背景
随着队列技术越来越成熟,很多公司都把MQ放入其技术栈中,线上也基本都运行着该组件。接下来我们一起讨论下,当使用MQ后,你该如何分析线上问题?这里给出两个名词解释,“推”:指常用的RPC调用,“拉”:使用队列进行消息传递。
示例架构
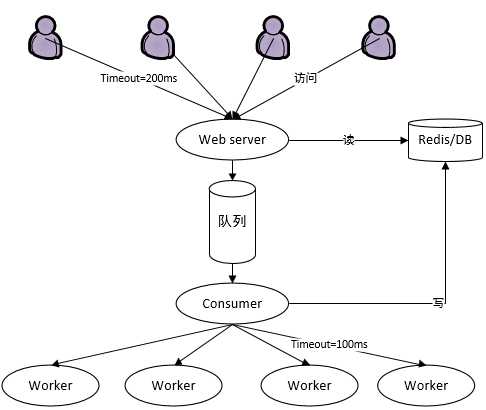
如上图一个普通的服务架构,图中有多个要素,下面对这几个要素进行详细说明。
- 用户 网站的使用者,他会有奇怪的行为:当迟迟看不到结果页面时,会反复刷新浏览器。
- webserver 与用户进行交互的服务。它把用户请求写入mq,并从redis/DB中读取结果渲染成页面返回给用户。
- 队列 缓冲用户请求,方便下游服务横向扩展。
- consumer 消息的消费者。它会有一些处理逻辑:调用(本例使用的rpc是thrift)下游的服务(worker)完成一些计算型任务,把最终处理结果写入redis/DB中。 consumer调用下游的服务有超时时间设置,如果下游服务在指定timeout时间内没有返回结果,consumer会选择(随机或者顺序)其它服务重试。
- worker 本例是一些计算型服务,会消耗cpu。
这个是典型的线上系统:某些地方使用队列缓冲请求,但由于历史问题、技术风险、实现复杂性高等原因又不能使每个服务都用队列串联。我们用这个架构进行说明,看看当出现如下问题时,会从监控上看到什么样的表现?系统又会有哪些违反常理的行为?而我们又该如何分析问题。
用户请求量过大,worker计算能力跟不上
- 现象1: 通过监控看worker的cpu,使用率接近100%。
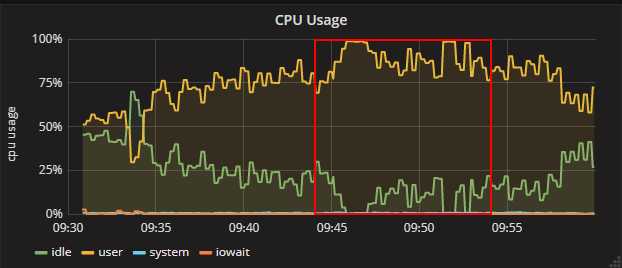
- 现象2:查看consumer日志,发现大量的请求超时。

20分钟内有1K+多超时错误,后端服务处于“崩溃临界点”边缘。 - 现象3:队列中tot(ready+unack)数会突增(浅蓝色)。
“相对论”与“系统崩溃临界点”
就如物理学相对论中的“运动的尺子会变短”,我们提出计算机系统中的“相对论”:对于一个系统,当并发请求量变大时,每个请求的处理时间会变长。
我们利用“相对论”就能推导出每个二级系统都有崩溃临界点:两个服务A,B都遵循相对论,A调用B有超时重试策略;当A加大调用B的并发量后,B遵循“相对论”会使得每个请求的处理时间都变长。当请求量大到一定值后,B服务的处理时间会超过设定的“超时时间”,此时系统中就只有重试请求,并且每次请求都超时,这个“一定值”就是系统崩溃临界点。
本例展示的这种情况,总体来说对外造成的影响不严重,系统压力已经达到最大,接近崩溃边缘但是没有引发雪崩,因为还没有造成用户频繁刷新行为:橙色那条线(用户请求速率)比较平稳。这个时候只需要增加worker的机器数即可。
consumer数过少
这种情况分析起来稍微复杂,监控结果比较诡异。
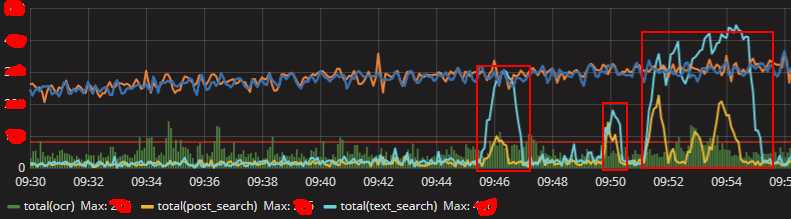
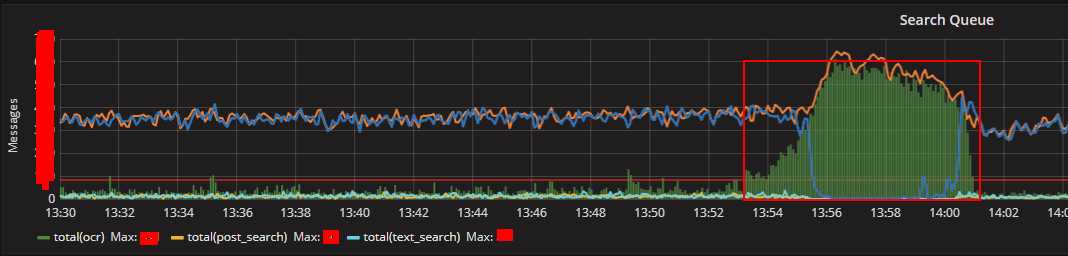
