一。利用cookie访问
import requests headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36‘} cookies = {‘cookie‘: ‘bid=a3MhK2YEpZw; ll="108296"; ps=y; ue="t.t.panda@hotmail.com"; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1482650884%2C%22https%3A%2F%2Fwww.so.com%2Fs%3Fie%3Dutf-8%26shb%3D1%26src%3Dhome_so.com%26q%3Dpython%2B%25E8%25B1%2586%25E7%2593%25A3%25E6%25BA%2590%22%5D; _gat_UA-7019765-1=1; ap=1; __utmt=1; _ga=GA1.2.1329310863.1477654711; dbcl2="2625855:/V89oXS4WD4"; ck=EePo; push_noty_num=0; push_doumail_num=0; _pk_id.100001.8cb4=40c3cee75022c8e1.1477654710.8.1482652441.1482639716.; _pk_ses.100001.8cb4=*; __utma=30149280.1329310863.1477654711.1482643456.1482650885.10; __utmb=30149280.19.10.1482650885; __utmc=30149280; __utmz=30149280.1482511651.7.6.utmcsr=blog.csdn.net|utmccn=(referral)|utmcmd=referral|utmcct=/alanzjl/article/details/50681289; __utmv=30149280.262; _vwo_uuid_v2=64E0E442544CB2FE2D322C59F01F1115|026be912d24071903cb0ed891ae9af65‘} url = ‘http://www.douban.com‘ r = requests.get(url, cookies = cookies, headers = headers) with open(‘douban_2.txt‘, ‘wb+‘) as f: f.write(r.content)
二。利用Xpath搜索
import requests from lxml import etree s = requests.Session() for id in range(0, 251, 25): print (id)
url = ‘https://movie.douban.com/top250/?start-‘ + str(id) r = s.get(url) r.encoding = ‘utf-8‘ root = etree.HTML(r.content) items = root.xpath(‘//ol/li/div[@class="item"]‘) //利用xpath的标签选择
# print(len(items)) for item in items: title = item.xpath(‘./div[@class="info"]//a/span[@class="title"]/text()‘)//如下找到中文名字
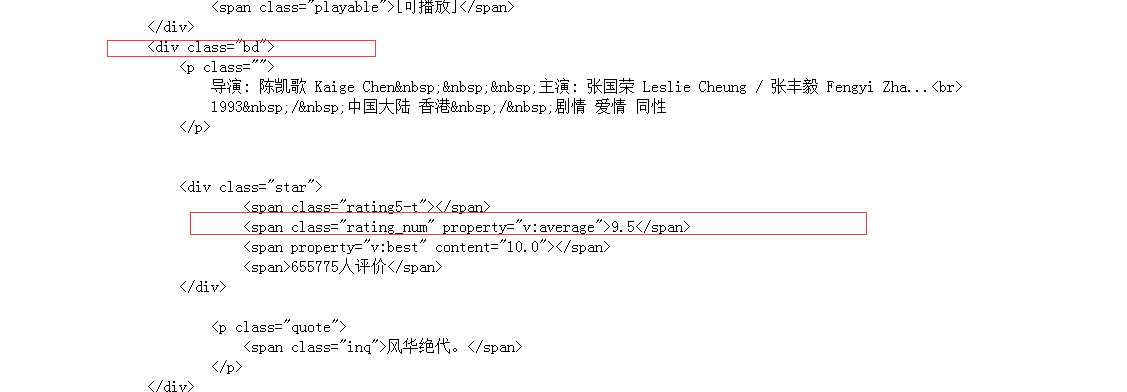
name = title[0].encode(‘gb2312‘, ‘ignore‘).decode(‘gb2312‘)//title是一个数组 先encoding 再decode确保字符不混在一起 # rank = item.xpath(‘./div[@class="pic"]/em/text()‘)[0] rating = item.xpath(‘.//div[@class="bd"]//span[@class="rating_num"]/text()‘)[0]
print(name, rating)
结果:成功爬取前250个评分
ps:必须知道网页的结构
原文:http://www.cnblogs.com/LHWorldBlog/p/7860506.html