海量数据处理使用的大多是鼎鼎大名的hadoop或者hive,作为一个批处理系统,hadoop以其吞吐量大、自动容错等优点,在海量数据处理上得到了广泛的使用。但是,hadoop不擅长实时计算,因为它天然就是为批处理而生的,这也是业界一致的共识。否则最近这两年也不会有s4,storm,puma这些实时计算系统如雨后春笋般冒出来。先抛开s4,storm,puma这些系统不谈,我们首先来看一下,如果让我们自己设计一个实时计算系统,我们要解决哪些问题:
1、低延迟。都说了是实时计算系统了,延迟是一定要低的。
2、高性能。性能不高就是浪费机器,浪费机器是要受批评的哦。
3、分布式。系统都是为应用场景而生的,如果你的应用场景、你的数据和计算单机就能搞定,那么不用考虑这些复杂的问题了,这里讲的是单机搞不定的情况。
4、可扩展。伴随着业务的发展,我们的数据量、计算量可能会越来越大,所以希望这个系统是可扩展的。
5、容错性。这是分布式系统中通用问题。一个节点挂了不能影响我的应用。
下面我们来看看什么是Storm
Storm是什么
如果只用一句话来描述storm的话,可能会是这样:分布式实时计算系统。按照storm作者的说法,storm对于实时计算的意义类似于hadoop对于批处理的意义。我们都知道,根据google mapreduce来实现的hadoop为我们提供了map, reduce原语,使我们的批处理程序变得非常地简单和优美。同样,storm也为实时计算提供了一些简单优美的原语,后面进行详细介绍。
我们来看一下storm的适用场景。
1、流数据处理。Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去。
2、分布式RPC。由于storm的处理组件是分布式的,而且处理延迟极低,所以可以作为一个通用的分布式rpc框架来使用。当然,其实我们的搜索引擎本身也是一个分布式rpc系统。
Storm的基本概念
首先,我们通过一个storm和hadoop的对比来了解storm中的基本概念。
|
Hadoop |
Storm |
|
|
系统角色 |
JobTracker |
Nimbus |
|
TaskTracker |
Supervisor |
|
|
Child |
Worker |
|
|
应用名称 |
Job |
Topology |
|
组件接口 |
Mapper/Reducer |
Spout/Bolt |
其中:
1、Nimbus:负责资源分配和任务调度。
2、Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。
3、Worker:运行具体处理组件逻辑的进程。
4、Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,同一个spout/bolt的task可能会共享一个物理线程,该线程称为executor。
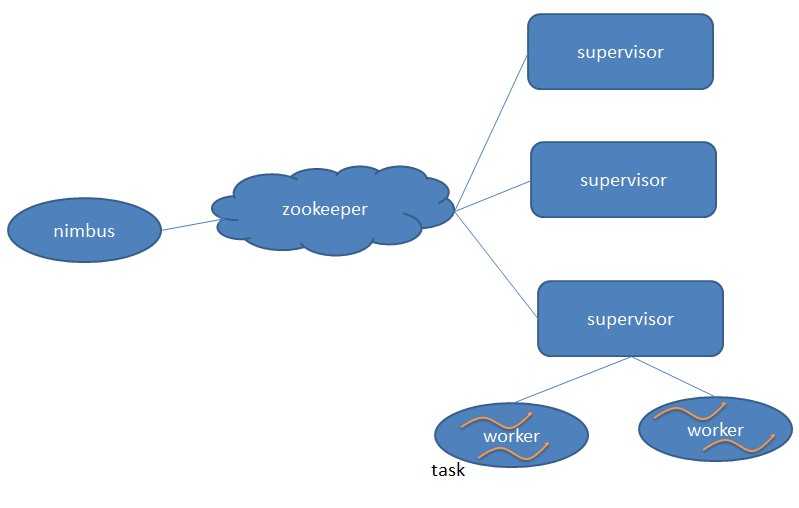
Storm组件
Storm集群主要由一个主节点和一群工作节点(worker node)组成,通过 Zookeeper进行协调。
主节点:
主节点通常运行一个后台程序 —— Nimbus,用于响应分布在集群中的节点,分配任务和监测故障。这个很类似于Hadoop中的Job Tracker。
工作节点:
工作节点同样会运行一个后台程序 —— Supervisor,用于收听工作指派并基于要求运行工作进程。每个工作节点都是topology中一个子集的实现。而Nimbus和Supervisor之间的协调则通过Zookeeper系统或者集群。
Zookeeper
Zookeeper是完成Supervisor和Nimbus之间协调的服务。而应用程序实现实时的逻辑则被封装进Storm中的“topology”。topology则是一组由Spouts(数据源)和Bolts(数据操作)通过Stream Groupings进行连接的图。下面对出现的术语进行更深刻的解析。
Spout:
简而言之,Spout从来源处读取数据并放入topology。Spout分成可靠和不可靠两种;当Storm接收失败时,可靠的Spout会对tuple(元组,数据项组成的列表)进行重发;而不可靠的Spout不会考虑接收成功与否只发射一次。而Spout中最主要的方法就是nextTuple(),该方法会发射一个新的tuple到topology,如果没有新tuple发射则会简单的返回。
Bolt:
Topology中所有的处理都由Bolt完成。Bolt可以完成任何事,比如:连接的过滤、聚合、访问文件/数据库、等等。Bolt从Spout中接收数据并进行处理,如果遇到复杂流的处理也可能将tuple发送给另一个Bolt进行处理。而Bolt中最重要的方法是execute(),以新的tuple作为参数接收。不管是Spout还是Bolt,如果将tuple发射成多个流,这些流都可以通过declareStream()来声明。
Stream Groupings:
Stream Grouping定义了一个流在Bolt任务间该如何被切分。这里有Storm提供的6个Stream Grouping类型:
1. 随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple。
2. 字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务。
3. 全部分组(All grouping):tuple被复制到bolt的所有任务。这种类型需要谨慎使用。
4. 全局分组(Global grouping):全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task。
