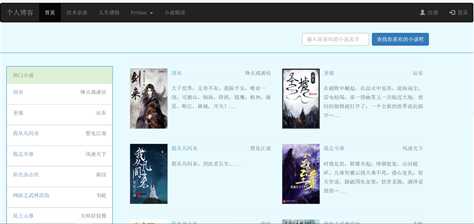
可以输入查询小说,如果小说不存在,就调用后台爬虫程序下载
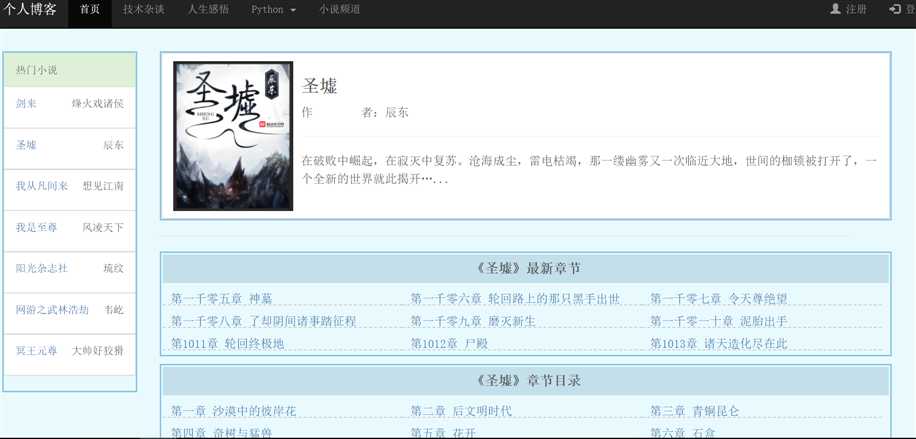
点开具体页面显示,小说章节列表,对于每个章节,如果本地没有就直接下载,可以点开具体章节开心的阅读,而没有广告,是的没有广告,纯净的

1 Centos7 + mysql 2 Flask==0.12.2 3 Flask-Bootstrap==3.3.7.1 4 Flask-Failsafe==0.2 5 Flask-Login==0.4.1 6 Flask-Mail==0.9.1 7 Flask-Migrate==2.1.1 8 Flask-Script==2.0.6 9 Flask-SQLAlchemy==2.3.2 10 Flask-WTF==0.14.2
1 # -*- coding: utf-8 -*- 2 # @Author: longzx 3 # @Date: 2018-04-16 21:41:55 4 # @cnblog:http://www.cnblogs.com/lonelyhiker/ 5 6 import requests 7 import sys 8 from bs4 import BeautifulSoup 9 from pymysql.err import ProgrammingError 10 from .spider_tools import (get_one_page, insert_many, insert_one, logger_deco, 11 select_fiction_many, select_fiction_one) 12 13 14 def search_fiction(name): 15 """输入小说名字 16 17 返回小说在网站的具体网址 18 """ 19 if name is None: 20 raise Exception(‘小说名字必须输入!!!‘) 21 22 url = ‘http://zhannei.baidu.com/cse/search?s=920895234054625192&q={}‘.format( 23 name) 24 html = get_one_page(url) 25 soup = BeautifulSoup(html, ‘html5lib‘) 26 result_list = soup.find(‘div‘, ‘result-list‘) 27 fiction_lst = result_list.find_all(‘a‘, ‘result-game-item-title-link‘) 28 fiction_url = fiction_lst[0].get(‘href‘) 29 fiction_name = fiction_lst[0].text.strip() 30 fiction_img = soup.find(‘img‘)[‘src‘] 31 fiction_comment = soup.find_all(‘p‘, ‘result-game-item-desc‘)[0].text 32 fiction_author = soup.find_all( 33 ‘div‘, ‘result-game-item-info‘)[0].find_all(‘span‘)[1].text.strip() 34 35 if fiction_name is None: 36 print(‘{} 小说不存在!!!‘.format(name)) 37 raise Exception(‘{} 小说不存在!!!‘.format(name)) 38 39 fictions = (fiction_name, fiction_url, fiction_img, fiction_author, 40 fiction_comment) 41 save_fiction_url(fictions) 42 43 return fiction_name, fiction_url 44 45 46 def get_fiction_list(fiction_name, fiction_url): 47 # 获取小说列表 48 fiction_html = get_one_page(fiction_url) 49 soup = BeautifulSoup(fiction_html, ‘html5lib‘) 50 dd_lst = soup.find_all(‘dd‘) 51 fiction_lst = [] 52 fiction_url_tmp = fiction_url.split(‘/‘)[-2] 53 for item in dd_lst[12:]: 54 fiction_lst_name = item.a.text.strip() 55 fiction_lst_url = item.a[‘href‘].split(‘/‘)[-1].strip(‘.html‘) 56 fiction_real_url = fiction_url + fiction_lst_url + ‘.html‘ 57 lst = (fiction_name, fiction_url_tmp, fiction_lst_url, 58 fiction_lst_name, fiction_real_url) 59 fiction_lst.append(lst) 60 return fiction_lst 61 62 63 def get_fiction_contents(fiction_lst): 64 iCnt = 0 65 total = len(fiction_lst) 66 for fiction in fiction_lst: 67 iCnt += 1 68 sel_sql = "select count(*) from fiction_content where fiction_id = ‘{}‘ and fiction_url= ‘{}‘".format( 69 fiction[1], fiction[2]) 70 if select_fiction_one(sel_sql)[1][0] > 0: 71 print(‘此章节[{}]已下载!!!‘.format(fiction[3])) 72 continue 73 get_fiction_content(fiction[-1]) 74 percent = float(iCnt) * 100 / float(total) 75 sys.stdout.write("%.4f" % percent) 76 sys.stdout.write("%\r") 77 sys.stdout.flush() 78 sys.stdout.write("100%!finish!