有这几种:时域算法,频域算法,子带算法。
声学回音消除算法分为两大类:基于DSP等实时平台的回音消除,基于Windows等非实时平台的回音消除。两者的技术难度和重点是不一样的。
?
各个操作系统是否自带声学回音消除功能:
Windows、UNIX、Linux操作系统没有自带声学回音消除功能,需要调用第三方库实现。
Android操作系统虽然自带有声学回音消除功能,但是需要设备厂商自己实现,由于很多厂商都实现不了该功能,所以大部分的手机都不自带该功能,仍然需要调用第三方库实现。
IOS操作系统自带有声学回音消除功能,而且效果非常好,可以放心调用,当然也可以调用第三方库实现。
?
声学回音消除效果演示:
音频输入数据:
音频输出数据:
音频结果数据:
所谓音频输入输出数据帧同步就是指,音频输入数据帧和音频输出数据帧的开始时间及结束时间都是相同的时刻。
由于声学回音消除算法要求音频输入输出数据帧同步得非常好,所以在做声学回音消除前,必须先研究如何做同步。但是,其实声学回音消除算法要求并不一定完全同步,主要是要求音频输入数据帧必须比音频输出数据帧要先开始,只要能保证音频输入数据中的回音出现在音频输出数据帧之后,回音就可以被消除掉,但又不能先开始太久,越靠近越好,一般先开始0ms~300ms都是可以正常消除的。
比如:一帧20ms,音频输入数据帧的开始时间为13点05分15秒220毫秒、结束时间为13点05分15秒240毫秒,那么音频输出数据帧的开始时间也应该为13点05分15秒220毫秒、结束时间也应该为13点05分15秒240毫秒。如果做不到完全同步,音频输出数据帧的开始时间也可以为13点05分15秒340毫秒、结束时间也可以为13点05分15秒360毫秒,慢120ms左右回音消除是不会有问题的。
?
同步的方法:
Windows、UNIX、Linux操作系统:
直接用PortAudio库可以完美同步。
?
Android操作系统:
第一种:调用第三方修改的jni层的Android版的PortAudio的OpenSLES库实现同步,本方法可以完美同步,但是有些手机对OpenSLES库支持并不好,导致播放或录音有很高的延迟,所以本方法兼容性较差。下载地址:https://github.com/Gundersanne/portaudio_opensles
第二种:在单线程中,先初始化AudioRecord类和AudioTrack类,并先调用AudioRecord.startRecording()函数再调用AudioTrack.play()函数,然后进入循环体,先调用AudioTrack.write()函数阻塞播放音频输出数据帧,然后再调用AudioRecord.read()函数获取音频输入数据帧,循环体完毕。理论上这样做出来的音频输入输出数据帧就是同步的,但是由于Android操作系统Java代码的函数调用是有延迟的,不同的手机延迟会不一样,最终就会导致大部分的手机不能同步,所以本方法兼容性和稳定性都很差。
第三种:先在主线程中,初始化AudioRecord类和AudioTrack类,并先调用AudioRecord.startRecording()函数再调用AudioTrack.play()函数,然后再启动两个线程,一个音频输入线程负责调用AudioRecord.read()函数获取音频输入数据帧,并依次存放到已录音的音频输入数据帧链表,一个音频输出线程负责调用AudioTrack.write()函数播放音频输出数据帧,并依次存放到已播放的音频输出数据帧链表。先启动音频输入线程,再启动音频输出线程,这样已录音的音频输入数据帧链表和已播放的音频输出数据帧链表里的数据帧就是一一对应同步的,本方法在大部分情况下可以差不多完美同步,但是极少数情况下如果系统出现突然卡顿,就可能会不同步了,所以本方法兼容性和稳定性都很好。
第四种:本人后来发现,有些手机在调用AudioRecord.startRecording()函数后,居然并没有真正开始录音,而是要在调用AudioRecord.read()函数过程中时才会真正开始,那么这样就有可能会导致播放线程走在前面了,所以在第三种方法中,改为在音频输入线程调用一次AudioRecord.read()函数并丢弃掉后,再在音频输入线程中启动音频输出线程。这样本方法在绝大部分情况下可以差不多完美同步。
第五种:本人后来又发现,有些手机在调用AudioRecord.read()函数后,居然并没有真正开始录音,而是要在调用好几次AudioRecord.read()函数后才会真正开始,那么这样就有可能会导致播放线程走在前面了,所以在第四种方法中,改为在音频输入线程调用多次AudioRecord.read()函数,直到读取到的音频数据不是全0了并全部丢弃掉后,再在音频输入线程中启动音频输出线程。这样本方法在所有手机上可以差不多完美同步。
?
IOS操作系统:
应该和Android操作系统的第五种方法同理,本人没有测试过。
如果是调用系统自带的声学回音消除功能是不需要做同步的。
http://www.cnblogs.com/jqyp/archive/2011/12/31/2308659.html
?
