一.三维卷积(Convolutions over Volumes)
前面已经讲解了对二维图像做卷积了,现在看看如何在三维立体上执行卷积。
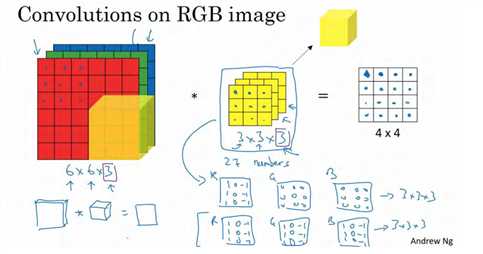
我们从一个例子开始,假如说你不仅想检测灰度图像的特征,也想检测 RGB 彩色图像的特征。彩色图像如果是 6×6×3,这里的 3 指的是三个颜色通道,你可以把它想象成三个 6×6图像的堆叠。为了检测图像的边缘或者其他的特征,不是把它跟原来的 3×3 的过滤器做卷积,而是跟一个三维的过滤器,它的维度是 3×3×3,这样这个过滤器也有三层,对应红绿、蓝三个通道。
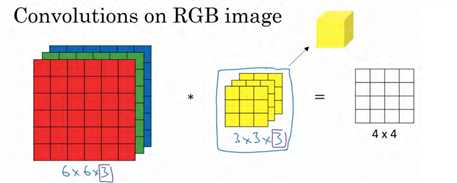
这里的第一个 6 代表图像高度,第二个 6 代表宽度,这个3 代表通道的数目。同样你的过滤器也有一个高,宽和通道数,并且图像的通道数必须和过滤器的通道数匹配,所以这两个数(紫色方框标记的两个数)必须相等。输出会是一个 4×4 的图像,注意是 4×4×1,最后一个数不是 3 了。
为了简化这个 3×3×3过滤器的图像,我们不把它画成 3 个矩阵的堆叠,而画成这样,一个三维的立方体。
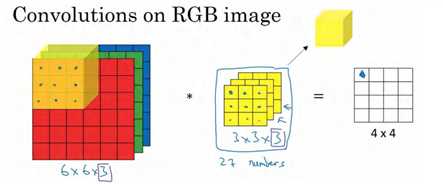
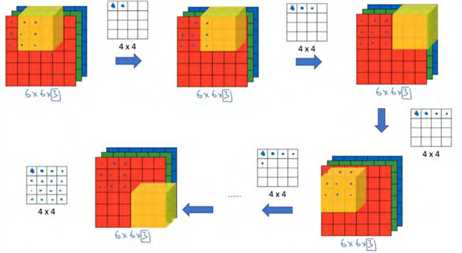
为了计算这个卷积操作的输出,你要做的就是把这个 3×3×3 的过滤器先放到最左上角的位置,这个 3×3×3 的过滤器有 27 个数, 27 个参数就是 3 的立方。依次取这 27 个数,然后乘以相应的红绿蓝通道中的数字。先取红色通道的前 9 个数字,然后是绿色通道,然后再是蓝色通道,乘以左边黄色立方体覆盖的对应的 27 个数,然后把这些数都加起来,就得到了输出的第一个数字。如果要计算下一个输出,你把这个立方体滑动一个单位,再与这 27 个数相乘,把它们都加起来,就得到了下一个输出,以此类推
。
那么,这个能干什么呢?举个例子,这个过滤器是 3×3×3 的, 如果你想检测图像红色通道的边缘, 那么你可以将第一个过滤器设为
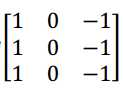
和之前一样,而绿色通道和红色通道全为 0, 如果你把这三个堆叠在一起形成一个 3×3×3 的过滤器,那么这就是一个检测垂直边界的过滤器,但只对红色通道有用
。
或者如果你不关心垂直边界在哪个颜色通道里,那么你可以用一个这样的过滤器
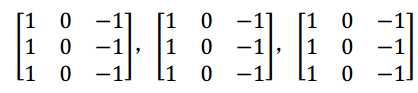
所有三个通道都是这样。所以通过设置过滤器参数,你就有了一个边界检测器, 3×3×3 的边界检测器,用来检测任意颜色通道里的边界。参数的选择不同,你就可以得到不同的特征检测器。
按照计算机视觉的惯例,当你的输入有特定的高宽和通道数时,你的过滤器可以有不同的高,不同的宽,但是必须一样的通道数。理论上,我们的过滤器只关注红色通道,或者只关注绿色或者蓝色通道也是可行的。
如果我们不仅仅想要检测垂直边缘怎么办?如果我们同时检测垂直边缘和水平边缘,还有 45°倾斜的边缘,还有 70°倾斜的边缘怎么做?换句话说,如果你想同时用多个过滤器怎么办?