\r") 79 sys.stdout.flush() 80 81 82 def get_fiction_content(fiction_url): 83 html = get_one_page(fiction_url) 84 soup = BeautifulSoup(html, ‘html5lib‘) 85 content = soup.find(id=‘content‘) 86 save_fiction_content(fiction_url, content) 87 88 89 def save_fiction_url(fictions): 90 sql = """insert into fiction(fiction_name,fiction_id,fiction_real_url,fiction_img,fiction_author,fiction_comment) 91 VALUES(‘%s‘,‘%s‘,‘%s‘,‘%s‘,‘%s‘,‘%s‘)""" 92 args = (fictions[0], fictions[1].split(‘/‘)[-2], fictions[1], fictions[2], 93 fictions[3], fictions[4]) 94 sel_sql = "select * from fiction where fiction_id = ‘{}‘".format(args[1]) 95 if select_fiction_one(sel_sql)[0] == 0: 96 insert_one(sql, args) 97 98 99 def save_fiction_lst(fiction_lst): 100 total = len(fiction_lst) 101 sel_sql = "select count(*) from fiction_lst where fiction_id= ‘{}‘".format( 102 fiction_lst[0][1]) 103 104 if select_fiction_one(sel_sql)[1][0] == total: 105 print(‘此小说已存在!!,无需下载‘) 106 return 1 107 108 for item in fiction_lst: 109 sql = "insert into fiction_lst(fiction_name,fiction_id,fiction_lst_url,fiction_lst_name,fiction_real_url)values(‘%s‘,‘%s‘,‘%s‘,‘%s‘,‘%s‘)" 110 sel_sql = "select count(*) from fiction_lst where fiction_lst_url = ‘{}‘ and fiction_id= ‘{}‘".format( 111 item[2], item[1]) 112 113 if select_fiction_one(sel_sql)[1][0] == 0: 114 insert_one(sql, item) 115 116 117 def save_fiction_content(fiction_url, fiction_content): 118 sql = """ 119 insert into fiction_content(fiction_id,fiction_url,fiction_content)values(‘%s‘,‘%s‘,‘%s‘) 120 """ 121 fiction_id = fiction_url.split(‘/‘)[-2] 122 fiction_conntenturl = fiction_url.split(‘/‘)[-1].strip(‘.html‘) 123 sel_sql = "select count(*) from fiction_content where fiction_url = ‘{}‘ and fiction_id=‘{}‘ ".format( 124 fiction_conntenturl, fiction_id) 125 if select_fiction_one(sel_sql)[1][0] == 0: 126 try: 127 insert_one(sql, (fiction_id, fiction_conntenturl, fiction_content)) 128 except ProgrammingError as p: 129 print(‘这个章节[{}]有毒,不下载了!!‘.format(fiction_conntenturl)) 130 print(‘error={}‘.format(p)) 131 return 132 133 134 def down_fiction_lst(f_name): 135 # 1.搜索小说 136 args = search_fiction(f_name) 137 138 # 2.获取小说目录列表 139 fiction_lst = get_fiction_list(*args) 140 # 3.保存小说目录列表 141 flag = save_fiction_lst(fiction_lst) 142 143 144 def down_fiction_content(f_url): 145 get_fiction_content(f_url) 146 147 148 @logger_deco 149 def main(name): 150 # 1.搜索小说 151 args = search_fiction(name) 152 153 # 2.获取小说目录列表 154 fiction_lst = get_fiction_list(*args) 155 156 # 3.保存小说目录列表 157 flag = save_fiction_lst(fiction_lst) 158 159 if flag == 1: 160 print(‘小说已存在,无需更新!!‘) 161 return 162 else: 163 # 3.1 获取每一章节内容 164 get_fiction_contents(fiction_lst) 165 print(‘下载完毕!!!‘) 166 167 168 if __name__ == ‘__main__‘: 169 lst = [‘圣墟‘, ‘剑来‘, ‘我从凡间来‘, ‘我是至尊‘, ‘飞剑问道‘, ‘龙王传说‘] 170 for x in lst: 171 main(x)