一、前言
因为工作的关系,笔者从2004年开始接触回声消除(Echo Cancellation)技术,而后一直在某大型通讯企业从事与回声消除技术相关的工作,对回声消除这个看似神秘、高端和难以理解的技术领域可谓知之甚详。
要了解回声消除技术的来龙去脉,不得不提及作为现代通讯技术的理论基础——数字信号处理理论。首先,数字信号处理理论里面有一门重要的分支,叫做自适应信号处理。而在经典的教材里面,回声消除问题从来都是作为一个经典的自适应信号处理案例来讨论的。既然回声消除在教科书上都作为一种经典的具体的应用,也就是说在理论角度是没有什么神秘和新鲜的,那么回声消除的难度在哪里?为什么提供回声消除技术(不管是芯片还是算法)的公司都是来自国外?回声消除技术的神秘性在哪里?
?
二、回声消除原理
从通讯回音产生的原因看,可以分为声学回音(Acoustic Echo)和线路回音(Line Echo),相应的回声消除技术就叫声学回声消除(Acoustic Echo Cancellation,AEC)和线路回声消除(Line Echo Cancellation, LEC)。声学回音是由于在免提或者会议应用中,扬声器的声音多次反馈到麦克风引起的(比较好理解);线路回音是由于物理电子线路的二四线匹配耦合引起的(比较难理解)。
回音的产生主要有两种原因:
1.??由于空间声学反射产生的声学回音(见下图):
?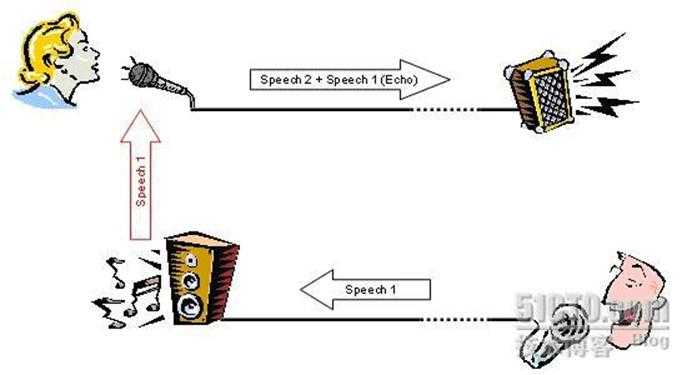
图中的男子说话,语音信号(speech1)传到女士所在的房间,由于空间的反射,形成回音speech1(Echo)重新从麦克风输入,同时叠加了女士的语音信号(speech2)。此时男子将会听到女士的声音叠加了自己的声音,影响了正常的通话质量。此时在女士所在房间应用回音抵消模块,可以抵消掉男子的回音,让男子只听到女士的声音。
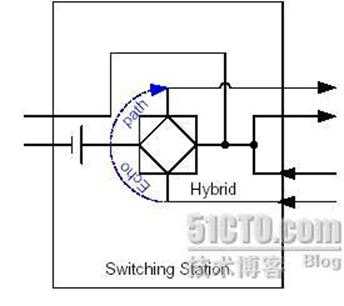
2.??由于2-4线转换引入的线路回音(见下图):
????????????????????????????? ?
?
? ?
? ?
在ADSL?Modem和交换机上都存在2-4线转换的电路,由于电路存在不匹配的问题,会有一部分的信号被反馈回来,形成了回音。如果在交换机侧不加回音抵消功能,打电话的人就会自己听到自己的声音。
不管产生的原因如何,对语音通讯终端或者语音中继交换机需要做的事情都一样:在发送时,把不需要的回音从语音流中间去掉。
试想一下,对一个至少混合了两个声音的语音流,要把它们分开,然后去掉其中一个,难度何其之大。就像一瓶蓝墨水和一瓶红墨水倒在一起,然后需要把红墨水提取出来,这恐怕不可能了。所以回声消除被认为是神秘和难以理解的技术也就不奇怪了。诚然,如果仅仅单独拿来一段混合了回音的语音信号,要去掉回音也是不可能的(就算是最先进的盲信号分离技术也做不到)。但是,实际上,除了这个混合信号,我们是可以得到产生回音的原始信号的,虽然不同于回音信号。
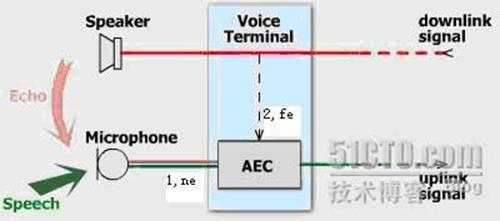
我们看下面的AEC声学回声消除框图(本图片转载)。
?
? ?
Figure??Acoustic Echo Cancellation in a voice communication terminal
? ?
