五周第五次课(1月12日)
8.10 shell特殊符号cut命令
8.11 sort_wc_uniq命令
8.12 tee_tr_split命令
8.13 shell特殊符号
相关测验题目:http://ask.apelearn.com/question/5437
扩展
1. source exec 区别 http://alsww.blog.51cto.com/2001924/1113112
2. Linux特殊符号大全http://ask.apelearn.com/question/7720
3. sort并未按ASCII排序 http://blog.csdn.net/zenghui08/article/details/7938975
1. 特殊符号
* 任意个任意字符
*代表零个或多个任意字符
? 任意一个字符
?只代表一个任意的字符
# 注释字符
表示注释说明,即#后面的内容都会被忽略
\ 脱义字符
这个字符会将后面的特殊符号 (如*) 还原为普通字符
|
管道福
这个字符前面曾多次出现过,它的作用是将前面命令的输出作为后面命令的输人。这里提到的后面的命令,并不是所有的命令都可以的,一般针对文档操作的命令比较常用。例如cat、less、head, tail、grep、cut、sort、wc、uniq、tee、tr、split、sed、awk等,其中grep、sed和awk是正则表达式,必须掌握的工具
2.cut命令
cut命令用来显示行中的指定部分,删除文件中指定字段。cut经常用来显示文件的内容,类似于下的type命令。
说明:该命令有两项功能,其一是用来显示文件的内容,它依次读取由参数file所指 明的文件,将它们的内容输出到标准输出上;其二是连接两个或多个文件,如cut fl f2 > f3将把文件fl和几的内容合并起来,然后通过输出重定向符“>”的作用,将它们放入文件f3中。
当文件较大时,文本在屏幕上迅速闪过(滚屏),用户往往看不清所显示的内容。因此,一般用more等命令分屏显示。为了控制滚屏,可以按Ctrl+S键,停止滚屏;按Ctrl+Q键可以恢复滚屏。按Ctrl+C(中断)键可以终止该命令的执行,并且返回Shell提示符状态。
语法
cut(选项)(参数)
选项
-b:仅显示行中指定直接范围的内容;
-c:仅显示行中指定范围的字符;
-d:指定字段的分隔符,默认的字段分隔符为“TAB”;
-f:显示指定字段的内容;
-n:与“-b”选项连用,不分割多字节字符;
--complement:补足被选择的字节、字符或字段;
--out-delimiter=<字段分隔符>:指定输出内容是的字段分割符;
--help:显示指令的帮助信息;
--version:显示指令的版本信息。
参数
文件:指定要进行内容过滤的文件。
实例
例如有一个学生报表信息,包含No、Name、Mark、Percent:
[root@localhost text]# cat test.txt
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98
使用 -f 选项提取指定字段:
[root@localhost text]# cut -f 1 test.txt
No
01
02
03
[root@localhost text]# cut -f2,3 test.txt
Name Mark
tom 69
jack 71
alex 68
--complement 选项提取指定字段之外的列(打印除了第二列之外的列):
[root@localhost text]# cut -f2 --complement test.txt
No Mark Percent
01 69 91
02 71 87
03 68 98
使用 -d 选项指定字段分隔符:
[root@localhost text]# cat test2.txt
No;Name;Mark;Percent
01;tom;69;91
02;jack;71;87
03;alex;68;98
[root@localhost text]# cut -f2 -d";" test2.txt
Name
tom
jack
alex
指定字段的字符或者字节范围
cut命令可以将一串字符作为列来显示,字符字段的记法:
N-:从第N个字节、字符、字段到结尾;
N-M:从第N个字节、字符、字段到第M个(包括M在内)字节、字符、字段;
-M:从第1个字节、字符、字段到第M个(包括M在内)字节、字符、字段。
上面是记法,结合下面选项将摸个范围的字节、字符指定为字段:
-b 表示字节;
-c 表示字符;
-f 表示定义字段。
示例
[root@localhost text]# cat test.txt
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
打印第1个到第3个字符:
[root@localhost text]# cut -c1-3 test.txt
abc
abc
abc
abc
abc
打印前2个字符:
[root@localhost text]# cut -c-2 test.txt
ab
ab
ab
ab
ab
打印从第5个字符开始到结尾:
[root@localhost text]# cut -c5- test.txt
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
-