spider_tools.py
# -*- coding: utf-8 -*- # @Author: longzx # @Date: 2018-04-18 23:41:09 # @cnblog:http://www.cnblogs.com/lonelyhiker/ """ 爬虫常用工具包 将一些通用的功能进行封装 """ from functools import wraps from random import choice, randint from time import ctime, sleep, time import pymysql import requests from requests.exceptions import RequestException #请求头 headers = {} headers[ ‘Accept‘] = ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8‘ headers[‘Accept-Encoding‘] = ‘gzip, deflate, br‘ headers[‘Accept-Language‘] = ‘zh-CN,zh;q=0.9‘ headers[‘Connection‘] = ‘keep-alive‘ headers[‘Upgrade-Insecure-Requests‘] = ‘1‘ agents = [ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36‘ ] def get_one_page(url, proxies=None): #获取给定的url页面 while True: try: headers[‘User-Agent‘] = choice(agents) # 控制爬取速度 # sleep(randint(1, 3)) print(‘正在下载:‘, url) if proxies: # r = requests.get(url, headers=headers, timeout=5, proxies=proxies) r = requests.get(url) else: r = requests.get(url, headers=headers, timeout=5) except RequestException as r: continue else: if r.status_code == 200: r.encoding = r.apparent_encoding return r.text else: continue def get_db(host=‘localhost‘, user=‘lzx‘, passwd=‘123‘, database=‘blog‘): try: db = pymysql.connect( host=host, user=user, password=passwd, database=database, charset=‘utf8‘) except pymysql.err.OperationalError as e: print(‘error:‘, e) raise Exception(‘connect db error‘) return db def get_cursor(db, cursor=None): if cursor: return db.cursor(cursor=cursor) else: return db.cursor() def sql_executemany(cur, sql, lst): # 对于插入多条操作 return cur.executemany(sql, lst) def insert_one(sql, args): sql = sql % args sql_execute(sql) def insert_many(sql, args): db = get_db() cursor = get_cursor(db) cursor.executemany(sql, args) db.commit() cursor.close() db.close() def select_fiction_one(sql): db = get_db() with db.cursor() as cursor: cnt = cursor.execute(sql) lst = cursor.fetchone() db.close() return cnt, lst def select_fiction_many(sql): db = get_db() with db.cursor() as cursor: cursor.execute(sql) lst = cursor.fetchall() db.close() return lst def sql_execute(sql): db = get_db() try: with db.cursor() as cursor: cursor.execute(sql) db.commit() except Exception as e: print(‘sql=‘, sql) raise Exception(‘db error‘) finally: db.close()
models.py
# -*- coding: utf-8 -*- # @Author: longzx # @Date: 2018-03-19 23:44:05 # @cnblog:http://www.cnblogs.com/lonelyhiker/ from . import db class Fiction(db.Model): __tablename__ = ‘fiction‘ __table_args__ = {"useexisting": True} id = db.Column(db.Integer, primary_key=True) fiction_name = db.Column(db.String) fiction_id = db.Column(db.String) fiction_real_url = db.Column(db.String) fiction_img = db.Column(db.String) fiction_author = db.Column(db.String) fiction_comment = db.Column(db.String) def __repr__(self): return ‘<fiction %r> ‘ % self.fiction_name class