其中,我们可以得到两个信号:一个是蓝色和红色混合的信号1,也就是实际需要发送的speech和实际不需要的echo混合而成的语音流;另一个就是虚线的信号2,也就是原始的引起回音的语音。那大家会说,哦,原来回声消除这么简单,直接从混合信号1里面把把这个虚线的2减掉不就行了?请注意,拿到的这个虚线信号2和回音echo是有差异的,直接相减会使语音面目全非。我们把混合信号1叫做近端信号ne,虚线信号2叫做远端参考信号fe,如果没有fe这个信号,回声消除就是不可能完成的任务,就像"巧妇难为无米之炊"。
虽然参考信号fe和echo不完全一样,存在差异,但是二者是高度相关的,这也是echo称之为回音的原因。至少,回音的语义和参考信号是一样的,也还听得懂,但是如果你说一句,马上又听到自己的话回来一句,那是比较难受的。既然fe和echo高度相关,echo又是fe引起的,我们可以把echo表示为fe的数学函数:echo=F(fe)。函数F被称之为回音路径。在声学回声消除里面,函数F表示声音在墙壁,天花板等表面多次反射的物理过程;在线路回声消除里面,函数F表示电子线路的二四线匹配耦合过程。很显然,我们下面要做的工作就是求解函数F。得到函数F就可以从fe计算得到echo,然后从混合信号1里面减掉echo就实现了回声消除。
? ?
尽管回声消除是非常复杂的技术,但我们可以简单的描述这种处理方法:
1、房间A的音频会议系统接收到房间B中的声音
2、声音被采样,这一采样被称为回声消除参考
3、随后声音被送到房间A的音箱和声学回声消除器中
4、房间B的声音和房间A的声音一起被房间A的话筒拾取
5、声音被送到声学回声消除器中,与原始的采样进行比较,移除房间B的声音
? ?
求解回音路径函数F的过程恐怕就是比较难以表达的数学公式了。鉴于通俗表达数学公式的难度比发现数学公式还难,笔者就不费力解释了。下面这段表达了利用自适应滤波器原理求解函数F的过程。(以下可以跳过)
? ?
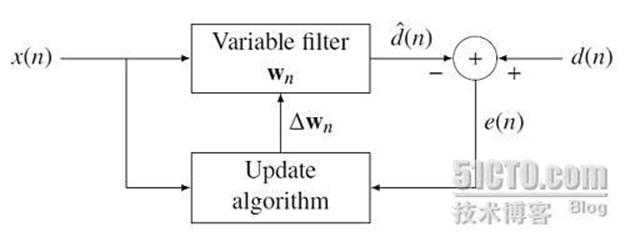
自适应滤波器
自适应滤波器是以输入和输出信号的统计特性的估计为依据,采取特定算法自动地调整滤波器系数,使其达到最佳滤波特性的一种算法或装置。自适应滤波器可以是连续域的或是离散域的。离散域自适应滤波器由一组抽头延迟线、可变加权系数和自动调整系数的机构组成。附图表示一个离散域自适应滤波器用于模拟未知离散系统的信号流图。自适应滤波器对输入信号序列x(n)的每一个样值,按特定的算法,更新、调整加权系数,使输出信号序列y(n)与期望输出信号序列d(n)相比较的均方误差为最小,即输出信号序列y(n)逼近期望信号序列d(n)。
?
?
? ?
以最小均方误差为准则设计的自适应滤波器的系数可以由维纳-霍甫夫方程解得。
B.维德罗提出的一种方法,能实时求解自适应滤波器系数,其结果接近维纳-霍甫夫方程近似解。这种算法称为最小均方算法或简称?LMS法。这一算法利用最陡下降法,由均方误差的梯度估计从现时刻滤波器系数向量迭代计算下一个时刻的系数向量
?
式中ks为一负数,它的取值决定算法的收敛性,?V【ε2(n)】为均方误差梯度估计,
? ?
自适应滤波器应用于通信领域的自动均衡、回声消除、天线阵波束形成,以及其他有关领域信号处理的参数识别、噪声消除、谱估计等方面。对于不同的应用,只是所加输入信号和期望信号不同,基本原理则是相同的。(以上部分可以跳过)
? ?
上面这段话表明,需要求解的回音路径函数F就是一个自适应滤波器W(n)收敛的过程。所加输入信号x(n)是fe,期望信号是echo,自适应滤波器收敛后的W(n)就是回音路径函数F。?收敛之后,当实际回音发生,我们把fe通过函数W(n),就可以得到一个很准确的echo,把混合信号直接减去echo,得到实际需要发送的语音speech,完成回声消除任务。
值得注意的两点:
1、???????????自适应滤波器收敛阶段,期望信号是完全的echo,不能混杂有speech。因为speech和fe是没有关系的,会扰乱W(n)的收敛过程。也就是说要求回声消除算法开始运转后收敛要非常快,最好对方还来不及说话,你一说就收敛好了;收敛好之后,如果对方开始说话,也就是有speech混合过来,这个W(n)系数就不要变化了,需要稳定下来。
2、????????????回音路径可能是变化的,一旦出现变化,回声消除算法要能判断出来,因为自适应滤波器学习要重新开始,也就是W(n)需要一个新的收敛过程,以逼近新的回音路径函数F。
基本上来说,上面这两点是两难的,一个需要自适应滤波器收敛后保持系数稳定,以保证不受speech说话干扰,另一个需要自适应滤波器随时保持更新状态,以保证能够追踪变化的回音路径。这样一来,仅从数学算法层面,回声消除已经是难上加难!简单地说,回声消除自适应滤波器的设计具有两个互相矛盾的特性,也就是快速收敛和高度的稳定性,如何同时实现这两项特性,正是设计上的主要挑战。
经过上面的分析,相信大家对回声消除的原理和技术有了深刻的理解,这是一门即容易理解又难以实现的技术。
?从应用平台来看,根据笔者多年的经验,可以把回声消除分为两大类:基于DSP等实时平台的回声消除技术和基于Windows等非实时平台的回声消除技术。两者的技术难度和重点是不一样的。
? ?
