KNN
- 思想简单
- 数学所需知识少(近零)
- 效果好
- 可解释机器学习算法使用过程中的很多细节问题
- 更完整的刻画机器学习应用的流程
K近邻本质:如果两个样本足够相似,那么它们就有可能属于同一类别。
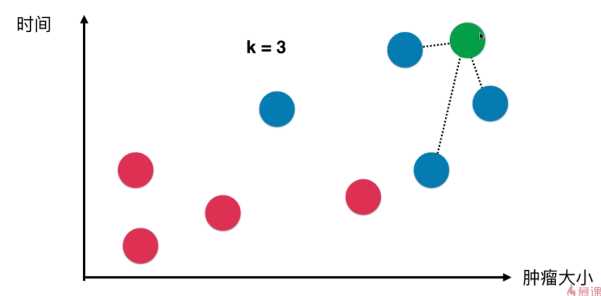
e.g. 绿色的点是新加入的点,取其最近的k(3)个点作为小团体来投票,票数高的获胜(蓝比红-3:0),所以绿点应该也是蓝点
计算距离:
最常见 -> 欧拉距离,求a, b两点的距离(二维,三维,多维):
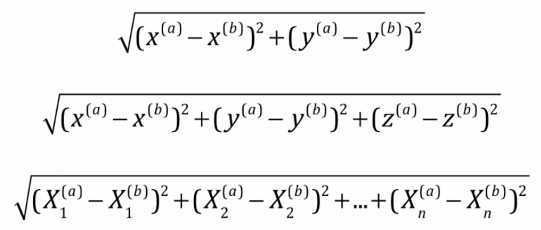 ->
-> 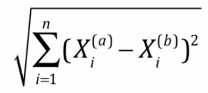
理解小笔记:((a样本第一个维度特征-b样本第一个维度特征)2 + (a样本第二个维度特征-b样本第二个维度特征)2 + ... ) 再开根
近乎可以说,KNN算法是机器学习中唯一一个不需要训练过程的算法。输入用例可直接送给训练数据集。
- KNN可以被认为是没有模型的算法
- 为和其他算法统一,可认为其训练数据集本身就是模型