Fiction_Lst(db.Model): __tablename__ = ‘fiction_lst‘ __table_args__ = {"useexisting": True} id = db.Column(db.Integer, primary_key=True) fiction_name = db.Column(db.String) fiction_id = db.Column(db.String) fiction_lst_url = db.Column(db.String) fiction_lst_name = db.Column(db.String) fiction_real_url = db.Column(db.String) def __repr__(self): return ‘<fiction_lst %r> ‘ % self.fiction_name class Fiction_Content(db.Model): __tablename__ = ‘fiction_content‘ __table_args__ = {"useexisting": True} id = db.Column(db.Integer, primary_key=True) fiction_url = db.Column(db.String) fiction_content = db.Column(db.String) fiction_id = db.Column(db.String)
views.py
# -*- coding: utf-8 -*- # @Author: longzx # @Date: 2018-03-20 20:45:37 # @cnblog:http://www.cnblogs.com/lonelyhiker/ from flask import render_template, request, redirect, url_for from app.xiaoshuo.xiaoshuoSpider import down_fiction_lst, down_fiction_content from . import fiction from ..models import Fiction, Fiction_Content, Fiction_Lst import requests from bs4 import BeautifulSoup from app import db @fiction.route(‘/book/‘) def book_index(): fictions = Fiction().query.all() print(fictions) return render_template(‘fiction_index.html‘, fictions=fictions) @fiction.route(‘/book/list/<f_id>‘) def book_lst(f_id): fictions = Fiction().query.all() for fiction in fictions: if fiction.fiction_id == f_id: break print(fiction) fiction_lst = Fiction_Lst().query.filter_by(fiction_id=f_id).all() if len(fiction_lst) == 0: print(fiction.fiction_name) down_fiction_lst(fiction.fiction_name) print(‘..........‘) return render_template(‘fiction_error.html‘, message=‘暂无此章节信息,请重新刷新下‘) fiction_name = fiction_lst[0].fiction_name return render_template( ‘fiction_lst.html‘, fictions=fictions, fiction=fiction, fiction_lst=fiction_lst, fiction_name=fiction_name) @fiction.route(‘/book/fiction/‘) def fiction_content(): fic_id = request.args.get(‘id‘) f_url = request.args.get(‘f_url‘) print(‘获取书本 id={} url={}‘.format(fic_id, f_url)) # 获取上一章和下一章信息 fiction_lst = Fiction_Lst().query.filter_by( fiction_id=fic_id, fiction_lst_url=f_url).first() id = fiction_lst.id fiction_name = fiction_lst.fiction_lst_name pre_id = id - 1 next_id = id + 1 fiction_pre = Fiction_Lst().query.filter_by( id=pre_id).first().fiction_lst_url fiction_next = Fiction_Lst().query.filter_by( id=next_id).first().fiction_lst_url f_id = fic_id # 获取具体章节内容 fiction_contents = Fiction_Content().query.filter_by( fiction_id=fic_id, fiction_url=f_url).first() if fiction_contents is None: print(‘fiction_real_url={}‘.format(fiction_lst.fiction_real_url)) r = requests.get(fiction_lst.fiction_real_url) down_fiction_content(fiction_lst.fiction_real_url) print(‘fiction_id={} fiction_url={}‘.format(fic_id, f_url)) fiction_contents = Fiction_Content().query.filter_by( fiction_id=fic_id, fiction_url=f_url).first() if fiction_contents is None: return