最近开始看一些整本整本的英文典籍,虽然能看个大概,但是作为四级都没过的我来说还是有些吃力,总还有一部分很关键的单词影响我对句子的理解,因为看的是纸质的,所以查询也很不方便,于是想来个突击,我想把程序单词收拢在一起学习一下,希望这样的更有针对性一些,因为你想,arbitrary (任意的,武断的)这样的单词不太可能会出现在技术文档上,学了这样的单词对理解英文技术文档没有太大帮助。所以今天花了几个小时研究了一下,发现是很可行的,实现也不算难。步骤主要是以下几点,第一:先搞定翻译接口。翻译的来源分为接口型和爬虫型,我看了看百度的那个翻译页面,不是很好爬,但是百度官方提供了翻译的接口,只要申请成为百度的开发者即可,然后利用百度给的app key即可实现翻译,而且接口也很丰富,但是我还是觉得略微麻烦。另外一个就是谷歌了,我仔细看了看谷歌翻译页面的接口,发现竟然出奇的简单,只有一个set-cookie的接口,然后就是翻译的接口,你肯定猜到了,我用的就是爬取谷歌的翻译页面。第二:爬取你想分析的英文文档的单词。翻译嘛,总的有大批的单词啊,那么我这边也是通过爬虫获取的,给定一个页面,比如https://docs.python.org/3/library/abc.html#module-abc这样的技术文档,我们需要把所有看上去像单词的单词都正则匹配出来,然后逐个调用翻译接口翻译出来。好了,思路的介绍就是这样了,如果你已经产生了兴趣,你可以不往下看,自己先摆弄一番,如果你觉得想先看看我的实现,那我也十分欢迎。OK,我们先上一张结果图,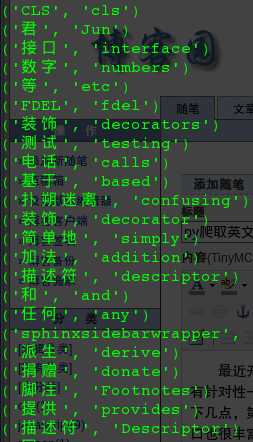 。这个就是所谓的爬取和翻译的结果了。那么我们紧接着贴一下代码吧:
。这个就是所谓的爬取和翻译的结果了。那么我们紧接着贴一下代码吧:
# -*- coding: utf-8 -*- import re, urllib.parse, urllib.request, http.cookiejar
# 以下四行代码是为了缓存cookie用的,谷歌翻译接口给不给你翻译,他只看请求源有没有他认可的cookie,一般的urllib.request请求是不会缓存cookie的 cj = http.cookiejar.LWPCookieJar() cookie_support = urllib.request.HTTPCookieProcessor(cj) opener = urllib.request.build_opener(cookie_support, urllib.request.HTTPHandler) urllib.request.install_opener(opener) # 通过get请求来获取数据,这里需要注意的是,headers是应该带上的,虽然是get请求,但是某些网站的后台是会检测请求有没有带headers的,不带headers被认为是爬虫,他不理睬的,所以我们也要模拟一下 def getData(url): headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0‘} request = urllib.request.Request(url = url, headers = headers) response = urllib.request.urlopen(request) text = response.read().decode(‘utf-8‘) return text # 谷歌翻译页面只需要登陆一次 google_logined = False # 翻译函数 def translate(word): if not google_logined:
# 刚才说的那个set-cookie的接口就是下面这个简短的http://tr...../,他会设置一段cookie getData(‘http://translate.google.cn/‘) global google_logined google_logined = True try:
# 常常的url就是翻译接口,最后带上需要翻译的单词 data = getData("http://translate.google.cn/translate_a/single?client=t&sl=en&tl=zh-CN&hl=zh-CN&dt=bd&dt=ex&dt=ld&dt=md&dt=qc&dt=rw&dt=rm&dt=ss&dt=t&dt=at&dt=sw&ie=UTF-8&oe=UTF-8&oc=2&otf=1&srcrom=1&ssel=0&tsel=0&q=" + word)
# 其实翻译出来的东西蛮多的,可是我们只需要最前面的中文就好了,于是正则匹配一下拿出来即可 reg = re.compile(‘^\[\[\[\"(.+?)\",\"(.+?)\"\]‘) tran = reg.findall(data)[0]
# 一开始我没有用try except,发现有些单词的翻译json结构变了,估计是不好翻译以后,谷歌给的json很短,正则匹配出错了,所以try一下吧 except: return (‘error========================>>>‘+word) return tran # 这个正则用途你也许猜到了,就是正则匹配一个页面的所有的单词,但是性能并不是很好,他会把<span>apple</span>中的span和apple都匹配出来,不过稍加处理也就可以解决,咱先让性能一边玩去 parse_word_reg = re.compile(‘([a-zA-Z]{3,})‘) # 解析页面单词的函数,参数为url,用上面的正则去匹配,返回来的是一个结果列表,另外我用set这个集合生成函数做了一下过滤,用过python的童鞋懂的。。。 def parse_words(url): content = getData(url) words = parse_word_reg.findall(content) words = list(set(words)) return words # 好了,万函具备,只欠测试了,我们传一个技术文档的url进去实施吧,发现他就逐个逐个开始翻译了。 words = parse_words("https://docs.python.org/3/library/abc.html#module-abc") for word in words: print(translate(word))
原文:http://www.cnblogs.com/xuchaosheng/p/3835824.html