三、基于DSP平台的回声消除技术
回声消除技术传统的应用领域是各种嵌入式设备,包括各种电信网络设备和终端设备。网络设备比如交换机,网关等等,终端则包括移动电话终端,视频会议终端等。现代通讯产品里面大量应用了回声消除技术,包括在我们看得到的终端产品(比如手机)和看不到的局端产品(比如交换机)。这种嵌入式设备的共同点就是采用各种型号的DSP芯片作为回声消除的载体。一个有效的回声消除算法需要持续的在一颗DSP芯片上面运行,会遇到以下方面的难点:
实时性与高效性,因为DSP芯片资源有限。虽然自从二十世纪七十年代DSP应用以来,日新月异的硬件芯片技术使许多沉睡在教科书上的信号处理理论算法大规模应用,但是回声消除算法需要的资源还是大得惊人。以视频会议系统,大规模的会议室可以产生超过512ms的回音,要消除这么长延时的回音,即使按照8k赫兹采样率计算,自适应滤波器W(n)的长度都会达到4096个点,这样一方面需要非常大的存储空间来存储W(n),另一方面,W(n)的更新需要的计算量也是成倍增长,同时,W(n)的收敛难度也在加大,传统自适应滤波器的效率很难保证。对于电信设备中的应用,虽然回声消除不需要这么长的延时,但是在交换机等设备中,成本和效率就是生命,所有的处理算法都是按路或按线计算的,对算法的优化效率提出了无止境的要求。相对而言,只有像车载免提这种应用对效率要求不那么高,因为车内空间小,回音延时有限,又不要求多路应用。
传统的回声消除技术是从国外二十世纪七十年代的早期算法发展而来,这类技术的采用一直相当昂贵,提供电信级回声消除硬件应用(包括芯片或者设备)的厂家都是国外的。对于移动网络用户来说,语音品质一直是他们最关切的议题,对电信业者来说,语音也仍是他们最能获利的服务项目,因此语音的品质是不容妥协的。为了满足今日与未来的网路需求,回声消除技术的挑战正在于如何有效地降低成本并持续改善语音品质。
算法级的DSP软件解决方案,也是解决嵌入式设备回音问题的一种途径,对用户也有一定的灵活性,用户只需要把回声消除模块集成到自己的DSP软件中,再简单调整几个相关参数,就能达到较好的回声消除效果。
目前基于DSP的回声消除算法已经比较成熟,市场上也有一批专门的算法/芯片公司的能够对外提供已经优化好的基于DSP的软件回声消除模块:如俄罗斯Spririt DSP、加拿大Octastic Semiconductor、瑞典GIPS、国内科莱特斯科技Conatus Technologies以及美国Adaptive Digital、和GAO Research、英国CSR等等,另外还有美国Fortemedia、Acoustic Technologies和日本OKI等可以提供专用的回声消除DSP芯片。其中性能较好的有Octastic、Conatus、和Spririt这三家,Octastic可以提供完整的从专用芯片、板卡到DSP算法的完整方案,而Conatus和Spririt的回声消除效果更好,值得一提的是Conatus公司是目前市面上唯一提供针对专业视讯会议应用宽带回声消除模块的公司,其音频采样率可以达到48k赫兹。
? ?
四、基于Windows平台的回声消除技术
? ?