2. wc命令用于统计文档的行数、字符数或词数。
常用选项
-l:统计行数
-m:统计字衣数
-w:统计词数
不跟任何选项,直接跟文档,则会把行数、词数和字符数依次输出
3. uniq命令用来删除重复的行,该命令只有- c选项比较常用,它表示统计重复的行数,并把行数写在前面
去重要有条件的,先排除,才能去重
8.12 tee_tr_split命令
1. 命令tee 和>类似,重定向的同时还在屏幕显示,该命令常用于管道符 | 后。
有2层含义:先重定向,再把管道前面的结果打印在屏幕上。
清空a.txt,就用命令【>】可以了
选项“-a“就是追加
2. tr命令用于替换字符,常用来处理文档中出现的特殊符号。
该命令常用的选项有以下两个。
-d:表示删除某个字符,后面跟要删除的字符。
-s:表示删除重复的字符。
3. split命令用于切割文档
常用的选项
-b:表示依据大小来分割文档,单位为byte
-l:表示依据行数来分割文档
如果split不指定目标文件名,则会以xaa、xab…..这样的文件名来存取切割后的文件。当然,我们也可以指定目标文件
wc命令:
用来计算数字。利用wc指令我们可以计算文件的Byte数、字数或是列数,若不指定文件名称,或是所给予的文件名为“-”,则wc指令会从标准输入设备读取数据。
语法
wc(选项)(参数)
选项
-c或--bytes或——chars:只显示Bytes数;
-l或——lines:只显示列数;
-w或——words:只显示字数。
参数
文件:需要统计的文件列表。
8.13 shell特殊符号下
$ 变量前缀,!$组合,正则里面表示行尾
;多条命令写到一行,用分号分割.
~ 用户家目录,后面正则表达式表示匹配符
& 放到命令后面,会把命令丢到后台
重定向符号>; >>; 2>; 2>>; &>
[ ] 指定字符中的一个,[0-9],[a-zA-Z],[abc]
|| 和 && ,用于命令之间
command1;command2 :使用;时,不管command1是否执行成功,都会执行command2。
command1 && command2 :使用&&时,只有command1执行成功后,command2才会执行,否则command2不执行。
command1 | | command2:使用 | | 时,command1执行成功后则command2不执行,否则执行command2,即command1和command2中总有一条命令会执行。
sort命令:
是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出。sort命令既可以从特定的文件,也可以从stdin中获取输入。
语法
sort(选项)(参数)
选项
-b:忽略每行前面开始出的空格字符;
-c:检查文件是否已经按照顺序排序;
-d:排序时,处理英文字母、数字及空格字符外,忽略其他的字符;
-f:排序时,将小写字母视为大写字母;
-i:排序时,除了040至176之间的ASCII字符外,忽略其他的字符;
-m:将几个排序号的文件进行合并;
-M:将前面3个字母依照月份的缩写进行排序;
-n:依照数值的大小排序;
-o<输出文件>:将排序后的结果存入制定的文件;
-r:以相反的顺序来排序;
-t<分隔字符>:指定排序时所用的栏位分隔字符;
+<起始栏位>-<结束栏位>:以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
参数
文件:指定待排序的文件列表。
实例
sort将文件/文本的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
[root@mail text]# cat sort.txt
aaa:10:1.1
ccc:30:3.3
ddd:40:4.4
bbb:20:2.2
eee:50:5.5
eee:50:5.5
[root@mail text]# sort sort.txt
aaa:10:1.1
bbb:20:2.2
ccc:30:3.3
ddd:40:4.4
eee:50:5.5
eee:50:5.5
忽略相同行使用-u选项或者uniq:
[root@mail text]# cat sort.txt
aaa:10:1.1
ccc:30:3.3
ddd:40:4.4
bbb:20:2.2
eee:50:5.5
eee:50:5.5
[root@mail text]# sort -u sort.txt
aaa:10:1.1
bbb:20:2.2
ccc:30:3.3
ddd:40:4.4
eee:50:5.5
或者
[root@mail text]# uniq sort.txt
aaa:10:1.1
ccc:30:3.3
ddd:40:4.4
bbb:20:2.2
eee:50:5.5
sort的-n、-r、-k、-t选项的使用:
[root@mail text]# cat sort.txt
AAA:BB:CC
aaa:30:1.6
ccc:50:3.3
ddd:20:4.2
bbb:10:2.5
eee:40:5.4
eee:60:5.1
#将BB列按照数字从小到大顺序排列:
[root@mail text]# sort -nk 2 -t: sort.txt
AAA:BB:CC
bbb:10:2.5
ddd:20:4.2
aaa:30:1.6
eee:40:5.4
ccc:50:3.3
