针对以上问题,MapReduce的设计者提出了下一代Hadoop MapReduce框架(官方称为MRv2/YARN)。
鉴于MapReduce V2的设计需求和MapReduce V1中凸显的问题,特别是JobTracker单点瓶颈问题(此问题影响着Hadoop集群的可靠性、可用性和扩展性),MapReduce V2的主要设计思路是将JobTracker承担的两大块任务—集群资源管理和作业管理进行分离(其中分离出来的集群资源管理由全局的资源管理器(ResourceManager)管理,分离出来的作业管理由针对每个作业的应用主题(ApplicationMaster)管理),然后TaskerTracker演化成节点管理器(NodeManger)。这样全局的资源管理器和局部的节点管理器就组成了数据计算框架,其中资源管理器将成为整个集群中资源最终的分配者。针对作业的应用主体就成为具体的框架库,负责两个任务:与资源管理器通信获取资源,与节点管理器配合完成节点的Task任务。
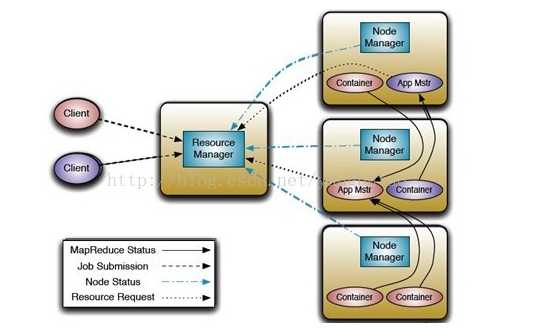
图 1 MapReduce V2结构图
(1)资源管理器
根据功能不同将资源管理器分成两个组件:调度器(scheduler)和应用管理器(ApplicationManager)。调度器根据集群中容量、队列和资源等限制,将资源分配给各个正在运行的应用。虽然被称为调度器,但是它仅负责资源的分配,而不负责监控各个应用执行情况和任务失败、应用失败或硬件失败时的重启任务。调度器根据各个应用的资源需求和集群各个节点的资源容器(Resource Containner,是集群节点将自身内存、CPU、磁盘等资源封装在一起的抽象概念)进行调度。应用管理器负责接收作业,协商获取第一个资源容器用于执行应用的任务主体并为重启失败的应用主体分配容器。
(2)节点管理器
节点管理器是每个节点的框架代理。它负责启动应用的容器,监控容器的资源使用(包括CPU、内存、硬盘和网络带宽等),并把这些信息汇报给调度器。应用对应的应用主体通过协商从调度器处获取资源容器,并跟踪这些容器的状态和应用执行情况。
集群每个节点上都有一个节点管理器,它主要负责:
a.为应用启用调度器已分配给应用的容器。
b.保证已启动的容器不会使用超过分配的资源量。
c.为task构建容器环境,包括二进制可执行文件,jar等;
d.为所有的节点提供一个管理本地存储资源的简单服务。
应用程序可以继续使用本地存储资源,即使它没有从资源管理器处申请。比如:MapReduce可以利用这个服务存储Map Task的中间输出结果并将其shuffle给Reduce Task。
(3)应用主体
应用主体和应用是一一对应的。它主要有以下职责:
a.与调度器协商资源
b.与节点管理器合作,在合适的容器中运行对应的组件Task,并监控这些Task执行;
c.如果container出现故障,应用主体会重复向调度器申请其他资源;
d.计算应用程序所需的资源量,并转换成调度器可识别的协议信息包;
e.在应用主体出现故障后,应用管理器会负责重启它,但由应用主体自己从之前保存的应用程序执行状态中恢复应用程序。
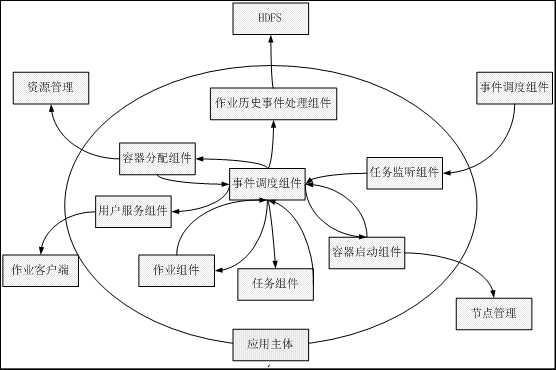
图2 应用主体组件事件流
1)事件调度组件,是应用主体中各个组件的管理者,负责为其他组件生成事件。
2)容器分配组件,负责将Task的资源请求翻译成发送给调度器的应用主体的资源请求,并与资源管理器协商获取资源。
3)用户服务组件,将作业的状态、计数器、执行进度等信息反馈给Hadoop Mapreduce的用户。
4)任务监听组件,负责接收Map或Reduce Task发送的心跳信息。
5)任务组件,负责接收Map或Reduce Task形成的心跳信息和状态更新信息。
6)容器启动组件,通过使节点管理器运行来负责容器的启动。
7)作业历史事件处理组件,将作业运行的历史事件写入HDFS。
8)作业组件,维护作业和组件的状态。
(4)资源容器
在MapReduce V2中,系统资源的组织形式是将节点上的可用资源分割,每一份通过封装组织成系统的一个资源单元,即container(比如固定大小的内存分片,CUP核心数,网络带宽量和硬盘空间块等。在现在提出的MapReduce V2中,所谓资源是指内存资源,每个节点由多个512MB或1G大小的内存容器组成)。而不是像MapReduce V1中那样,将资源组织成Map池和Reduce池。应用主体可以申请任意多个内存整数倍大小的容器。由于将每个节点的内存资源分割成了大小固定、地位相同的容器,这些内存容器就可以再任务执行中进行互换,从而提交利用率,避免了在MapReduce V1中作业在Reduce池上的瓶颈问题和缺乏资源互换的问题。资源容器的主要职责就是运行、保存或传输应用主体提交的作业或需要存储和传输的数据。