回声消除技术最新的应用领域是基于Windows平台的各种VoIP应用,比如软件视频会议,VoIP软件电话等。当回声消除算法应用到Windows平台,相对于传统的DSP平台,既带来优势,也带来了新的难点。高效性在Windows平台已经不是问题,现在的pc机,拥有丰富的cpu资源和海量的内存资源,再复杂的回声消除算法都可以运行自如。但是,新增加的麻烦比带来的好处要多。
首先,Windows平台是一个非实时的平台,音频的采集和播放对回声消除算法而言,也是非实时的。和DSP平台不一样,DSP平台可以直接控制AD/DA芯片的采集播放,获得实时的音频流(不存在同步问题),但是Windows平台下,应用程序很难在底层直接控制声卡的采集播放,获得的是非实时的音频流,从而带来了采集和播放音频流的同步问题。
实际应用时,传给回声消除算法的两个声音信号(采集的回音信号ne和播放的参考信号fe),必须同步得非常的好。就是说,本地接收到远端说的话以后,要把这些话音数据传给回声消除算法做参考,这是一个算法需要的输入信号;然后再传给声卡,声卡放出来后经过回音路径,这时,本地再采集,然后传给回声消除算法,这是算法需要的另一个输入信号。这里的同步是指:两个信号虽然存在延时,但这个延时必须固定,在时序上要保持连贯,不能一个信号多来几个帧,另外一个信号少来几个帧。如果传给回声消除算法的两个信号同步得不好,即两个信号发生帧错位,就没有办法进行消除了。因为这时系统会变成了非因果系统,比如期望信号收到了,参考信号还没来,时间上都没有因果关系,肯定是没有办法消除的。
实际情况是,在一般的VoIP软件中,接收对方的声音并传到声卡中播放是在一个线程中进行的,而采集本地的声音并传送到对方又是在另一个线程中进行的,而声学回声消除算法在对采集到的声音进行回声消除的同时,还需要播放线程中的数据作为参考,而要同步这两个线程中的数据是非常重要的,因为稍稍有些不同步,声学回声消除算法中的自适应滤波器就会发散,不但消除不了回音,还会破坏原始采集到的声音,使声音难以分辨。
另外,pc机器的声卡种类繁多,各种各样的声卡特性进一步加剧了同步问题的复杂性。所以,同步和声卡等问题对回声消除算法的内部特性提出了更多苛刻的要求。
从上面分析来看,由于Windows平台的非实时性,基于Windows平台的回声消除技术比DSP平台要难得多。
在PC平台语音通讯领域,目前公认音质做得比较好的国外软件是Skype,记得几年前Skype一直是在用瑞典一家叫GIPS(Global IP Sound)公司的语音引擎技术。GIPS是最早介入PC平台语音通讯领域的厂商之一,在改领域具有一定的权威性,其主要优势表现在对IP网络的延时、抖动和丢包等处理较好,基于Windows平台的回音消除也做得不错,不过最近的新版本Skype上已经看不到GIPS的标志了,据说是因为Skype自己研发了一套新的更好的语音引擎的缘故。?目前大家接触最多的采用了GIPS语音引擎技术的通讯软件就是腾讯QQ了,其超级语音的效果普遍评价都还不错。另外微软经过多年的研发,其最新版本的MSN语音特别是回音消除效果终于有了质的提升,目前网上评价也还不错。另外还有一些专业厂商也对外提供包含回音消除功能的语音引擎,如俄罗斯的Spirit DSP、美国的GH Innovation和国内的科莱特斯科技(Conatus Technologies)以及赛声科技(Soft? Acoustic)等等。除此之外,网络上还可以下载到一个很好的开源的语音软件Speex也提供了回音消除功能。为了进一步了解目前PC Windows平台回音消除技术的业界水平,笔者对各家的回音消除技术做一个详细的横向对比测试(所有测试都是免提状态)
为了对比,各家语音引擎的版本信息列举如下:
? ?
国外厂商:
Skype V3.8.4.182
Spirit DSP(厂家DEMO)
GIPS(QQ 2009beta)
Micorsoft?(Windows Live Messenger 2009? V14.0.8064.2006)
GH Innovation(厂家DEMO)
? ?
国内厂商:
Conatus?Technologies(厂家DEMO)
Soft Acoustic(厂家DEMO)
开源算法:
Speex(V1.2RC1?自己写了测试软件)
? ?
