(1):分析网页

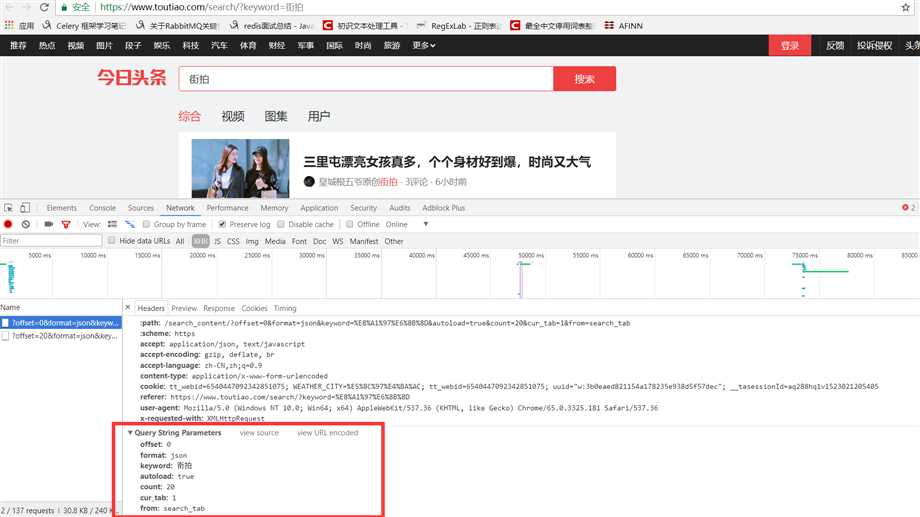
分析ajax的请求网址,和需要的参数。通过不断向下拉动滚动条,发现请求的参数中offset一直在变化,所以每次请求通过offset来控制新的ajax请求。
(2)上代码
a、通过ajax请求获取页面数据
# 获取页面数据 def get_page_index(offset, keyword): # 参数通过分析页面的ajax请求获得 data = { ‘offset‘: offset, ‘format‘: ‘json‘, ‘keyword‘: keyword, ‘autoload‘: ‘true‘, ‘count‘: ‘20‘, ‘cur_tab‘: ‘1‘, ‘from‘: ‘search_tab‘, } url = ‘https://www.toutiao.com/search_content/?‘ + urlencode(data) # 将字典转换为url参数形式 try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text else: return None except RequestException: print(‘请求索引页错误‘) return None
b、分析ajax请求的返回结果,获取图片集的url
# 分析ajax请求的返回结果,获取图片集的url def parse_page_index(html): data = json.loads(html) # 加载返回的json数据 if data and ‘data‘ in data.keys(): for item in data.get(‘data‘): yield item.get(‘article_url‘)

c、得到图集url后获取图集的内容
# 获取详情页的内容 def get_page_detail(url): try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text else: return None except RequestException: print(‘详情页页错误‘, url) return None
d、其他看完整代码
完整代码:
# -*- coding: utf-8 -*- # @Author : FELIX # @Date : 2018/4/4 12:49 import json import os from hashlib import md5 import requests from urllib.parse import urlencode from requests.exceptions import RequestException from bs4 import BeautifulSoup import re import pymongo from multiprocessing import Pool MONGO_URL=‘localhost‘ MONGO_DB=‘toutiao‘ MONGO_TABLE=‘toutiao‘ GROUP_START=1 GROUP_END=20 KEYWORD=‘街拍‘ client = pymongo.MongoClient(MONGO_URL) # 连接MongoDB db = client[MONGO_DB] # 如果已经存在连接,否则创建数据库 headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36‘, } # 获取页面数据 def get_page_index(offset, keyword): # 参数通过分析页面的ajax请求获得 data = { ‘offset‘: offset, ‘format‘: ‘json‘, ‘keyword‘: keyword, ‘autoload‘: ‘true‘, ‘count‘: ‘20‘, ‘cur_tab‘: ‘1‘, ‘from‘: ‘search_tab‘, } url = ‘https://www.toutiao.com/search_content/?‘ + urlencode(data) # 将字典转换为url参数形式 try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text else: return None except RequestException: print(‘请求索引页错误‘) return None # 分析ajax请求的返回结果,获取图片集的url def parse_page_index(html): data = json.loads(html) # 加载返回的json数据 if data and ‘data‘ in data.keys(): for item in data.get(‘data‘): yield item.get(‘article_url‘) # 获取详情页的内容 def get_page_detail(url): try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text else: return None except RequestException: print(‘详情页页错误‘, url) return None def parse_page_detail(html, url): # soup=BeautifulSoup(html,‘lxml‘) # print(soup) # title=soup.select(‘tetle‘).get_text() # print(title) images_pattern = re.compile(‘articleInfo:.*?title: \‘(.*?)\‘.*?content.*?\‘(.*?)\‘‘, re.S) result = re.search(images_pattern, html) if result: title = result.group(1) url_pattern = re.compile(‘"(http:.*?)"‘) img_url = re.findall(url_pattern, str(result.group(2))) if img_url: for img in img_url: download_img(img) # 下载 data = { ‘title‘: title, ‘url‘: url, ‘images‘: img_url, } return data def save_to_mongo(result): if result: if db[MONGO_TABLE].insert(result): # 插入数据 print(‘存储成功‘, result) return True return False def download_img(url): print(‘正在下载‘, url) try: response = requests.get(url, headers=headers) if response.status_code == 200: save_img(response.content) else: return None except RequestException: print(‘下载图片错误‘, url) return None def save_img(content): # os.getcwd()获取当前文件路径,用md5命名,保证不重复 file_path = ‘{}/imgs/{}.{}‘.format(os.getcwd(), md5(content).hexdigest(), ‘jpg‘) if not os.path.exists(file_path): with open(file_path, ‘wb‘)as f: f.write(content) def main(offset): html = get_page_index(offset, KEYWORD) for url in parse_page_index(html): html = get_page_detail(url) print(url,‘++++++++++++++++++++++++++++++++++++++++++++++++‘) print(html) if html: result = parse_page_detail(html, url) save_to_mongo(result) # print(result) # print(url) if __name__ == ‘__main__‘: groups = [i * 20 for i in range(GROUP_START, GROUP_END + 1)] pool = Pool() pool.map(main, groups)