个人作业:词频统计
Github项目地址:https://github.com/USTChuomiao/homework1/blob/master/PB15061351/hw1.cpp
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 3 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 3 |
| Development | 开发 | 1125 | 1235 |
| · Analysis | · 需求分析 (包括学习新技术) | 3 * 60 | 4* 60 |
| · Design Spec | · 生成设计文档 | 30 | 40 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 5 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 8 * 60 | 9 * 60 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 6* 60 | 5.5 * 60 |
| Reporting | 报告 | 60 | 60 |
| · Test Report | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 1190 | 1298 |
项目要求:
1、目标:对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php 等,文件夹内的 所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
2、要求:设计 10 个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一 个词的文件,只有一行的文件,典型文件等等)。
解决思路:
1、首先做了一个初步的规划: (1)文件夹的遍历;
(2)统计单个文件中的字符数、行数、单词数;
(3)对每个单词以及出现次数进行存储;
(4)对每个词组以及出现次数进行存储;
(5)找出词频前十的单词和词组并输出。
2、完成对一个路径内所有文件的遍历。起初在windows环境开发,学习了网上的一些操作之后,结合自己的想法,决定用栈来辅助所有文件的遍历。先打开一个文件夹,如果是文件夹将其路径存入栈中,如果是文件继续遍历,完成当前文件夹遍历之后,从栈中弹出一个路径继续重复上述操作,直到栈空即所有文件都被遍历了。后期将代码移植到 linux 环境下,采用递归的方法遍历所有文件。
3、统计一个文件中字符数、行数、单词数,字符数和行数没什么好说的,主要是单词的提取。根据给出的单词的定义,设计了一个提取单词的算法:把当前字符用ch来存储,它的前一个字符用chr来存储,首先若满足word[0]为空、chr为非数字和字母的分隔符、ch为字母这三个条件,则将ch存入word[0];继续读取字符,若word不为空且ch为字母,则存入word,若word长度大于4,ch为数字亦存入word;当ch读到一个分隔符时,即不满足上述条件时,检测当前word长度是否大于4,若大于则成功提取一个单词,反之清空word;重复上述操作即可将文件中单词提取出来。
4、存储并统计单词出现次数,起初考虑了用结构体数组、文件、树来存储,但是想了想感觉存储空间或者运行速度上会受到限制,最后采用Hash Table通过动态链表的形式存储单词及其出现次数。这个Hash Table最初想到以26个字母对应26个头指针的形式,后来升级到26*26*26*26个头指针,即依据单词的前四个字母进行检索。从刚刚成功提取单词那里调用一个对单词进行处理的函数,这个函数大概算法是这样的:首先找到这个单词对应的头指针,然后顺着头指针的链表依次对比两个单词的大小(通过ASCII码),直到找到一个相同单词的位置,就把他的词频数+1,或者找到介于两单词之间,就创建节点插入链表(这个过程中相同有是否替换单词形式的判断过程)。直到把所有单词都存入Hash Table即完成任务。(这样存储进去的单词若从Hash Table头开始遍历即是词典顺序)
5、词组的统计和单词类似,只需对提取单词的操作稍加改动,即可完成词组的提取。同样词组存入词组的Hash Table的操作也同单词类似。