我们可以同时使用多个过滤器。前面我们让这个 6×6×3 的图像和这个 3×3×3 的过滤器卷积,得到 4×4 的输出。(第一个)这可能是一个垂直边界检测器或者是学习检测其他的特征。第二个过滤器可以用橘色来表示,它可以是一个水平边缘检测器。
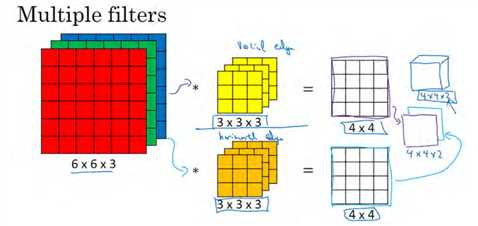
输入6×6×3 的图像和第一个过滤器卷积,可以得到第一个 4×4 的输出,然后卷积第二个过滤器,得到一个不同的 4×4 的输出。然后把这两个 4×4 的输出,取第一个把它放到前面,然后取第二个过滤器输出,放到后面。把这两个输出堆叠在一起,这样你就都得到了一个 4×4×2 的输出立方体。
总结
假设你有一个nxnxnc(通道数)的输入图像,设置步幅为 1,并且没有 padding 然后和nc‘个fxfxnc的滤波器卷积,这样你就会得到(n-f+1)x(n-f+1)xnc‘的输出。
补充:nc有两个术语,通道或者深度 。
二.单层卷积网络
这一节,主要讲解如何构建卷积神经网络的卷积层,下面来看个例子。 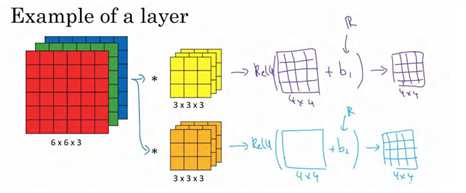
如图使用第一个过滤器进行卷积,得到第一个 4×4 矩阵。使用第二个过滤器进行卷积得到另外一个 4×4 矩阵。 对于每一层,加上一个偏差,通过 Python 的广播机制给这 16 个元素都加上同一偏差。然后应用非线性函数输出。对于第二个 4×4 矩阵,使用不同的偏置,进行同样的运算,最终得到另一个 4×4 矩阵。然后重复我们之前的步骤,把这两个矩阵堆叠起来,最终得到一个 4×4×2 的矩阵。
注意前向传播的一个操作就是z1 = w1a0+b1,其中a0=x,通过非线性函数计算得到a1=g(z1)。在卷积过程中,我们对这 27 个数进行操作,其实是 27×2,因为我们用了两个过滤器,我们取这些数做乘法。实际执行了一个线性函数,得到一个 4×4 的矩阵。卷积操作的输出结果是一个4×4 的矩阵,它的作用类似于
w1a0,也就是这两个 4×4 矩阵的输出结果,然后再加上偏差。
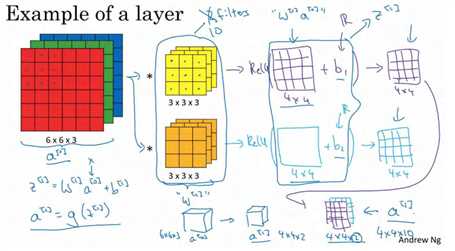
这一部分(图中蓝色边框标记的部分)就是应用激活函数 ReLU 之前的值,它的作用类 z1,最后应用非线性函数,得到的这个 4×4×2 矩阵,成为神经网络的下一层,也就是激活层。
这就是 a0到a1的的演变过程,首先执行线性函数,即所有元素相乘做卷积,再加上偏差,然后应用激活函数 ReLU。这样就通过神经网络的一层把一个6×6×3 的维度 a0演化出一个4×4×2 维度的 a1,这就是卷积神经网络的一层。
为了加深理解,我们来做一个练习。假设你有 10 个过滤器,而不是 2 个,神经网络的一层是 3×3×3,那么,这一层有多少个参数呢?我们来计算一下,每一层都是一个 3×3×3 的矩阵,因此每个过滤器有 27 个参数,也就是 27 个数。然后加上一个偏差,用参数b表示,现在参数增加到 28 个。上一节我画了 2 个过滤器,而现在我们有 10 个,加在一起是 28×10,也就是 280 个参数。