测试结果:
测试项目 ?? | Skype | MSN | Conatus | Spirit | Speex | SoftAcoustic | GH I | |
笔记本免提模式,外接麦克风和音箱应用模式的适应性 | 两种模式都无回音 | 笔记本免提模式有时一直有较小回音 | 笔记本免提模式偶尔有较小回音 | 两种模式都无回音 | 笔记本免提模式有时一直有较小回音 | 两种模式都有一直较小回音 | 两种模式有时都会出现较大回音 | 笔记本免提模式一直有很小回音 |
? ? 单方讲话效果 | 无回音,效果很好 | 基本无回音,效果好 | 基本无回音,效果好 | 无回音,效果很好 | 基本无回音,效果好 | 一直有较小回音,效果差 | 有时有很大回音,效果差 | 基本无回音,效果好 |
? ? 双方同时讲话效果 | 双方交流流畅无回音,对方声音偶尔有轻微断续 | 双方交流流畅,但对方声音中会夹杂着轻微回音 | 双方交流流畅,但对方声音中会夹杂着一些回音 | 双方交流流畅无回音,对方声音偶尔有轻微断续 | 双方交流流畅,但对方声音中间会夹杂着一些回音 | 双方交流比较流畅,但一直听到一个较小的回音 | 双方交流不流畅,对方声音经常会断续 | 双方交流无回音,但对方声音很小很难听清楚 |
? ? 麦克风和扬声器相对的位置改变等 | 收敛比较快,基本没有回音出现。 | 收敛比较快,基本没有回音出现。 | 收敛比较快,基本没有回音出现。 | 收敛比较快,基本没有回音出现。 | 收敛比较快,基本没有回音出现。 | 收敛速度慢,有好几句回音 | 收敛速度慢,有好几句回音 | 收敛比较快,基本没有回音出现。 |
? ? CPU重载(CPU负载达到100%)时效果 | XP和Vista下声音都流畅,基本不会出现回音和声音断续现象 | XP和Vista下声音都流畅,基本不会出现回音和声音断续现象 | XP下声音流畅,基本不会出现回音;Vista下声音断续,偶尔会出现回音 | XP和Vista下声音都流畅,基本不会出现回音和声音断续现象 | XP下声音流畅,基本不会出现回音;Vista下声音断续,偶尔会出现回音 | 此项未测 | XP下声音流畅,基本不会出现回音;Vista下声音断续,偶尔会出现回音 | XP下声音流畅,基本不会出现回音;Vista下不加负载声音都是断续的 |
? ? PC和声卡适应性 | 稳定,基本都能消除回音 | 稳定,基本都能消除回音 | 比较稳定,偶尔有些笔记本免提时有回音 | 稳定,基本都能消除回音 | 稳定,基本都能消除回音 | 不稳定,有时无法消除回音 | 不稳定,经常无法消除回音 | 稳定,基本都能消除回音 |
? ? 噪声抑制 ? ? ? ? ?? | 噪声抑制效果弱 | 噪声抑制效果一般 | 噪声抑制效果弱 | 噪声抑制效果强 | 噪声抑制效果一般 | 噪声抑制效果强 | 噪声抑制效果强 | 噪声抑制效果强 |
自动硬件增益控制和免提时能达到的最大播放音量 | 支持,音量较大 | 支持,音量较小 | 支持,音量适中 | 支持,音量适中 | 支持,音量较小 | 不支持 | 支持,音量较小 | 支持,音量非常小 |
? ? 整体效果评价(0-10分评分) | 很好,基本没有回音,双方交流很顺畅,9分 | 较好,有的笔记本免提时偶尔有回音且音量较小,双方交流比较顺畅,7.5分 | 较好,有的笔记本免提时偶尔有回音,双方交流顺畅,8分 | 很好,基本没有回音,音量比skype略小,双方交流很顺畅,8.5分 | 较好,有的笔记本免提效果稍差且音量比较小,vista效果稍差,7分 | 不好,一直有个较小的残余回音,双方交流困难,3分 | 不好,经常有完整的回音,感觉不稳定,双方交流比较困难,5分 | 一般,没有回音,但是音量太小,双方交流困难,且VISTA下声音断续,5.5分 |
测试项目 ?? | Skype | MSN | Conatus | Spirit | Speex | SoftAcoustic | GH I |
?
可以看出,Skype、?Conatus和?QQ(GIPS)的效果最好,?MSN和Spirit的效果还不错,而GH Innovation、Soft Acoustic效果一般,Speex的效果较差。
有些声学回音消除算法在做完回音消除后,还会残余一部分回音没有彻底消除干净,这时候就需要再使用残余回音消除算法过滤掉。
线路回音是由于物理电子线路的二四线匹配耦合引起的。
?
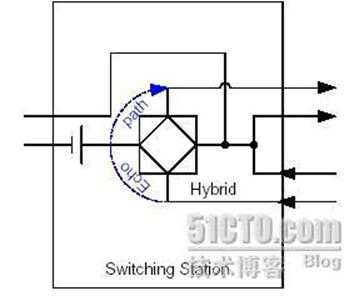
由于2-4线转换引入的线路回音:
?
在ADSL Modem和交换机上都存在2-4线转换的电路,由于电路存在不匹配的问题,会有一部分的信号被反馈回来,形成了回音。如果在交换机侧不加回音抵消功能,打电话的人就会自己听到自己的声音。
噪声抑制又称为降噪,是根据音频数据的特点,将属于环境背景噪音的部分识别出来,并从音频数据帧中过滤掉。
噪音抑制算法一般有两种,一种叫单麦克风噪音抑制,简称单麦降噪,另一种叫双麦克风噪音抑制,简称双麦降噪。
单麦克风噪音抑制算法的原理就是:将单个麦克风采样到的信号进行分析,根据一些预定义的环境背景噪音特征,对信号的内容进行匹配,然后将匹配成功的内容过滤掉。
双麦克风噪音抑制算法的原理就是:一个麦克风为普通的用户通话时使用的麦克风,用于采样语音信号,而另一个配置在机身顶端的麦克风,用于采样环境背景噪音信号,然后根据采样到的环境背景噪音信号,将语音信号中采样到的环境背景噪音过滤掉。这种算法一般只能在听筒模式下使用,不能在免提模式下使用,因为免提模式下两个麦克风采样到的信号都包含语音。
?