6、输出词频前十的单词和词组,首先提取所有词频存入数组(单词和词组分开操作,并过滤掉相同词频数),找出词频数最大的十个,然后由刚找到的前十词频去遍历Hash Table输出十个单词或词组就停止。(注意:十个词频数不一定全用到,可能有两个或多个单词或词组词频数相同)
Linux下对代码质量进行分析:
gprof是gcc/g++编译器支持的一种性能诊断工具。只要在编译时加上-pg选项,编译器就会在编译程序时在每个函数的开头加一个mcount函数调用,在每一个函数调用之前都会先调用这个mcount函数,在mcount中会保存函数的调用关系图和函数的调用时间和被调次数等信息。最终在程序退出时保存在gmon.out文件中。
这次代码做的主要优化是Hash Table的长度改变,从 26 变成 26*26 到最终的 26*26*26*26 可以明显的感觉到速度的提升。
还有一些小的优化就是词组提取过程中要访问单词的哈希表,起初采用了整个哈希表遍历的方式,后来发现只需要遍历对应行的单链表即可,也节省了不少时间。
下边这些数据是优化后的代码数据。
1、> g++ -pg -g -o h hw1.cpp
> ./h code/test6
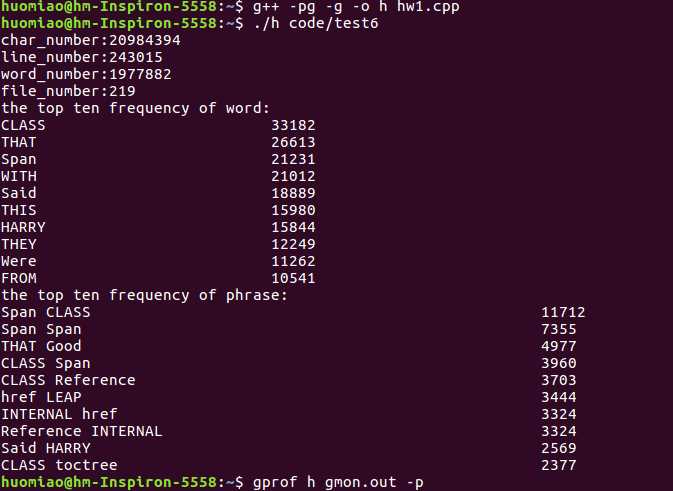
运行完之后生成了 gmon.out 文件。
2、> gprof h gmon.out -p
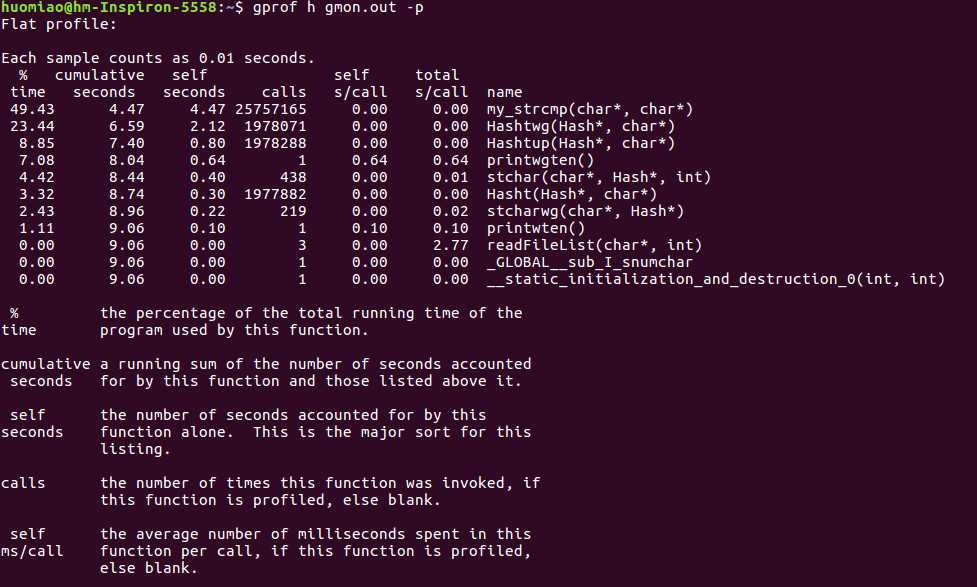
得到了每个函数的性能参数,时间占比什么的。。。
3、> gprof h gmon.out -q
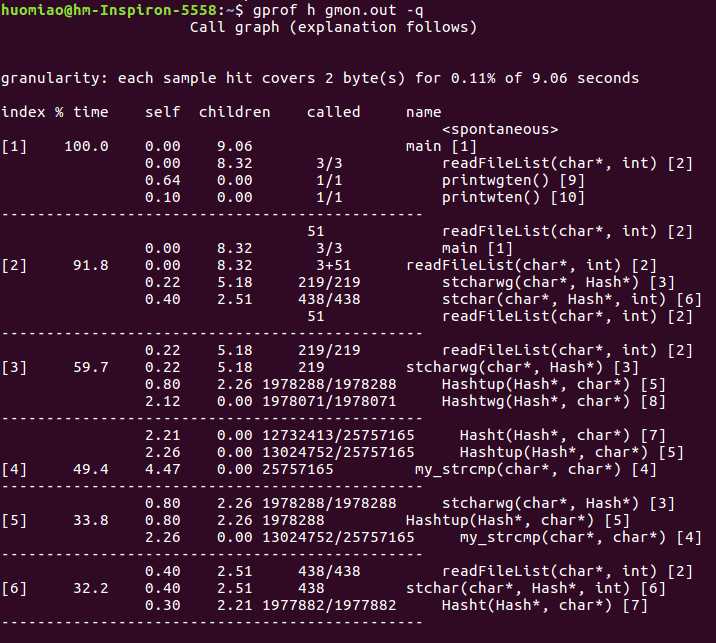
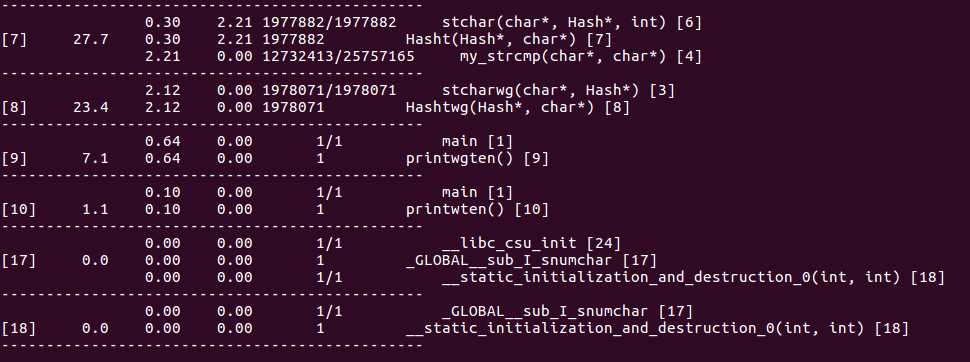
得到了函数之间的调用关系。。。
4、> gprof h gmon.out -A
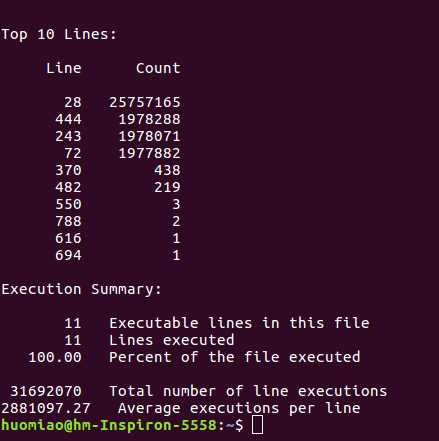
测试用例及分析过程:
根据作业的要求,设计了十个测试集,完成并验证了符合作业要求。(这里只列出六个做以说明。)