上面介绍了MapReduce V2的主体设计思想和架构及其各部分的主要职责,下面将详细一些设计细节。
1.资源协商
应用主体通过适当的资源需求描述来申请资源容器,可以报考一些指定的机器节点。应用主体还可以请求同一台机器上的多个资源容器。所有的资源请求受应用程序容量和队列容量等的限制。所以为了搞笑地分配集群的资源容器,应用主体需要计算应用的资源需求,并且把这些需求封装到调度器能够识别的协议信息包中,比如<priority,(host,rack,*),memory,#containers>。以MapReduce为例,应用主体分析input-splits并将其转化成以host为key的转置表发送给资源管理器,发送的信息中还包括在其执行期间随着执行的进度应用对资源容器需要的变化。调度器解析出应用主体的请求信息之后,会尽量分配请求的资源给应用主体。如果指定机器上的资源不可用,还可以将同一机器或者不同机器上的资源分配给应用主体。在有些情况下,由于整个集群非常忙碌,应用主体获取的资源可能不是最合适的,此时它可以拒绝这些资源并请求重新分配。
从上面介绍的资源协商的过程可以看出,MapReduce V2中的资源并不再是来自Map池和reduce池,而是来自统一的资源容器,这样应用主体可以申请所需数量的资源,而不会因为资源并非所需类型而挂起。需要注意的是,调度器不允许应用主体无限制地申请资源,它会根据应用限制,用户限制,队列限制和资源限制等来控制应用主体申请到的资源规模,从而保证集群资源不被浪费。
2.调度
调度器收集所有正在运行应用程序的资源请求并构建一个全局的资源分配计划。调度器会根据应用程序相关的约束(如合适的机器)和全局约束(如队列资源总量,队列限制,用户限制等)分配资源。调度器使用与容器调度类似的概念,采用容量保证作为基本的策略在多个竞争关系的应用程序间分配资源。调度器的调度步骤如下:
1)选择系统中“最低服务”的队列。这个队列可以使等待时间最长的队列,或者等待时间和已分配资源之比最大的队列等。
2)从队列中选择拥有最高优先级的作业。
3)满足被选出的作业的资源请求。
MapReduce V2中只有一个接口用于应用主体向调度器请求资源。接口如下:
Response allocate(list<ResourceRequest> ask, List<Container> release)
应用主体使用这个接口中的ResourceRequest列表请求特定的资源,同时使用接口中的Container列表告诉调度器自己释放的资源容器。
调度器接收到应用主体的请求之后会根据自己的全局计划及各种限制返回对请求的回复。回复中主要包括三类信息:最新分配的资源容器列表、在应用主体和资源管理器上次交互之后完成任务的应用指定资源容器的状态、当前集群中应用程序可用的资源数量。应用主体可以收集完成容器的信息并对失败任务作出反应。可用资源量可以为应用主体接下来的自愿申请提供参考,比如应用主体可以使用这些信息来合理分配Map和Reduce各自请求的资源数量,进而防止死锁(最明显的情况是Reduce请求占用所有的剩余可用资源)。
3.资源监控
调度器定期从节点管理器处收集已分配资源的使用信息。同时,调度器还会将已完成任务容器的状态设置为可用,以便有需求的应用申请使用。
4.应用提交
以下是应用提交的步骤。
1)用户提交作业到应用管理器。具体的步骤是在用户提交作业以后,MapReduce框架为用户分配一个新的应用ID,并将应用的定义打包上传到HDFS上用户的应用缓存目录中。最后提交此应用给应用管理器。
2)应用管理器接受应用提交。
3)应用管理器同调度器协商获取运行运行应用主体所需的第一个资源容器,并执行应用主体。
4)应用管理器将启动的应用主体细节返还给用户,以便其监督应用进度。
5.应用管理器组件
应用管理器负责启动系统中所有应用主体并管理其生命周期。在启动应用主体之后,应用管理器通过应用主体定期发送的“心跳”来监督应用主体,保证其可用性,如果主体失败,就需要将其重启。
为了完成上述任务,应用管理器包含以下组件:
