熔断
当某个服务调用慢或者有大量超时现象(过载),系统停止后续针对该服务的调用而直接返回,直至情况好转才恢复调用。这通常是为防止造成整个系统故障而采取的一种保护措施,也称过载保护。很多时候刚开始,可能只是出现了局部小规模系统故障,但后来故障影响的范围越来越大,最终导致了全局性的后果。
限流
对某个服务调用设置最高QPS阈值,高于阈值的请求放弃调用直接返回。这种模式不能解决服务依赖的问题,只能解决系统整体资源分配问题,因为没有被限流的请求依然有可能造成雪崩效应。
限流处理方案:
1)限制用户平均发送速率为r 字节/s,则以r 个/s的速度往桶中放入令牌,即为每一个字节配备一个令牌。
2)假设桶的最大容量为b,如果令牌桶已满,则丢弃这个令牌。
3)当流入速率为v 字节/s,则从桶中取令牌的速率为v 个/s。拿到令牌的流量通过,拿不到的则执行限制逻辑。
该算法具有如下特点:
1)长期来看,流入速率受令牌添加速率的影响,被稳定为r。 2)令牌桶有一定的容量,可以抵挡一定的流量突发情况。 3)假设最大流入速率为M,则 M > r。
4)假设能承受最大流入速率M的持续时间为T,则 T = b / (M - r)。
5)假设最大流入速率M持续时间内传输的流量为B,则 B = T * M。
6)当一个n个字节大小的请求数据包到达,将从桶中删除n个令牌。但如果桶中余下令牌不足n个,
则不会删除令牌,该请求将被限流(要么丢弃,要么缓冲区等待)。
7)当r极大,如r > 1000时,也就是匀速放一个令牌的时间间隔是小于1 ms的,这个精度不好控制;
可以采用流入事件触发方式来添加令牌,即下一个请求到来会先计算当前时间到上一次添加令
牌时间这个时间段内应该添加的令牌数(取整数部分),然后添加完令牌再决定通过或限制当前请求,
这样依然可以维持整体流入速率稳定在r。
该算法具有的优点:
1)流量比较平滑,并且可以抵挡一定的流量突发情况。
1)一个固定容量的漏桶,以恒定的速率流出。 2)如果漏桶是空的,则不需流出。 3)如果流入超出了漏桶的容量,则溢出(被丢弃)。
该算法具有的优点:
1)该算法可平滑突发流量,是消灭突发状况的有效坚决办法。
限流可以在应用层实现,也可以在接入层实现,通常使用redis + lua或者nginx + lua来实现。
降级
当访问量剧增致服务出现问题(如响应时间慢或不响应),或非核心服务影响到核心流程的性能时,仍要保证服务是可用的;即使是有损的,且有些服务是无法降级的,如加入购物车、结算等。降级可以是自动降级或人工降级,可以是读服务降级或写服务降级,还可以是多级降级。自动降级可根据系统负载、资源使用情况、调用超时、失败重试次数、故障、限流阀值、SLA(Service-Level Agreement)等指标进行降级。
降级处理方案:
降级发生场景:
在大促活动期间,对某些占用了稀缺资源的次要页面或片段调用降级,同时也对爬虫返回静态页或者空数据,以保证核心业务正常开展。
隔离
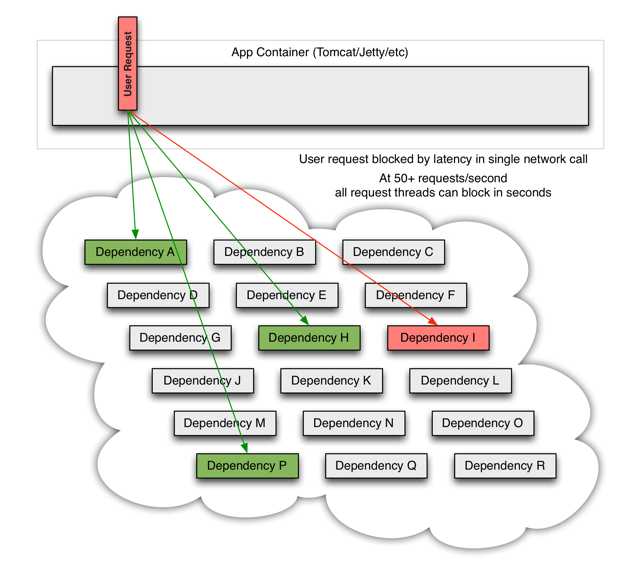
下图展示了非隔离状态下单个用户请求被服务依赖I阻塞的情况:
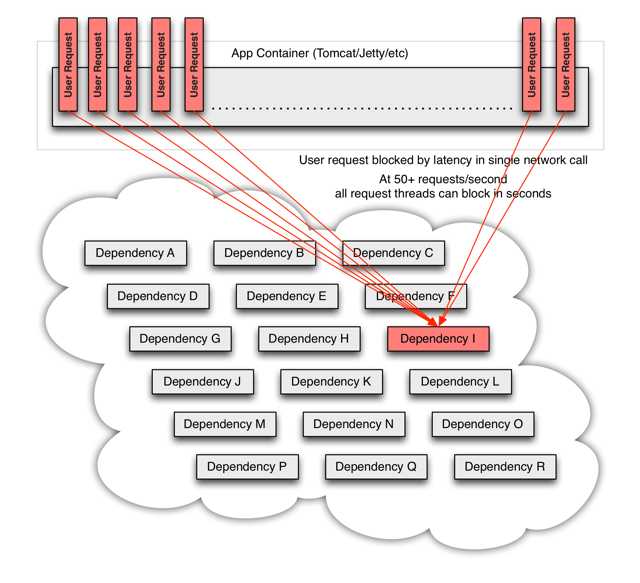
下图展示了非隔离状态下服务依赖I阻塞了全部用户请求,而其他用户请求此时根本没有机会接受线程池的处理:
对请求按类型划分并分配不同数量的线程池来隔离处理,各自互不影响。当某个请求类型的线程池资源耗尽,则后续该类型请求可停止处理而直接返回,不影响其他请求类型线程的正常执行;这就避免了,非隔离状态下慢服务阻塞所有用户请求导致整个线程池处理能力下降。
Hystrix 是一个解决分布式系统交互超时处理和容错的类库,是 Netflix 的众多开源项目之一。Hystrix 采用线程池和信号量两种隔离方式,来限制并发访问量和故障扩散。
缓存
缓存通常用来加速数据访问,但缓存在大面积失效或负载过大或重启之后,导致数据访问穿透到DB,依然可能引起雪崩效应的发生。
原文:http://www.cnblogs.com/XiongMaoMengNan/p/7900405.html