HDFS Namenode&Datanode
HDFS 机制粗略示意图
客户端写入文件流程:
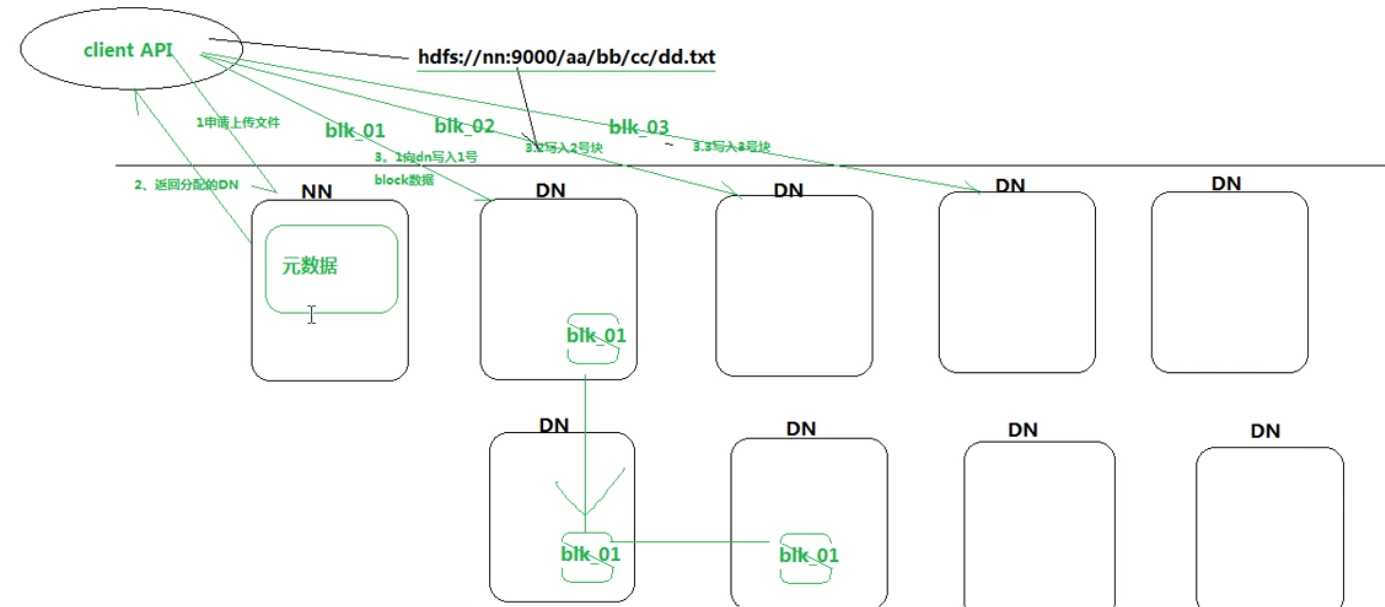
NN && DN
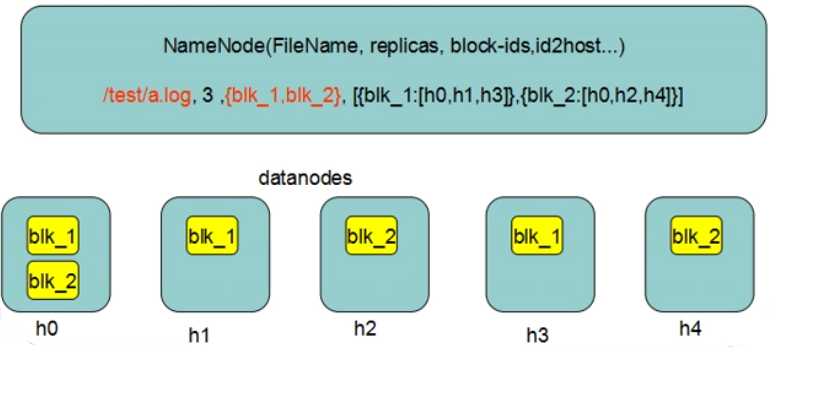
Namenode(NN)工作机制
NN是整个文件系统的管理节点。维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表(管理元数据)。接收用户的操作请求。
fsimage:元数据镜像文件。存储某一时段NN内存元数据信息
edits:操作日志文件
fstime:保存最近一次checkpoint的时间
(以上文件保存在linux文件系统中)
主流程
- 客户端上传文件时,NN首先往edits log文件中记录元数据操作日志
- 客户端开始上传文件,完成后返回成功信息给NN。NN就在内存中写入这次上传操作而新产生的元数据信息。既实现了客户端可以从内存中查询(读写速度比从磁盘快),又保证了可靠性(若断电内存中的信息丢失,则可以从edits log文件中找回)。
- 每当edits log写满时,由secondary namenode将这部分新的元数据合并到fsimage文件中(checkpoint操作)。
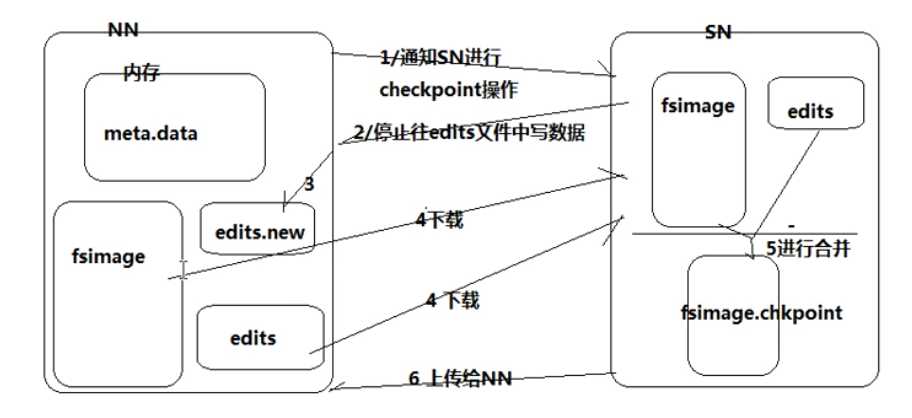
secondary namenode 的 checkpoint 操作
工作流程
- secondary通知namenode切换edits文件(改为写到edits.new)
- secondary从namenode获得fsimage和edits(通过http)
- secondary将fsimage载入内存,然后开始合并edits,产生新的fsimage
- secondary将新的fsimage发回给namenode
- namenode用新的fsimage替换旧的fsimage,并将edits.new重命名为edits
进行checkpoint的时间
- fs.checkpoint.period 指定两次checkpoint的间隔(默认3600秒)
- fs.chekpoint.size 规定edits文件的最大值,一旦超过则强制checkpoint,不管是否达到时间间隔(默认64M)
(以上可在hdfs-site.xml中设置)
Datanode(DN)工作原理
DN提供真实文件数据的存储服务。
文件块(block):最基本的存储单位。对于文件而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小顺序对文件进行划分并编号,划分好的每一块称一个block。
block的默认大小是128M,可以修改dfs.block.size参数进行更改
上传一个文件看看分块情况
上传 hadoop fs -put xxx(随便一个稍大一些的文件) /
打开datanode的数据文件夹 cd /app/hadoop-3.0.0/data/dfs/data/current/BP-1998331996-192.168.216.100-1521773499028/current/finalized/subdir0/subdir0
查看 du -sh *
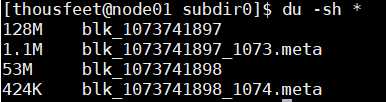
能看到被分作了两个block,其中一个正是128M。(.mate是校验和文件不是一个block)