请注意一点,不论输入图片有多大, 1000×1000 也好, 5000×5000 也好,参数始终都是280 个。用这 10 个过滤器来提取特征,如垂直边缘,水平边缘和其它特征。即使这些图片很大, 参数却很少, 这就是卷积神经网络的一个特征, 叫作“避免过拟合”。 你已经知道到如何提取 10 个特征,可以应用到大图片中,而参数数量固定不变,此例中只有 28 个,相对较少。
最后我们总结一下用于描述卷积神经网络中的一层(以l层为例),也就是卷积层的各种标记
。

三.简单卷积网络示例
假设你有一张图片,你想做图片分类或图片识别,把这张图片输入定义为x,然后辨别图片中有没有猫,用 0 或 1 表示,这是一个分类问题,我们来构建适用于这项任务的卷积神经网络。针对这个示例,我用了一张比较小的图片,大小是 39×39×3,这样设定可以使其中一些数字效果更好。所以 nH0=nW0,即宽度和高度都等于39,nc0=3,即0层的通道数为3。
假设第一层我们用一个 3×3 的过滤器来提取特征,那么f1=3。设置s1=1,p1=0,所以宽度和高度使用valid卷积,如果有 10 个过滤器,神经网络下一层的激活值为 37×37×10,写 10 是因为我们用了 10 个过滤器, 37 是公式
(n+2p-f)/s+1的计算结果,所以输出是 37×37,它是一个 vaild 卷积,这是输出结果的大小。 第一层标记为 nH1=nW1=37,nc1=10,nc1等于第一层中过滤器的个数,这(37×37×10)是第一层激活值的维度。
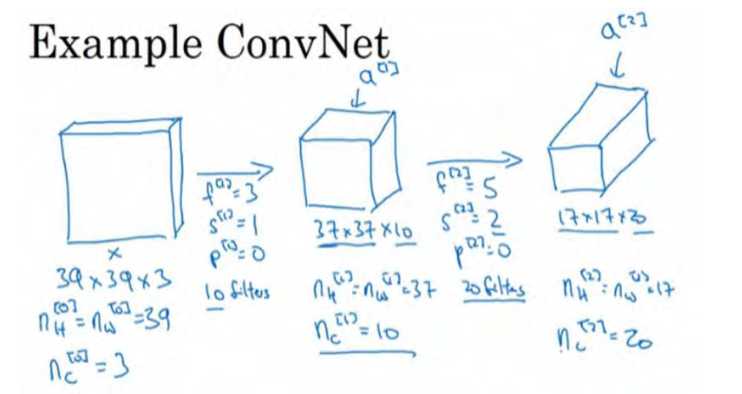
假设还有另外一个卷积层,这次我们采用的过滤器是 5×5 的矩阵。在标记法中,神经网络下一层的
f=5,即f2=5,步幅为2,即s2=2。padding 为 0,即 p2=0,且有 20 个过滤器。所以其输出结果会是一张新图像,这次的输出结果为 17×17×20,因为步幅是 2,维度缩小得很快,大小从 37×37 减小到 17×17,减小了一半还多,过滤器是 20 个,所以通道数也是 20, 17×17×20 即激活值
a2的维度,因此 nH2=nW2=17,nc2=20。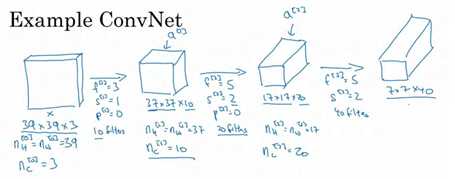
我们来构建最后一个卷积层,假设过滤器还是 5×5,步幅为 2,即 f3=5,s3=2,计算过程我跳过了,最后输出为 7×7×40,假设使用了 40 个过滤器。 padding 为 0, 40 个过滤器,最后结果为 7×7×40。
到此,这张 39×39×3 的输入图像就处理完毕了,为图片提取了 7×7×40 个特征,计算出来就是 1960 个特征。然后对该卷积进行处理,可以将其平滑或展开成 1960 个单元。平滑处