5. 无分组(None grouping):你不需要关心流是如何分组。目前,无分组等效于随机分组。但最终,Storm将把无分组的Bolts放到Bolts或Spouts订阅它们的同一线程去执行(如果可能)。
6. 直接分组(Direct grouping):这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者任务接收。
当然还可以实现CustomStreamGroupimg接口来定制自己需要的分组。
Storm记录级容错的基本原理
首先来看一下什么叫做记录级容错?storm允许用户在spout中发射一个新的源tuple时为其指定一个message id, 这个message id可以是任意的object对象。多个源tuple可以共用一个message id,表示这多个源 tuple对用户来说是同一个消息单元。storm中记录级容错的意思是说,storm会告知用户每一个消息单元是否在指定时间内被完全处理了。那什么叫做完全处理呢,就是该message id绑定的源tuple及由该源tuple后续生成的tuple经过了topology中每一个应该到达的bolt的处理。举个例子。在图4-1中,在spout由message 1绑定的tuple1和tuple2经过了bolt1和bolt2的处理生成两个新的tuple,并最终都流向了bolt3。当这个过程完成处理完时,称message 1被完全处理了。
图4-1
在storm的topology中有一个系统级组件,叫做acker。这个acker的任务就是追踪从spout中流出来的每一个message id绑定的若干tuple的处理路径,如果在用户设置的最大超时时间内这些tuple没有被完全处理,那么acker就会告知spout该消息处理失败了,相反则会告知spout该消息处理成功了。在刚才的描述中,我们提到了”记录tuple的处理路径”,如果曾经尝试过这么做的同学可以仔细地思考一下这件事的复杂程度。但是storm中却是使用了一种非常巧妙的方法做到了。在说明这个方法之前,我们来复习一个数学定理。
A xor A = 0.
A xor B…xor B xor A = 0,其中每一个操作数出现且仅出现两次。
storm中使用的巧妙方法就是基于这个定理。具体过程是这样的:在spout中系统会为用户指定的message id生成一个对应的64位整数,作为一个root id。root id会传递给acker及后续的bolt作为该消息单元的唯一标识。同时无论是spout还是bolt每次新生成一个tuple的时候,都会赋予该tuple一个64位的整数的id。Spout发射完某个message id对应的源tuple之后,会告知acker自己发射的root id及生成的那些源tuple的id。而bolt呢,每次接受到一个输入tuple处理完之后,也会告知acker自己处理的输入tuple的id及新生成的那些tuple的id。Acker只需要对这些id做一个简单的异或运算,就能判断出该root id对应的消息单元是否处理完成了。下面通过一个图示来说明这个过程。
图4-1 spout中绑定message 1生成了两个源tuple,id分别是0010和1011.
图4-2 bolt1处理tuple 0010时生成了一个新的tuple,id为0110.
图4-3 bolt2处理tuple 1011时生成了一个新的tuple,id为0111.
图4-4 bolt3中接收到tuple 0110和tuple 0111,没有生成新的tuple.
可能有些细心的同学会发现,容错过程存在一个可能出错的地方,那就是,如果生成的tuple id并不是完全各异的,acker可能会在消息单元完全处理完成之前就错误的计算为0。这个错误在理论上的确是存在的,但是在实际中其概率是极低极低的,完全可以忽略。
Storm的事务拓扑
事务拓扑(transactional topology)是storm0.7引入的特性,在最近发布的0.8版本中已经被封装为Trident,提供了更加便利和直观的接口。因为篇幅所限,在此对事务拓扑做一个简单的介绍。
事务拓扑的目的是为了满足对消息处理有着极其严格要求的场景,例如实时计算某个用户的成交笔数,要求结果完全精确,不能多也不能少。Storm的事务拓扑是完全基于它底层的spout/bolt/acker原语实现的,通过一层巧妙的封装得出一个优雅的实现。个人觉得这也是storm最大的魅力之一。
事务拓扑简单来说就是将消息分为一个个的批(batch),同一批内的消息以及批与批之间的消息可以并行处理,另一方面,用户可以设置某些bolt为committer,storm可以保证committer的finishBatch()操作是按严格不降序的顺序执行的。用户可以利用这个特性通过简单的编程技巧实现消息处理的精确。
Storm在淘宝
由于storm的内核是clojure编写的(不过大部分的拓展工作都是java编写的),为我们理解它的实现带来了一定的困难,好在大部分情况下storm都比较稳定,当然我们也在尽力熟悉clojure的世界。我们在使用storm时通常都是选择java语言开发应用程序。
在淘宝,storm被广泛用来进行实时日志处理,出现在实时统计、实时风控、实时推荐等场景中。一般来说,我们从类kafka的metaQ或者基于hbase的timetunnel中读取实时日志消息,经过一系列处理,最终将处理结果写入到一个分布式存储中,提供给应用程序访问。我们每天的实时消息量从几百万到几十亿不等,数据总量达到TB级。对于我们来说,storm往往会配合分布式存储服务一起使用。在我们正在进行的个性化搜索实时分析项目中,就使用了timetunnel + hbase + storm + ups的架构,每天处理几十亿的用户日志信息,从用户行为发生到完成分析延迟在秒级。
原文:http://www.cnblogs.com/batys/p/3834546.html