ng机器学习视频笔记(三)
——线性回归的多变量、特征缩放、标准方程法
(转载请附上本文链接——linhxx)
一、多变量
当有n个特征值,m个变量时,h(x)= θ0+θ1x1+θ2x2…+θnxn,其中可以认为x0=1。因此,h(x)= θTx,其中θ是一维向量,θ=[θ0, θ1…θn] T,x也是一维向量,x=[x0,x1..xn] T,其中x0=1。
二、特征缩放(Feature Scaling)
特征缩放的目的,是为了让每个特征值在数量上更加接近,使得每个特征值的变化的影响相对比较“公平”。
其将每个特征值,除以变量中该特征值的范围(特征值最大值减最小值),将结果控制在-1~1之间。
对于x0,不需要改变,其仍是1,也在期望的范围内(-1~1)。
公式:特征值=(原值-特征平均值)/取值区间,取值区间=最大值-最小值。
三、学习速率α
α表示迭代至稳定值的速率。当θ用公式进行迭代,两次迭代之间的Δθ的值小于某个值(一般可以用10-3),则可以认为代价函数已经最小。
对于α,可以使用下列数据进行测试:
0.001、0.01、0.1、1、10…,或者可以用0.001、0.003、0.01、0.03、0.1、0.3、1…,即可以用3倍或10倍的速度,将α的值慢慢调整到一个区间,再进行微调。
四、多项式回归(Polynomial regression)
当图像用直线表示不是很准确的时候,可以考虑使用其他函数,如二次、三次、根号等函数进行表示。
五、标准方程法(normal equation)
1、公式推导
标准方程法是与梯度下降法功能相似的算法,旨在获取使代价函数值最小的参数θ。代价函数公式如下:
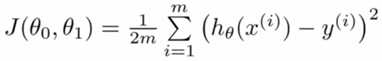
根据上述代价函数,令J对每个θ的倒数都为0,可以解得θ=(XTX)-1XTY。其中,Y=[y1,y2…yn]表示每个样本的结果,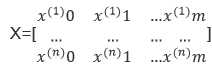 表示样本的集合。
表示样本的集合。
由于这个方法是直接通过代数的方式,解出每个θ,因此,其不需要进行特征缩放,也不需要学习速率α。
2、特殊情况
由于用标准方程法时,涉及到要计算矩阵XTX的逆矩阵。但是XTX的结果有可能不可逆。
当使用python的numpy计算时,其会返回广义的逆结果。
主要原因:
出现这种情况的主要原因,主要有特征值数量多于训练集个数、特征值之间线性相关(如表示面积采用平方米和平方公里同时出现在特征值中)。
因此,首先需要考虑特征值是否冗余,并且清除不常用、区分度不大的特征值。
3、比较标准方程法和梯度下降算法
这两个方法都是旨在获取使代价函数值最小的参数θ,两个方法各有优缺点:
1)梯度下降算法
优点:当训练集很大的时候(百万级),速度很快。
缺点:需要调试出合适的学习速率α、需要多次迭代、特征值数量级不一致时需要特征缩放。
2)标准方程法
优点:不需要α、不需要迭代、不需要特征缩放,直接解出结果。
缺点:运算量大,当训练集很大时速度非常慢。
4、综合
因此,当训练集百万级时,考虑使用梯度下降算法;训练集在万级别时,考虑使用标准方程法。在万到百万级区间时,看情况使用,主要还是使用梯度下降算法。
——written by linhxx
更多最新文章,欢迎关注微信公众号“决胜机器学习”,或扫描右边二维码。