一、bytes类型
二、三元运算
|
1 |
result = 值1 if 条件 else 值2 |
如果条件为真:result = 值1
如果条件为假:result = 值2
三、进制
- 二进制,01
- 八进制,01234567
- 十进制,0123456789
- 十六进制,0123456789ABCDEF 二进制到16进制转换http://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1
计算机内存地址和为什么用16进制?
为什么用16进制
1、计算机硬件是0101二进制的,16进制刚好是2的倍数,更容易表达一个命令或者数据。十六进制更简短,因为换算的时候一位16进制数可以顶4位2进制数,也就是一个字节(8位进制可以用两个16进制表示)
2、最早规定ASCII字符集采用的就是8bit(后期扩展了,但是基础单位还是8bit),8bit用2个16进制直接就能表达出来,不管阅读还是存储都比其他进制要方便
3、计算机中CPU运算也是遵照ASCII字符集,以16、32、64的这样的方式在发展,因此数据交换的时候16进制也显得更好
4、为了统一规范,CPU、内存、硬盘我们看到都是采用的16进制计算
16进制用在哪里
1、网络编程,数据交换的时候需要对字节进行解析都是一个byte一个byte的处理,1个byte可以用0xFF两个16进制来表达。通过网络抓包,可以看到数据是通过16进制传输的。
2、数据存储,存储到硬件中是0101的方式,存储到系统中的表达方式都是byte方式
3、一些常用值的定义,比如:我们经常用到的html中color表达,就是用的16进制方式,4个16进制位可以表达好几百万的颜色信息。
四、一切皆对象
对于Python,一切事物都是对象,对象基于类创建
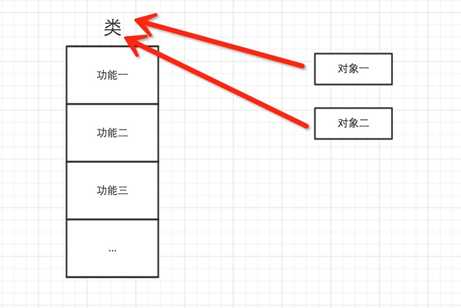
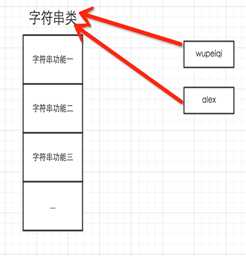
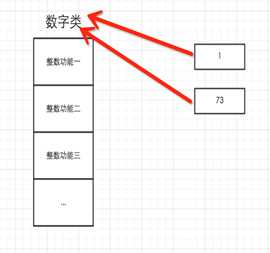
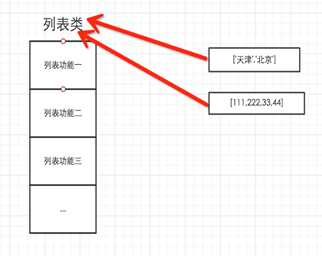
所以,以下这些值都是对象: "wupeiqi"、38、[‘北京‘, ‘上海‘, ‘深圳‘],并且是根据不同的类生成的对象。
pyCharm中python2.7与3.5版本的切换
切换py版本
file -> settings ->project interpreter ->选择版本
程序复制用ctrl+d
前面都加# ,ctrl+?
取消 ctrl+z
要想密码是密文,就要借助python的
在pycharm输入:
import getpass
# name = input(‘Input your name:‘)
# age = input(‘Input your age:‘)
#
# print(name,age)
username = input ("username:")
password = getpass.getpass ("password:")
.是调用getpass的功能
发现密码还是看到的,但是在电脑运行输入CMD,输入:
C:\Users\user\Python36>python C:\Users\user\PycharmProjects\py_fullstack_s4\20180106\交互程序.py
执行成功

查看数据类型
Pirnt(type(name),type(age))
同一个数据类型的数据可以相加或比较,否则不能
转换类型int()
str()
ASCII 256 8位
二进制位就是8位8bits
1 2 4 8 16 32 64 128 256
1 1 1 1 1 1 1 1 1
1字节=8位=8bits=1Byte
1024 Byte=1KB
1024KB=1MB=100万字节=100万字符
1024MB=1GB=一部高清短片
1024GB=1TB
1024TB=1PB
1个二进制是计算机里最小的表示单元
1个字节是计算机里最小的存储单位
Unicode 万国码
占32位 utf-32 =4字节
由于占了太多
Utf-8=8bits 可变长编码
这样英文占一个字节,中文3个字节
欧洲2个字节
#是整行注释,不执行
"""是多行注释,把里面的都变成字符串
单引号和双引号没区别,只适用于单行,3个引号能用于多行字符串或注释
数值类型
Str 字符
数字类型
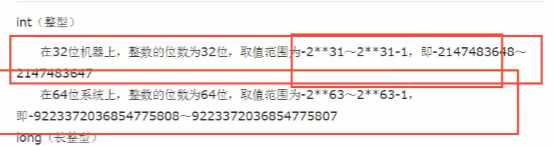
Int 整型
Long 长整型 2**32结果自动带L(32位硬盘或32位的软件,都会出现2**32结果自动带L,只有同时都是64位,才不会带L)
Float浮点型
复数
布尔分布
条件成立 true
条件不成立,false
字符串常用功能:
name = "\n\t jensen xie \t"
print(name)
print(name.strip()) #脱掉,把前后的空格,\t\n脱掉
print(name.split()) #分割,把一个字符默认按空格分割为列表类型
name = "\n\t jensen xie;alex li \t"
print(name.split(";")) #分割,把一个字符默认按空格分割为列表类型,可以指定分隔符
print(len(name)) # 长度
name1="jensen,zhicong,lizhi"
print(name1.index("h")) # 索引
# 只提取字符串中一部分信息,叫切片
print(name1[0:6])
print(name1[7:14])
print(name1[-5:])
print(name1[0::2]) #2是切的步长
print(name1[0::1])
#2是切的步长
替换
name = ["a","b","c","d","e"]
print(name)
print(name.index("d"))
name[name.index("d")]="dd"
print(name)
name = [] #列表
print(name)
print(type(name))
name = ["苏豪之","秦臻","李志","李志","燕子"]
print(name)
print(name[-1])
print(name.index("李志")) #查询李志的所在位置,元素的下标
# 想取秦臻后面的所有
print(name[1:])
# 统计多少个李志
print(name.count("李志"))
# 追加
name.append("光头")
print(name)
# 插入,在第2个后面
name.insert(2,"玉米")
print(name)
# 删除第4个
print(name.pop(2))
print(name)