---恢复内容开始---
1、序列化和反序列化
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
为什么要保持序列化?
1、持久化状态
2、跨平台数据交互
各种语言之间,实现数据相互转换
2、json、eval、pickle
eval()虽然也能进行数据提取,但是,eval()只能识别python 定义的数据类型,用来做序列化不具有跨平台型
Json的使用
x="[1,2,true,null]"
res=json.loads(x)
print(res)
dic={‘name‘:‘egon‘,‘age‘:18}
a=json.dumps(dic)
print(a)
with open (r‘dbl.json‘,‘wt‘,encoding=‘utf-8‘) as f:
json.dump(dic,f)
with open(r‘dbl.json‘, ‘rt‘, encoding=‘utf-8‘) as f:
json.load(f)
json不识别列表
pickle可识别所有python数据类型,但只能在python内部使用,pickle的使用方法和 json基本一致
3、logging模块
-
- logging日志级别
logger1.debug(‘10调试‘) logger1.info(‘20 信息‘) logger1.warning(‘30警告‘) logger1.error(‘40错误‘) logger1.critical(‘50瘫痪‘)
-
- logging全局配置及调用
logger:产生日志的对象
Filter:过滤日志的对象
Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端
Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式
import logging
logging.basicConfig(
filename=‘access.log‘,
format=‘%(asctime)s - %(name)s - %(levelname)s - %(module)s - %(message)s‘,
datefmt=‘%Y-%m-%d, %H:%M:%S %p‘,level=20,)
#负责产生日志
logger1=logging.getLogger()
#handler控制打印到文件或终端
fh1=logging.FileHandler(filename=‘log1‘,encoding=‘utf-8‘)
sh=logging.StreamHandler()
#famtter1控制日志格式
famtter1=logging.Formatter(fmt=‘%(asctime)s - %(name)s - %(levelname)s - %(module)s - %(message)s‘,
datefmt=‘%Y-%m-%d, %H:%M:%S %p‘)
#为logger绑定handler
logger1.addHandler(fh1)
logger1.addHandler(sh)
#为handler绑定日志格式
fh1.setFormatter(famtter1)
sh.setFormatter(famtter1)
#控制日志级别
logger1.setLevel(10)
logger1.debug(‘调试‘)
logger1.info(‘20 信息‘)
logger1.warning(‘30警告‘)
logger1.error(‘40错误‘)
-
- Logger与Handler的级别
logger是第一级过滤,然后才能到handler,可以给logger和handler同时设置level
4、软件开发规范
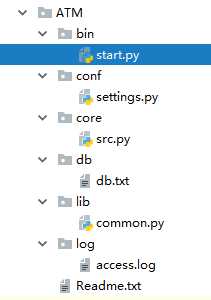
#===============>star.py
import sys,os
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
from core import src
if __name__ == ‘__main__‘:
src.run()
#===============>settings.py
import os
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
DB_PATH=os.path.join(BASE_DIR,‘db‘,‘db.json‘)
LOG_PATH=os.path.join(BASE_DIR,‘log‘,‘access.log‘)
LOGIN_TIMEOUT=5
"""
logging配置
"""
# 定义三种日志输出格式
standard_format = ‘[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]‘ ‘[%(levelname)s][%(message)s]‘ #其中name为getlogger指定的名字
simple_format = ‘[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s‘
id_simple_format = ‘[%(levelname)s][%(asctime)s] %(message)s‘
# log配置字典
LOGGING_DIC = {
‘version‘: 1,
‘disable_existing_loggers‘: False,
‘formatters‘: {
‘standard‘: {
‘format‘: standard_format
},
‘simple‘: {
‘format‘: simple_format
},
},
‘filters‘: {},
‘handlers‘: {
#打印到终端的日志
‘console‘: {
‘level‘: ‘DEBUG‘,
‘class‘: ‘logging.StreamHandler‘, # 打印到屏幕
‘formatter‘: ‘simple‘
},
#打印到文件的日志,收集info及以上的日志
‘default‘: {
‘level‘: ‘DEBUG‘,
‘class‘: ‘logging.handlers.RotatingFileHandler‘, # 保存到文件
‘formatter‘: ‘standard‘,
‘filename‘: LOG_PATH, # 日志文件
‘maxBytes‘: 1024*1024*5, # 日志大小 5M
‘backupCount‘: 5,
‘encoding‘: ‘utf-8‘, # 日志文件的编码,再也不用担心中文log乱码了
},
},
‘loggers‘: {
#logging.getLogger(__name__)拿到的logger配置
‘‘: {
‘handlers‘: [‘default‘, ‘console‘], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
‘level‘: ‘DEBUG‘,
‘propagate‘: True, # 向上(更高level的logger)传递
},
},
}
#===============>src.py