eee:60:5.1
#将CC列数字从大到小顺序排列:
[root@mail text]# sort -nrk 3 -t: sort.txt
eee:40:5.4
eee:60:5.1
ddd:20:4.2
ccc:50:3.3
bbb:10:2.5
aaa:30:1.6
AAA:BB:CC
# -n是按照数字大小排序,-r是以相反顺序,-k是指定需要爱排序的栏位,-t指定栏位分隔符为冒号
-k选项的具体语法格式:
-k选项的语法格式:
FStart.CStart Modifie,FEnd.CEnd Modifier
-------Start--------,-------End--------
FStart.CStart 选项 , FEnd.CEnd 选项
这个语法格式可以被其中的逗号,分为两大部分,Start部分和End部分。Start部分也由三部分组成,其中的Modifier部分就是我们之前说过的类似n和r的选项部分。我们重点说说Start部分的FStart和C.Start。C.Start也是可以省略的,省略的话就表示从本域的开头部分开始。FStart.CStart,其中FStart就是表示使用的域,而CStart则表示在FStart域中从第几个字符开始算“排序首字符”。同理,在End部分中,你可以设定FEnd.CEnd,如果你省略.CEnd,则表示结尾到“域尾”,即本域的最后一个字符。或者,如果你将CEnd设定为0(零),也是表示结尾到“域尾”。
从公司英文名称的第二个字母开始进行排序:
$ sort -t ‘ ‘ -k 1.2 facebook.txt
baidu 100 5000
sohu 100 4500
google 110 5000
guge 50 3000
使用了-k 1.2,表示对第一个域的第二个字符开始到本域的最后一个字符为止的字符串进行排序。你会发现baidu因为第二个字母是a而名列榜首。sohu和 google第二个字符都是o,但sohu的h在google的o前面,所以两者分别排在第二和第三。guge只能屈居第四了。
只针对公司英文名称的第二个字母进行排序,如果相同的按照员工工资进行降序排序:
$ sort -t ‘ ‘ -k 1.2,1.2 -nrk 3,3 facebook.txt
baidu 100 5000
google 110 5000
sohu 100 4500
guge 50 3000
由于只对第二个字母进行排序,所以我们使用了-k 1.2,1.2的表示方式,表示我们“只”对第二个字母进行排序。(如果你问“我使用-k 1.2怎么不行?”,当然不行,因为你省略了End部分,这就意味着你将对从第二个字母起到本域最后一个字符为止的字符串进行排序)。对于员工工资进行排 序,我们也使用了-k 3,3,这是最准确的表述,表示我们“只”对本域进行排序,因为如果你省略了后面的3,就变成了我们“对第3个域开始到最后一个域位置的内容进行排序” 了。
uniq命令:
uniq命令用于报告或忽略文件中的重复行,一般与sort命令结合使用。
语法
uniq(选项)(参数)
选项
-c或——count:在每列旁边显示该行重复出现的次数;
-d或--repeated:仅显示重复出现的行列;
-f<栏位>或--skip-fields=<栏位>:忽略比较指定的栏位;
-s<字符位置>或--skip-chars=<字符位置>:忽略比较指定的字符;
-u或——unique:仅显示出一次的行列;
-w<字符位置>或--check-chars=<字符位置>:指定要比较的字符。
参数
输入文件:指定要去除的重复行文件。如果不指定此项,则从标准读取数据;
输出文件:指定要去除重复行后的内容要写入的输出文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)。
实例
删除重复行:
uniq file.txt
sort file.txt | uniq
sort -u file.txt
只显示单一行:
uniq -u file.txt
sort file.txt | uniq -u
统计各行在文件中出现的次数:
sort file.txt | uniq -c
在文件中找出重复的行:
sort file.txt | uniq -d
tee命令: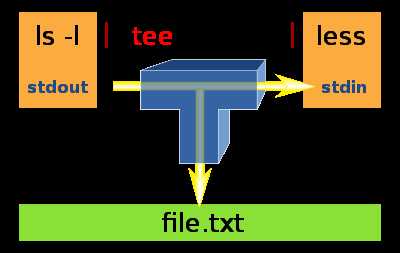
tee命令用于将数据重定向到文件,另一方面还可以提供一份重定向数据的副本作为后续命令的stdin。简单的说就是把数据重定向到给定文件和屏幕上。
存在缓存机制,每1024个字节将输出一次。若从管道接收输入数据,应该是缓冲区满,才将数据转存到指定的文件中。若文件内容不到1024个字节,则接收完从标准输入设备读入的数据后,将刷新一次缓冲区,并转存数据到指定文件。
语法
tee(选项)(参数)
选项
-a:向文件中重定向时使用追加模式;
-i:忽略中断(interrupt)信号。
参数
文件:指定输出重定向的文件。
在终端打印stdout同时重定向到文件中:
ls | tee out.txt
1.sh
1.txt
2.txt
eee.tst
EEE.tst
one
out.txt
string2
www.pdf
WWW.pdf
WWW.pef
[root@localhost text]# ls | tee out.txt | cat -n
1 1.sh
2 1.txt
3 2.txt
4 eee.tst