1)调度协商组件,负责与调度器协商应用主体所需要的资源容器。
2)应用主体容器管理组件,负责通过与节点管理器通信来启动或停止应用主体容器。
3)应用主体监控组件,负责监控应用主体的状态,保持其可用,并且在必要的情况下重启应用主体。
6.MapReduce V2作业执行流程
由于主要组件发生了更改,MapReduce V2中的作业执行流程也有所变化。作业的执行流程图如下所示(仅说明主要的流程,一些反馈流程和心跳通信并未标注)。
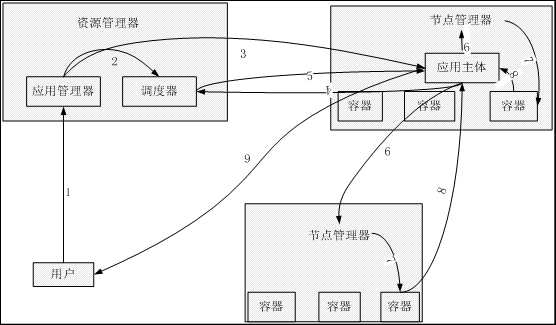
图 3 MapReduce V2作业执行流程
步骤1:MapReduce框架接收用户提交的作业,并为其分配一个新的应用ID,并为其分配一个新的应用ID,并将应用的定义打包上传到HDFS上用户的应用缓存目录中,然后提交此应用给应用管理器。
步骤2:应用管理器同调度器协商获取运行应用主体所需的第一个资源容器。
步骤3:应用管理器在获取的资源容器上执行应用主体。
步骤4:应用主体计算应用所需的资源,并发送资源请求到调度器。
步骤5:调度器根据自身统计的可用资源状态和应用主体的资源请求,分配合适的资源容器给应用主体。
步骤6: 应用主体与所分配容器的节点管理器通信,提交作业情况和资源使用说明。
步骤7:节点管理器启用容器并运行任务。
步骤8:应用主体监控容器上任务的执行情况。
步骤9:应用主体反馈作业的执行状态信息和完成状态。
7. MapReduce V2系统可用性保证
系统可用性主要指 MapReduce V2中各个组件的可用性,即保证能使其在失败之后迅速恢复并提供服务,比如保证资源管理器、应用主体等的可用性。首先介绍MapReduce V2如何保证MapReduce 应用和应用主体的可用性。在之前已有介绍,资源管理器中的应用管理器负责监控MapReduce 应用主体的执行情况。在应用主体发生失败之后,应用管理器仅重启应用主体,再由应用主体恢复某个特定的MapReduce作业。应用主体在恢复MapReduce作业时,有三种方式可供选择:完全重启MapReduce作业;重启未完成的Map和Reduce任务;向应用主体标明失败时正在运行的Map和Reduce任务,然后恢复作业执行。第一种方式的代价比较大,会重复工作;第二种方法效果较好,但仍有可能重复Reduce任务的部分工作;第三种方式最为理想,从失败点直接重新开始,没有任何重复工作,但这种方式对系统的要求过高。在MapReduce V2中选择第二种恢复方式,具体实现方式是:应用管理器在监督MapReduce任务执行的同时记录日志,标明已完成的Map和Reduce任务;在恢复作业时,分析日志后重启未完成的任务即可。
接下来介绍MapReduce如何保证资源管理器的可用性。资源管理器在运行服务过程中,使用ZooKeeper保存资源管理的状态,包括应用管理器进程情况、队列定义、资源分配情况、节点管理器情况等信息。在资源管理器失败之后,由资源管理器根据自己的状态进行自我恢复。
8.MapReduce V2的优势
1)分散了JobTracker的任务。资源管理任务由资源管理器负责,作业启动、运行和检测任务由分布正在集群节点上的应用主体负责。这样大大减缓了MapReduce V1中JobTracker单点瓶颈和单点风险的问题,大大提高了集群的扩展性和可用性。
2)在MapReduce V2中应用主体(ApplicationMaster)是一个用户可自定制的部分,因此用户可以针对编程模型编写自己的应用主体程序。这样大大扩展了MapReduce V2的适用范围。
3)在资源管理器上适用ZooKeeper实现故障转移。当资源管理器故障时,备用资源管理器将根据保存在ZooKeeper中的集群状态快速启动。MapReduce V2支持应用程序指定检查点。这就能保证应用主体在失败后能迅速的根据HDFS上保存的状态重启。这两个措施大大提高了MapReduce V2的可用性。
4)集群资源统一组织成资源容器,而不像MapReduce V1中的Map和Reduce池有所差别。这样只要有任务请求资源,调度器就会将集群中的可用资源分配给请求任务,而无关资源类型。这样大大提高了集群资源的利用率。
参考资料:Hadoop实战 第2版 陆嘉恒著
Yarn(MapReduce V2),布布扣,bubuko.com
原文:http://www.cnblogs.com/shihuai355/p/3825167.html