理后可以输出一个向量,其填充内容是 logistic 回归单元还是 softmax 回归单元,完全取决于我们是想识图片上有没有猫,还是想识别k种不同对象中的一种,用y_hat表示最终神经网络的预测输出。明确一点,最后这一步是处理所有数字,即全部的 1960 个数字,把它们展开成一个很长的向量。为了预测最终的输出结果,我们把这个长向量填充到 softmax 回归函数中 。

一个典型的卷积神经网络通常有三层,一个是卷积层,我们常常用 Conv 来标注。上一个例子,我用的就是 CONV。还有两种常见类型的层,一个是池化层,我们称之为 POOL。最后一个是全连接层,用 FC 表示。虽然仅用卷积层也有可能构建出很好的神经网络,但大部分神经望楼架构师依然会添加池化层和全连接层。幸运的是,池化层和全连接层比卷积层更容易设计。后两节课我们会讲解这两个概念以便你更好的了解神经网络中最常用的这几种层,你就可以利用它们构建更强大的网络了。
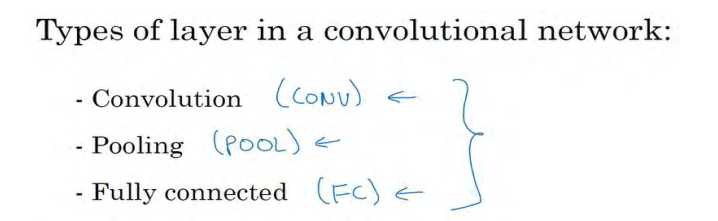
四. 池化层(Pooling Layers)
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性 。
先举一个池化层的例子,然后我们再讨论池化层的必要性。假如输入是一个 4×4 矩阵,用到的池化类型是最大池化(max pooling)。执行最大池化的树池是一个 2×2 矩阵。执行过程非常简单,把 4×4 的输入拆分成不同的区域,我把这个区域用不同颜色来标记。对于 2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值。
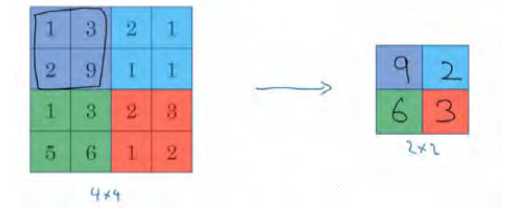
左上区域的最大值是 9,右上区域的最大元素值是 2,左下区域的最大值是 6,右下区域的最大值是 3。为了计算出右侧这 4 个元素值,我们需要对输入矩阵的 2×2 区域做最大值运算。这就像是应用了一个规模为 2 的过滤器,因为我们选用的是 2×2 区域,步幅是 2,这些就是最大池化的超参数。
因为我们使用的过滤器为 2×2,最后输出是 9。然后向右移动 2 个步幅,计算出最大值2。然后是第二行,向下移动 2 步得到最大值 6。最后向右移动 3 步,得到最大值 3。这是一个 2×2 矩阵,即
f=2,步幅为2,即s=2。
最大化操作的功能就是只要在任何一个象限内提取到某个特征,它都会保留在最大化的池化输出里。所以最大化运算的实际作用就是,如果在过滤器中提取到某个特征,那么保留其最大值。如果没有提取到这个特征,可能在右上象限中不存在这个特征,那么其中的最大值也还是很小,这就是最大池化的直观理解。
原文:https://www.cnblogs.com/zyly/p/8747396.html