噪音抑制效果演示:
噪音抑制前:
噪音抑制后:
混响音产生的过程:当语音信号在封闭的房间内传播时,由于房间墙壁、室内物体的反射、吸收,语音信号会通过多种路径传达到麦克风,这时麦克风接收到的语音信号按时间先后顺序可分为三部分:直达音、早期反射音(只经过一两次的反射,能量较大、时延较短的反射音)、混响音(经过多次反射以后到达的数目众多、能量较小、时延较长的反射音群)。
早期反射音是指未达到稳定状态时的反射音,也就是在直达音之后混响音开始衰减之前的这段时间差内的反射音。直达音以后50ms以内到达的早期反射音有加强直达音和提高清晰度的作用,可以被接受作为直达音的一部分。
混响音是指早期反射音之后到达的反射音群。它会引起语音幅值的变化、相位的延时、共振峰的偏移以及产生其它的谱峰、拖尾,还会造成语言音节的相互掩蔽,从而降低了语音清晰度和可懂度。
一般在封闭的房间内使用免提打电话时,如果麦克风与声源之间的距离较远,混响音就会比较强,此时就需要做混响音消除,如果不在这种情况下打电话时就不需要做混响音消除了。
在语音对话中,要是当一方没有说话时,就不会产生流量就好了。语音活动检测就是用于这个目的的。语音活动检测通常也集成在编码模块中。语音活动检测算法结合前面的噪声抑制算法,可以识别出当前是否有语音活动,如果没有语音活动,就可以编码输出一个特殊的的编码帧(比如长度为0)。
特别是在多人视频会议中,通常只有一个人在发言,这种情况下,利用语音活动检测技术而节省带宽还是非常可观的。
自动增益控制是指,当较弱信号输入时,可以将其放大到指定幅度,当较强信号输入时,可以将其降低到到指定幅度。
由于不同设备的麦克风灵敏度不一样,导致采样到的信号幅度就会有偏大或者偏小的情况,最终播放时就会有些人声音大、有些人声音小,这种情况下通过使用自动增益控制算法,将所有人的音频信号都控制在同一级别的幅度上,这样播放时的声音都是一样大了。
不连续传输是指,在网络传输编码后的音频数据帧时,如果编码器发现某一些音频数据帧没有任何信息,编码器就会返回一个特殊值来告诉程序,程序就通过这个特殊值来判断可以不发送哪些编码后的音频数据帧,然后接收方就会误以为这些数据包都丢失了,那么接收方就会使用数据包丢失隐藏算法来猜测这些音频数据帧,由于发送方确定这些音频数据帧没有任何信息,所以猜测出来的音频数据帧也就会没有任何信息,这样就节省了网络流量。
由于网络环境可能不稳定,造成网络延迟一会大一会小,俗称网络抖动。在网络抖动情况下,通过网络传输音频数据帧时,即使发送方是定时发送音频数据帧的(比如每20ms发送一个包),接收方也无法定时收到,可能一段时间内一个包都收不到,也可能一段时间内收到好几个包,最终导致接收方播放时声音出现一卡一卡的。因此,就需要使用自适应抖动缓冲区先将接收到的音频数据帧缓冲起来,当缓冲到一定数量后,才从最老的帧一个一个依次开始取出,这样接收方听到的声音就是连续的了。
自适应抖动缓冲区的缓冲深度不是一直不变的,它取决于网络抖动的程度,当网络抖动增大时,缓冲深度就会增大,音频播放的延迟也就越大,当网络抖动减小时,缓冲深度就会减小,音频播放的延迟也就越小。所以,自适应抖动缓冲区就是利用了较高的延迟来换取声音的流畅播放,因为相比声音一卡一卡的来说,较高的延迟和流畅的声音,其主观感受要更好。
自适应抖动缓冲区还可以将乱序到达的数据重新排序
数据包丢失隐藏是指,在网络传输编码后的音频数据帧时,如果某一个编码后的音频数据帧丢失了,那么接收方可以根据曾经接收到所有音频数据帧猜测出已丢失的解码后的音频数据帧。
例如,某一个Speex格式音频数据帧丢失了,那么接收方就可以直接用Speex解码器猜测出这个已丢失的PCM格式音频数据帧。
前向纠错是指,在网络传输编码后的音频数据帧时,如果某一个编码后的音频数据帧丢失了,但其后一个编码后的音频数据帧接收到了,那么接收方可以根据后一个编码后的音频数据帧恢复出其前一个解码后的音频数据帧。
例如,某一个Opus格式音频数据帧丢失了,但其后一个Opus格式音频数据帧接收到了,那么接收方就可以用Opus解码器,根据后一个Opus格式音频数据帧恢复出其前一个PCM格式音频数据帧。
在多人语音聊天时,我们需要同时播放来自于多个人的语音数据,而声卡播放的缓冲区只有一个,所以,需要将多路语音混合成一路,这就是混音算法要做的事情。即使,你可以想办法绕开混音而让多路声音同时播放,那么对于回音消除的目的而言,也必需混音成一路播放,否则,回音消除最多就只能消除多路声音中的某一路。
混音可以在客户端进行,也可以在服务端进行(可节省下行的带宽)。如果使用了P2P通道,那么混音就只能在客户端进行了。如果是在客户端混音,通常,混音是播放之前的最后一个环节。
?