render_template(‘fiction_error.html‘, message=‘暂无此章节信息,请重新刷新下‘) print(‘fiction_contents=‘, fiction_contents) fiction_content = fiction_contents.fiction_content return render_template( ‘fiction.html‘, f_id=f_id, fiction_name=fiction_name, fiction_pre=fiction_pre, fiction_next=fiction_next, fiction_content=fiction_content) @fiction.route(‘/book/search/‘) def f_search(): f_name = request.args.get(‘f_name‘) print(‘收到输入:‘, f_name) # 1.查询数据库存在记录 fictions = Fiction().query.all() for x in fictions: if f_name in x.fiction_name: fiction = x break if fiction: fiction_lst = Fiction_Lst().query.filter_by( fiction_id=fiction.fiction_id).all() if fiction_lst is None: down_fiction_lst(f_name) fictions = Fiction().query.all() print(‘fictions=‘, fictions) for fiction in fictions: if f_name in fiction.fiction_name: break if f_name not in fiction.fiction_name: return render_template(‘fiction_error.html‘, message=‘暂无此小说信息‘) fiction_lst = Fiction_Lst().query.filter_by( fiction_id=fiction.fiction_id).all() return render_template( ‘fiction_lst.html‘, fictions=fictions, fiction=fiction, fiction_lst=fiction_lst, fiction_name=fiction.fiction_name) else: fiction_name = fiction_lst[0].fiction_name return render_template( ‘fiction_lst.html‘, fictions=fictions, fiction=fiction, fiction_lst=fiction_lst, fiction_name=fiction_name) else: down_fiction_lst(f_name) fictions = Fiction().query.all() print(‘fictions=‘, fictions) for fiction in fictions: if f_name in fiction.fiction_name: break if f_name not in fiction.fiction_name: return render_template(‘fiction_error.html‘, message=‘暂无此小说信息‘) fiction_lst = Fiction_Lst().query.filter_by( fiction_id=fiction.fiction_id).all() return render_template( ‘fiction_lst.html‘, fictions=fictions, fiction=fiction, fiction_lst=fiction_lst, fiction_name=fiction.fiction_name)
templates
fiction_index.html 小说首页
{% extends "base.html" %} {% block styles %} {{super()}} <link href="{{url_for(‘static‘,filename=‘css/xscss.css‘)}}" rel="stylesheet"> {% endblock %} {% block content %} <!-- 搜索栏 --> <div class="container-fluid"> <div class="row"> <div class=" col-md-offset-7 col-md-4"> <form class="navbar-form navbar-right" role="search" action="/book/search/"> <div class="form-group"> <input name=‘f_name‘ type="text" class="form-control" placeholder="输入你喜欢的小说名字"> </div> <button type="submit" class="btn btn-primary">查找你喜欢的小说吧</button> </form> </div> <div class="col-md-1"></div> </div> </div> <!-- 搜索栏结束 --> <div class="box_section"> <!-- 文章主题开始 --> <div class="container-fluid"> <div class="row"> <!-- row begin --> <!-- 左边栏 --> <div class=" col-md-3 "> <br> <div class="box_cons"> <div class="panel panel-success"> <div class="panel-heading">热门小说</div> <ul class="list-group"> {% for fiction in fictions %} <li class="list-group-item"><a href="/book/list/{{fiction.fiction_id}}" class="pull-left">{{fiction.fiction_name}}</a><p class="text-right">{{fiction.fiction_author}}</p></li> {% endfor %} </ul> </div> </div> </div> <!