elasticSearch node 的配置如下:
# Every node can be configured to allow or deny being eligible as the master,
# and to allow or deny to store the data.
#
# Allow this node to be eligible as a master node (enabled by default):
#
#node.master: true
#
# Allow this node to store data (enabled by default):
#
#node.data: true
# You can exploit these settings to design advanced cluster topologies.
#
# 1. You want this node to never become a master node, only to hold data.
# This will be the "workhorse" of your cluster.
#
#node.master: false
#node.data: true
#
# 2. You want this node to only serve as a master: to not store any data and
# to have free resources. This will be the "coordinator" of your cluster.
#
#node.master: true
#node.data: false
#
# 3. You want this node to be neither master nor data node, but
# to act as a "search load balancer" (fetching data from nodes,
# aggregating results, etc.)
#
#node.master: false
#node.data: false
| node.master | node.data | remark |
| true | true | default |
| true | false | coordinator |
| false | true | workhorse |
| false | false | search load balancer |
对于Node的配置,还需要注意几点:
1.用来做请求分发和结果合并的节点如何配置?(search、fetching...)
2.不同类型的节点通信方式怎么配置比较合理?(Tcp、Http)
elasticsearch allows to configure a node to either be allowed to store data locally or not. Storing data locally basically means that shards of different indices are allowed to be allocated on that node. By default, each node is considered to be a data node, and it can be turned off by setting node.data to false.
This is a powerful setting allowing to simply create smart load balancers that take part in some of different API processing. Lets take an example:
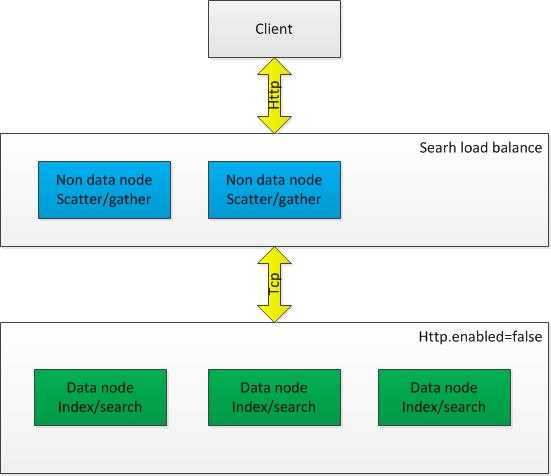
We can start a whole cluster of data nodes which do not even start an HTTP transport by setting http.enabled to false. Such nodes will communicate with one another using the transportmodule. In front of the cluster we can start one or more "non data" nodes which will start with HTTP enabled. All HTTP communication will be performed through these "non data" nodes.
The benefit of using that is first the ability to create smart load balancers. These "non data" nodes are still part of the cluster, and they redirect operations exactly to the node that holds the relevant data. The other benefit is the fact that for scatter / gather based operations (such as search), these nodes will take part of the processing since they will start the scatter process, and perform the actual gather processing.
This relieves the data nodes to do the heavy duty of indexing and searching, without needing to process HTTP requests (parsing), overload the network, or perform the gather processing.
---
我们可以将整个机器分成两部分,data nodes和non data nodes。data nodes的通信协议采用tcp(http.enabled设置成false),主要负责搜索引擎的“运算”(indexing、searching)。non data nodes采用http进行通信,主要负责请求的分发(scatter)、结果的合并(gather)等。
如图:
ElasticSearch - Node,布布扣,bubuko.com
原文:http://www.cnblogs.com/huangfox/p/3835697.html