5 EEE.tst
6 one
7 out.txt
8 string2
9 www.pdf
10 WWW.pdf
11 WWW.pef
tr命令:
tr命令可以对来自标准输入的字符进行替换、压缩和删除。它可以将一组字符变成另一组字符,经常用来编写优美的单行命令,作用很强大。
语法
tr(选项)(参数)
选项
-c或——complerment:取代所有不属于第一字符集的字符;
-d或——delete:删除所有属于第一字符集的字符;
-s或--squeeze-repeats:把连续重复的字符以单独一个字符表示;
-t或--truncate-set1:先删除第一字符集较第二字符集多出的字符。
参数
字符集1:指定要转换或删除的原字符集。当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集。但执行删除操作时,不需要参数“字符集2”;
字符集2:指定要转换成的目标字符集。
实例
将输入字符由大写转换为小写:
echo "HELLO WORLD" | tr ‘A-Z‘ ‘a-z‘
hello world
‘A-Z‘ 和 ‘a-z‘都是集合,集合是可以自己制定的,例如:‘ABD-}‘、‘bB.,‘、‘a-de-h‘、‘a-c0-9‘都属于集合,集合里可以使用‘\n‘、‘\t‘,可以可以使用其他ASCII字符。
使用tr删除字符:
echo "hello 123 world 456" | tr -d ‘0-9‘
hello world
将制表符转换为空格:
cat text | tr ‘\t‘ ‘ ‘
字符集补集,从输入文本中将不在补集中的所有字符删除:
echo aa.,a 1 b#$bb 2 c*/cc 3 ddd 4 | tr -d -c ‘0-9 \n‘
1 2 3 4
此例中,补集中包含了数字0~9、空格和换行符\n,所以没有被删除,其他字符全部被删除了。
用tr压缩字符,可以压缩输入中重复的字符:
echo "thissss is a text linnnnnnne." | tr -s ‘ sn‘
this is a text line.
巧妙使用tr做数字相加操作:
echo 1 2 3 4 5 6 7 8 9 | xargs -n1 | echo $[ $(tr ‘\n‘ ‘+‘) 0 ]
删除Windows文件“造成”的‘^M‘字符:
cat file | tr -s "\r" "\n" > new_file
或
cat file | tr -d "\r" > new_file
tr可以使用的字符类:
[:alnum:]:字母和数字
[:alpha:]:字母
[:cntrl:]:控制(非打印)字符
[:digit:]:数字
[:graph:]:图形字符
[:lower:]:小写字母
[:print:]:可打印字符
[:punct:]:标点符号
[:space:]:空白字符
[:upper:]:大写字母
[:xdigit:]:十六进制字符
使用方式:
tr ‘[:lower:]‘ ‘[:upper:]‘
split命令:
split命令可以将一个大文件分割成很多个小文件,有时需要将文件分割成更小的片段,比如为提高可读性,生成日志等。
选项
-b:值为每一输出档案的大小,单位为 byte。
-C:每一输出档中,单行的最大 byte 数。
-d:使用数字作为后缀。
-l:值为每一输出档的列数大小。
实例
生成一个大小为100KB的测试文件:
[root@localhost split]# dd if=/dev/zero bs=100k count=1 of=date.file
1+0 records in
1+0 records out
102400 bytes (102 kB) copied, 0.00043 seconds, 238 MB/s
使用split命令将上面创建的date.file文件分割成大小为10KB的小文件:
[root@localhost split]# split -b 10k date.file
[root@localhost split]# ls
date.file xaa xab xac xad xae xaf xag xah xai xaj
文件被分割成多个带有字母的后缀文件,如果想用数字后缀可使用-d参数,同时可以使用-a length来指定后缀的长度:
[root@localhost split]# split -b 10k date.file -d -a 3
[root@localhost split]# ls
date.file x000 x001 x002 x003 x004 x005 x006 x007 x008 x009
为分割后的文件指定文件名的前缀:
[root@localhost split]# split -b 10k date.file -d -a 3 split_file
[root@localhost split]# ls
date.file split_file000 split_file001 split_file002 split_file003 split_file004 split_file005 split_file006 split_file007 split_file008 split_file009
使用-l选项根据文件的行数来分割文件,例如把文件分割成每个包含10行的小文件:
split -l 10 date.file


