ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks
Convolutional neural networks are fantastic for visual recognition tasks. Good ConvNets are beasts with millions of parameters and many hidden layers. In fact, a bad rule of thumb is: ‘higher the number of hidden layers, better the network’. AlexNet, VGG, Inception, ResNet are some of the popular networks. Why do these networks work so well? How are they designed? Why do they have the structures they have? One wonders. The answer to these questions is not trivial and certainly, can’t be covered in one blog post. However, in this blog, I shall try to discuss some of these questions. Network architecture design is a complicated process and will take a while to learn and even longer to experiment designing on your own. But first, let’s put things in perspective:

图像识别(Image classification)的任务是将给定的图像正确的分类为预先定义的种类。传统方法,将该过程分为两个模块:feature extraction 以及 classification。
Feature Extraction:involves extracting a higher level of information from raw pixel values that can capture the distinction among the categories involved. This feature extraction is done in an unsupervised manner wherein the classes of the image have nothing to do with information extracted from pixels. Some of the traditional and widely used features are GIST, HOG, SIFT, LBP etc. After the feature is extracted, a classification module is trained with the images and their associated labels. A few examples of this module are SVM, Logistic Regression, Random Forest, decision trees etc.
但是这个流程的问题在于:特征提取的过程无法根据 classes 和 images 进行微调(the feature extraction cannot be tweaked according to the classes and images)。所以,如果这个选中的特征缺乏表达性来区分种类,模型分类的准确度可定不会很好,不管你采用哪种分类的策略。A common theme among the state of the art following the traditional pipeline has been, to pick multiple feature extractors and club them inventively to get a better feature. But this involves too many heuristics as well as manual labor to tweak parameters according to the domain to reach a decent level of accuracy. By decent I mean, reaching close to human level accuracy. That’s why it took years to build a good computer vision system(like OCR, face verification, image classifiers, object detectors etc), that can work with a wide variety of data encountered during practical application, using traditional computer vision. We once produced better results using ConvNets for a company(a client of my start-up) in 6 weeks, which took them close to a year to achieve using traditional computer vision.
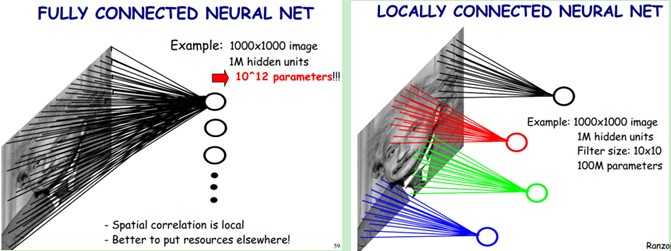
In order to understand the design philosophy of ConvNets, one must ask: What is the objective here ?
a. Accuracy :
If you are building an intelligent machine, it is absolutely critical that it must be as accurate as possible. One fair question to ask here is that ‘accuracy not only depends on the network but also on the amount of data available for training’. Hence, these networks are compared on a standard dataset called ImageNet.
ImageNet project is an ongoing effort and currently has 14,197,122 images from 21841 different categories. Since 2010, ImageNet has been running an annual competition in visual recognition where participants are provided with 1.2 million images belonging to 1000 different classes from Imagenet data-set. So, each network architecture reports accuracy using these 1.2 million images of 1000 classes.
b. Computation:
Most ConvNets have huge memory and computation requirements, especially while training. Hence, this becomes an important concern. Similarly, the size of the final trained model becomes an important to consider if you are looking to deploy a model to run locally on mobile. As you can guess, it takes a more computationally intensive network to produce more accuracy. So, there is always a trade-off between accuracy and computation.
Apart from these, there are many other factors like ease of training, the ability of a network to generalize well etc. The networks described below are the most popular ones and are presented in the order that they were published and also had increasingly better accuracy from the earlier ones.
AlexNet

f(x) = max(0,x)


Why does DropOut work?
The idea behind the dropout is similar to the model ensembles. Due to the dropout layer, different sets of neurons which are switched off, represent a different architecture and all these different architectures are trained in parallel with weight given to each subset and the summation of weights being one. For n neurons attached to DropOut, the number of subset architectures formed is 2^n. So it amounts to prediction being averaged over these ensembles of models. This provides a structured model regularization which helps in avoiding the over-fitting. Another view of DropOut being helpful is that since neurons are randomly chosen, they tend to avoid developing co-adaptations among themselves thereby enabling them to develop meaningful features, independent of others.
