包括三个文件:studentInfo.xml(待解析的xml文件), Dom4jReadExmple.java(解析的主要类), TestDom4jReadExmple.java(测试解析的结果)
代码运行前需先导入dom4j架包。
studentInfo.xml文件(该文件放在本项目目录下)内容如下:
<?xml version="1.0" encoding="gb2312"?>
<students>
<student age="25"><!--如果没有age属性,默认的为20-->
<name>崔卫兵</name>
<college>PC学院</college>
<telephone>62354666</telephone>
<notes>男,1982年生,硕士,现就读于北京邮电大学</notes>
</student>
<student>
<name>cwb</name>
<college leader="学院领导">PC学院</college><!--如果没有leader属性,默认的为leader-->
<telephone>62358888</telephone>
<notes>男,1987年生,硕士,现就读于中国农业大学</notes>
</student>
<student age="45">
<name>xxxxx</name>
<college leader="">xxx学院</college>
<telephone>66666666</telephone>
<notes>注视中,注释中</notes>
</student>
<student age="">
<name>lxx</name>
<college>yyyy学院</college>
<telephone>88888888</telephone>
<notes>注视中111,注释中222</notes>
</student>
</students>
Dom4jReadExmple.java类代码如下:
import java.io.File;
import java.util.HashMap;
import java.util.Iterator;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
/**
* 利用dom4j进行XML编程
*
* @author henuyuxiang
* @since 2014.7.11
*/
public class Dom4jReadExmple {
/**
* 遍历整个XML文件,获取所有节点的值与其属性的值,并放入HashMap中
*
* @param filename
* String 待遍历的XML文件(相对路径或者绝对路径)
* @param hm
* HashMap
* 存放遍历结果,格式:<nodename,nodevalue>或者<nodename+attrname,attrvalue>
*/
public void iterateWholeXML(String filename, HashMap<String, String> hm) {
SAXReader saxReader = new SAXReader();
try {
Document document = saxReader.read(new File(filename));
Element root = document.getRootElement();
// 用于记录学生编号的变量
int num = -1;
// 遍历根结点(students)的所有孩子节点(肯定是student节点)
for (@SuppressWarnings("rawtypes")
Iterator iter = root.elementIterator(); iter.hasNext();) {
Element element = (Element) iter.next();
num++;
// 获取person节点的age属性的值
Attribute ageAttr = element.attribute("age");
if (ageAttr != null) {
String age = ageAttr.getValue();
if (age != null && !age.equals("")) {
hm.put(element.getName() + "-" + ageAttr.getName()
+ num, age);
} else {
hm.put(element.getName() + "-" + ageAttr.getName()
+ num, "20");
}
} else {
hm.put(element.getName() + "-age" + num, "20");
}
// 遍历student结点的所有孩子节点(即name,college,telphone,notes),并进行处理
for (@SuppressWarnings("rawtypes")
Iterator iterInner = element.elementIterator(); iterInner
.hasNext();) {
Element elementInner = (Element) iterInner.next();
if (elementInner.getName().equals("college")) {
hm.put(elementInner.getName() + num,
elementInner.getText());
// 获取college节点的leader属性的值
Attribute leaderAttr = elementInner.attribute("leader");
if (leaderAttr != null) {
String leader = leaderAttr.getValue();
if (leader != null && !leader.equals("")) {
hm.put(elementInner.getName() + "-"
+ leaderAttr.getName() + num, leader);
} else {
hm.put(elementInner.getName() + "-"
+ leaderAttr.getName() + num, "leader");
}
} else {
hm.put(elementInner.getName() + "-leader" + num,
"leader");
}
} else {
hm.put(elementInner.getName() + num,
elementInner.getText());
}
}
}
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
TestDom4jReadExmple.java类代码如下:
package demo1;
import java.util.HashMap;
/**
* 测试Dom4jReadExmple解析的情况
*
* @author henuyuxiang
* @since 2014.7.11
*/
public class TestDom4jReadExmple {
public static void main(String[] args) {
try {
// 获取解析完后的解析信息
HashMap<String, String> hashMap;
Dom4jReadExmple drb = new Dom4jReadExmple();
// 遍历整个XML文件
hashMap = new HashMap<String, String>();
drb.iterateWholeXML("studentInfo.xml", hashMap);
System.out.println("姓名\t年龄\t学院\t学院领导\t电话\t备注");
for (int i = 0; i < hashMap.size(); i += 6) {
int j = i / 6;
System.out.print(hashMap.get("name" + j) + "\t");
System.out.print(hashMap.get("student-age" + j) + "\t");
System.out.print(hashMap.get("college" + j) + "\t");
System.out.print(hashMap.get("college-leader" + j) + "\t");
System.out.print(hashMap.get("telephone" + j) + "\t");
System.out.println(hashMap.get("notes" + j) + "\t");
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
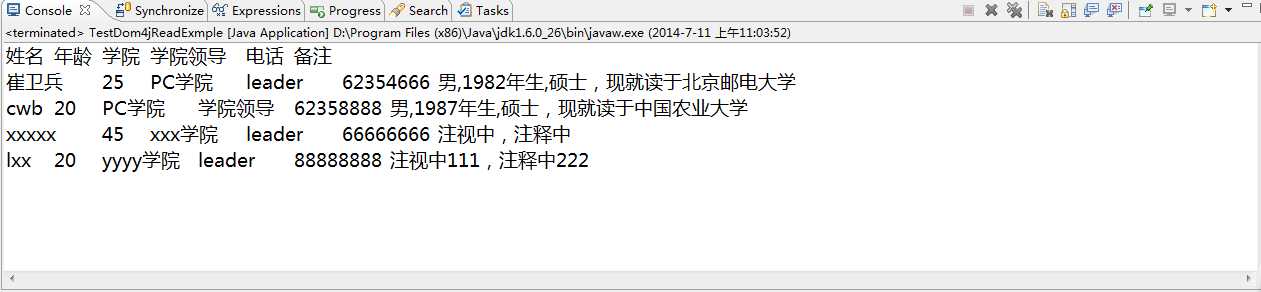
运行结果如下图所示:
原文:http://www.cnblogs.com/henuyuxiang/p/3837284.html