from conf import settings
from lib import common
import time
logger=common.get_logger(__name__)
current_user={‘user‘:None,‘login_time‘:None,‘timeout‘:int(settings.LOGIN_TIMEOUT)}
def auth(func):
def wrapper(*args,**kwargs):
if current_user[‘user‘]:
interval=time.time()-current_user[‘login_time‘]
if interval < current_user[‘timeout‘]:
return func(*args,**kwargs)
name = input(‘name>>: ‘)
password = input(‘password>>: ‘)
db=common.conn_db()
if db.get(name):
if password == db.get(name).get(‘password‘):
logger.info(‘登录成功‘)
current_user[‘user‘]=name
current_user[‘login_time‘]=time.time()
return func(*args,**kwargs)
else:
logger.error(‘用户名不存在‘)
return wrapper
@auth
def buy():
print(‘buy...‘)
@auth
def run():
print(‘‘‘
购物
查看余额
转账
‘‘‘)
while True:
choice = input(‘>>: ‘).strip()
if not choice:continue
if choice == ‘1‘:
buy()
#===============>db.json
{"egon": {"password": "123", "money": 3000}, "alex": {"password": "alex3714", "money": 30000}, "wsb": {"password": "3714", "money": 20000}}
#===============>common.py
from conf import settings
import logging
import logging.config
import json
def get_logger(name):
logging.config.dictConfig(settings.LOGGING_DIC) # 导入上面定义的logging配置
logger = logging.getLogger(name) # 生成一个log实例
return logger
def conn_db():
db_path=settings.DB_PATH
dic=json.load(open(db_path,‘r‘,encoding=‘utf-8‘))
return dic
#===============>access.log
[2017-10-21 19:08:20,285][MainThread:10900][task_id:core.src][src.py:19][INFO][登录成功]
[2017-10-21 19:08:32,206][MainThread:10900][task_id:core.src][src.py:19][INFO][登录成功]
[2017-10-21 19:08:37,166][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在]
[2017-10-21 19:08:39,535][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在]
[2017-10-21 19:08:40,797][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在]
[2017-10-21 19:08:47,093][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在]
[2017-10-21 19:09:01,997][MainThread:10900][task_id:core.src][src.py:19][INFO][登录成功]
[2017-10-21 19:09:05,781][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在]
[2017-10-21 19:09:29,878][MainThread:8812][task_id:core.src][src.py:19][INFO][登录成功]
[2017-10-21 19:09:54,117][MainThread:9884][task_id:core.src][src.py:19][INFO][登录成功]
5、 os模块
os模块是与操作系统交互的一个接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: (‘.‘)
os.pardir 获取当前目录的父目录字符串名:(‘..‘)
os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录
os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname
os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat(‘path/filename‘) 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
在Linux和Mac平台上,该函数会原样返回path,在windows平台上会将路径中所有字符转换为小写,并将所有斜杠转换为饭斜杠。 >>> os.path.normcase(‘c:/windows\\system32\\‘) ‘c:\\windows\\system32\\‘ 规范化路径,如..和/ >>> os.path.normpath(‘c://windows\\System32\\../Temp/‘) ‘c:\\windows\\Temp‘ >>> a=‘/Users/jieli/test1/\\\a1/\\\\aa.py/../..‘ >>> print(os.path.normpath(a)) /Users/jieli/test1
os路径处理
#方式一:推荐使用
import os
#具体应用
import os,sys
possible_topdir = os.path.normpath(os.path.join(
os.path.abspath(__file__),
os.pardir, #上一级
os.pardir,
os.pardir
))
sys.path.insert(0,possible_topdir)
#方式二:不推荐使用
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))