实例:
实话实说,这个混音算法是我从网上找到的,不过效果还是挺不错的,公式就是
C = A + B - (A * B >> 0x10)
A和B就是两路不同的音频数据,C就是混音后的音频数据,当然,处理后,还需要对C进行防止数据溢出的处理,否则,可能会有破音。
?
如果是16bit音频数据,就是:
?
if (C > 32767) C = 32767;
else if (C < -32768) C = -32768;
如果是float音频数据,就是:
?
if (C > 1) C = 1;
else if (C < -1) C = -1;
这个算法针对的是16bit的音频采样数据,我实验的结果是:对float音频采样数据,同样有不错的效果。
重采样是指将已采样的音频数据进行重新采样,从而改变它的采样频率。
例如,已有一段8000Hz采样频率的音频数据,但是声卡最低支持播放16000Hz采样频率的音频数据,那么就要用重采样算法将这段音频数据重采样成16000Hz。
自动语音识别,简称语音识别,就是将人类语音中的语句内容转换为计算机可显示的字符信息。
例如,有人说"拨打电话给114",计算机就会根据这段声波识别出这句的内容是"拨打电话给114",然后如果有软件设定好了"拨打电话给"这样的内容就是调用打电话接口,那么计算机就会拨号114。
语音合成,也称文语转换,就是将计算机可显示的字符信息转变为可以人类听得懂的语音。
例如,计算机中有一段字符"你好,我是人工智能机器人。",计算机就可以将这句换转换为语音信号播放出来给人类听,并且人类还可以听懂。
多速率是指允许编解码器可以在任何时候动态改变比特率。
嵌入式是指编解码器会将窄带比特流嵌入到宽带比特流中。
模数转换器、Analog to Digital Converter、ADC
数模转换器、Digital to Analog Converter、DAC
数字信号处理、Digital Signal Processing、DSP
数字信号处理器、Digital Signal Processor、DSP
声学回音消除、Acoustic Echo Cancellation、AEC
声学回音消除器、Acoustic Echo Canceller、AEC
残余回音消除、Residual Echo Cancellation、REC
残余回音消除器、Residual Echo Canceller、REC
噪音抑制、降噪、Denoise、Noise Suppression、NS
混响消除、Dereverberation、De-Reverberation、Dereverb、DR
自适应抖动缓冲区、Adaptive Jitter Buffer、AJB
自适应抖动缓冲器、Adaptive Jitter Buffer、AJB
Speex专用自适应抖动缓冲器、Speex Adaptive Jitter Buffer、SpeexAJB
预处理、Preprocess
预处理器、Preprocessor
数据包丢失隐藏、Packet Loss Concealment、PLC
非连续传输、Discontinuous transmission、DTX
强化立体声编码、Intensity Stereo Encoding、ISE
固定比特率、Constant Bit Rate、CBR
可变比特率、Variable Bit Rate、VBR
平均比特率、Average Bit Rate、ABR
非连续传输、Discontinuous transmission、DTX
定点执行、Fixed-point implementation
浮点执行、Floating-point implementation
自动增益控制、Automatic Gain Control、AGC
语音活动检测、Voice Activity Detection、VAD
多速率、multi-rate
嵌入式、Embedded
重采样、Resample
公式:20log10(abs(pcm)/pow(2, bitdeep-1)
pcm: 一个采样单元数据,-32768≤pcm≤32767
bitdeep: 位数
一款跨平台、免费开源的录音、编辑声音编辑器。Audacity让你轻松编辑音乐文件无负担,提供了理想的音乐文件功能自带的声音效果包括回声,更改节拍,减少噪音,而内建的剪辑、复制、混音与特效功能,更可满足一般的编辑需求。
Adobe Audition是专业的音频编辑工具,提供音频混合、编辑、控制和效果处理功能。它支持128条音轨、多种音频特效和多种音频格式,可以很方便地对音频文件进行修改和合并。使用它,您可轻松创建音乐、制作广播短片。该软件支持简体中文,请您在安装过程中注意选择。
RecForge II是一款最华丽音质超棒功能强大的录音机,第一代产品已经很好了,试试第二代吧,RecForge II是一个功能强大的录音机(录音机和编辑器)为Android。它允许录制,播放,编辑和共享的声音,声音,笔记,的音乐或任何其他音频媒体。
原文:http://www.cnblogs.com/gaoyaguo/p/7858025.html