- MQ监控中橙色那条线(代表用户请求速率)突增,并且此刻队列中积压的消息数也很大(绿色的柱状图)。
- 观察consumer日志,请求超时数很少。

10分钟内只有6次超时,和请求基数比较可以忽略不计,应该不是后端性能处理跟不上。为了确认,顺便看看后端的cpu使用率,如下图。 - 后端woker的cpu使用率并没有达到100%。
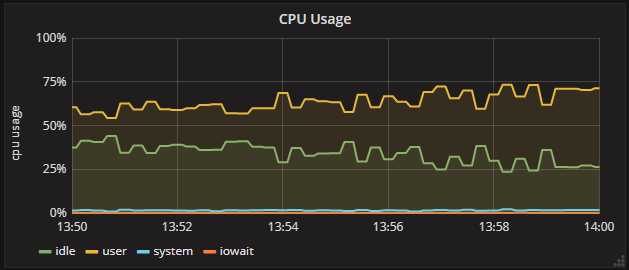
cpu使用率为75%,离崩溃时100%还相差25%。
鸡生蛋还是蛋生鸡
这种情况下,通常会有两个结论:
- 鸡生蛋:由于用户请求突然增加(未知原因),系统处理能力跟不上瞬时增加请求,消息大量积压在队列中。
这种结论通常都是第一反应,如果不仔细思考可能就会把这种结论作为最终结论,并且轻轻松松把锅踢给了用户群体,何乐而不为? - 蛋生鸡:由于系统某些环节达到瓶颈,造成消息处理的速率跟不上用户的请求速率,消息积压过多;而消息积压过多,又导致系统对用户的响应变慢(主要是对后进入到队列中的消息的响应),超过了用户忍受的时间,用户采取频繁刷新浏览器行为;用户频繁刷新又造成队列中进入的消息速率瞬间提高,而提高的速率又加剧消息的积压,导致更多用户采取刷新行为......滚雪球一般。
这是比较冷静不怕承担责任的分析,自己挖的坑跪着也要填完。
这两个结论到底孰对孰错?显然,第二种结论是对的。
第一种为啥是错的咧?
如果是第一种情况,系统某些地方肯定会表现出异常,诸如超时异常、cpu飙高异常,而本例中统统木有。
第二种为啥是对的咧?
- 首先看MQ的积压消息数(绿色柱状图),用户采取刷新行为前(橙色线突增之前)积压的消息数是逐渐增加的(前期预兆,系统某个地方有瓶颈),消息积压过多后导致后进入的请求得到响应的时间变慢(队列基本上是先进先出策略),这部分用户不能忍受长时间等待便采取刷新行为(橙色线突增),与我们的理论分析一致。
- 其次观看下游服务的cpu,使用率没有因为用户频繁刷新而瞬间飙高(如果系统没有瓶颈,突增的的流量会使cpu瞬间飙高到100%)。
- 综上所述,可以推测系统瓶颈在MQ之后,在后端服务之前,这中间的服务只有consumer,最后的结论是consumer数太少。
如何设置服务参数?
- consumer数:压力测试时,能够把后端cpu使用率压到90+%并且不会有大量超时异常为止。
- timeout:压力测试时,cpu使用率到90%+,统计单次请求时间分布,取90分位(具体可上下浮动)。
这里只是参数设置建议,实际工作中需要根据具体情况具体分析。但是总体应该遵循:在用户容忍响应时间内达到吞吐量最大化。
总结
遇到线上问题时最忌慌乱,人在慌乱的时候通常会采取错误的处理方式,加剧问题的影响面,所以理智应该排在第一位。在我以前的工作中,每次遇到线上问题,都会有一大群人在那里“叭叭叭”个没完,看似自己在分析问题中有着不小的作用,但是真正发现问题原因的往往是那些一言不发理智观察分析各种监控数据的人。希望每个小伙伴都不会遇到突发的线上问题,但是问题来了我们也不怕线上问题。