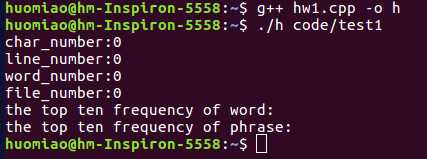
test1:多层多个不含任何文件的空文件夹集。
测试结果:所有结果都是0,测试正常,结果正确。
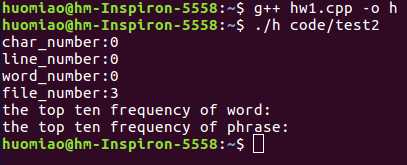
test2:文件夹中仅包含三个空文件。
测试结果:字符数、行数、单词数都是0,文件数:3,测试正常,结果正确。
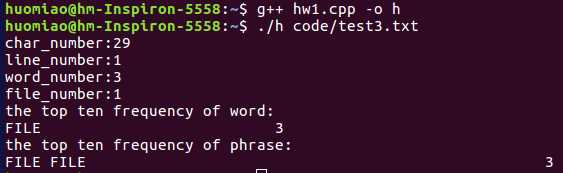
test3:test3.txt文件内容:file123 123file File///FILE; (同时也算测试了路径为单个文件程序也能照常运行)
测试结果:123file没有被算作单词,file123、FILE、File是同一个单词FILE,测试正常,结果正确。
test4:包含windows95、windows7、windows、windows32a、iPhone4、IPhone5的测试集。
测试结果:windows95、windows7都看作是和windows是同一单词,但和windoes32a不是同一单词;
iPhone4和IPhone5被认为是IPone5,测试正常,结果正确。
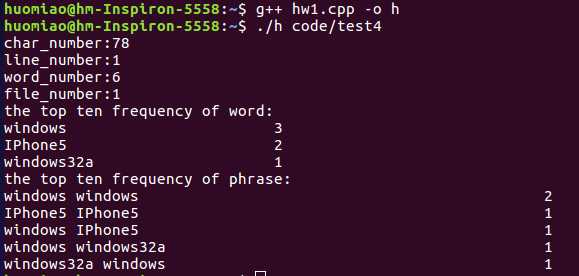
test5:文件夹中仅包含4个.txt大文件。
测试结果:和某同学对相同文件夹测试得到结果基本相同。测试正常,结果正确。
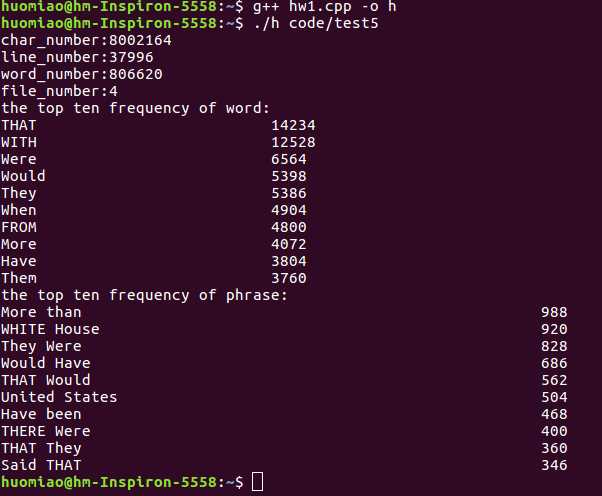
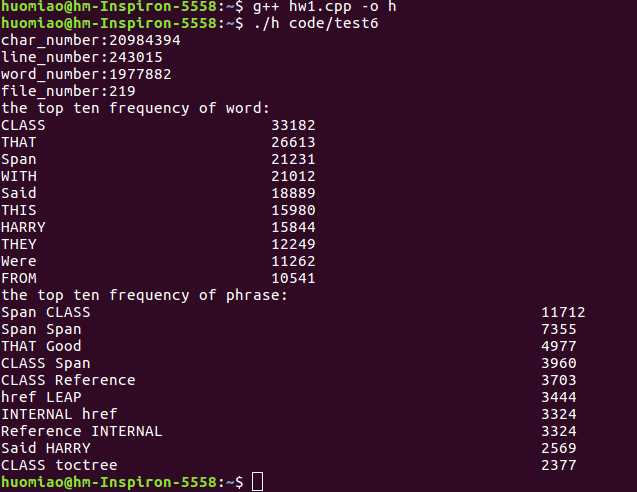
test6:文件夹中包含各种类型的文件。
测试结果:和某同学对相同文件夹测试得到结果基本相同。测试正常,结果正确。
此次项目获得的经验:
在此次项目的开发测试过程中,首先对问题的分析和解决方案的选取很重要,要把解决策略步骤化,代码模块化,并作模块化调试之后再联合调试。其次在写程序的时候要不断学习吸收新的知识,另外在debug的时候最好有个伙伴在旁边,这样能帮助你很快的解决一些小问题,节省很多时间。最后在完成初步调试通过后,要进行多方面多层次的大量测试,从中发现问题并改进,以确保代码的稳定性和正确性。