--右边栏 --> <div class="col-md-8"> <div class="container-fluid"> <hr> {% for fiction in fictions %} {% if loop.index0 % 2 == 0 %} <div class="row"> {% endif %} <div class="col-md-6 pull-left"> <div class="media"> <a href="#" class="pull-left"><img src="{{fiction.fiction_img}}" width="100px" height="160px" /></a> <div class="media-body"> <div class="pull-left"><a href="/book/list/{{fiction.fiction_id}}">{{fiction.fiction_name}}</a></div> <div class="pull-right">{{fiction.fiction_author}}</div> <hr> {{fiction.fiction_comment}}... </div> </div> </div> {% if loop.index % 2 == 0 or loop.last %} </div> <hr> {% endif %} {% endfor %} </div> </div> <div class="col-md-1"></div> <!-- row end --> </div> </div> <!-- 文章主题结束 --> </div> {{super()}} {% endblock %}
fiction_lst.html 小说章节列表
{% extends "base.html" %} {% block styles %} {{super()}} <link href="{{url_for(‘static‘,filename=‘css/xscss.css‘,_external=True)}}" rel="stylesheet"> {% endblock %} {% block content %} <div class="container-fluid"> <div class="row"> <!-- row begin --> <div class="col-md-2"> <div class="box_cons"> <div class="panel panel-success"> <div class="panel-heading">热门小说</div> <ul class="list-group"> {% for fiction in fictions %} <li class="list-group-item"><a href="/book/list/{{fiction.fiction_id}}" class="pull-left">{{fiction.fiction_name}}</a><p class="text-right">{{fiction.fiction_author}}</p></li> {% endfor %} </ul> </div> </div> </div> <div class=" col-md-9"> <div class="box_con"> <div class="list-group-item"> <div class="media"> <a href="#" class="pull-left"><img src="{{fiction.fiction_img}}" width="160px" height="200px" /></a> <div class="media-body"> <div ><h3><b>{{fiction.fiction_name}}</b></h3></div> <div ><p>作 者:{{fiction.fiction_author}}</p></div> <hr> {{fiction.fiction_comment}}... </div> </div> </div> </div> <hr> <div class="box_con"> <div id="list"> <dl > <dt>《{{fiction_name}}》最新章节</dt> {% for item in fiction_lst[-9:] %} <dd><a href="/book/fiction/?id={{item.fiction_id}}&f_url={{item.fiction_lst_url}}">{{item.fiction_lst_name}}</a></dd> {% endfor %} </dl> </div> </div> <div class="box_con"> <div id="list"> <dl > <dt>《{{fiction_name}}》章节目录</dt> {% for item in fiction_lst %} <dd><a href="/book/fiction/?id={{item.fiction_id}}&f_url={{item.fiction_lst_url}}">{{item.fiction_lst_name}}</a></dd> {% endfor %} </dl> </div> </div> </div> <!-- row end --> </div> </div> {{super()}} {% endblock%}
fiction.html 小说章节内容
{% extends "base.html" %} {% block styles %} {{super()}} <link href="{{url_for(‘static‘,filename=‘css/xscss.css‘,_external=True)}}" rel="stylesheet"> {% endblock %} {% block content %} <div class="container-fluid"> <div class="row"> <!-- row begin --> <div class="col-md-offset-1 col-md-9 col-md-offset-1"> <div class="content_read"> <div class="box_con"> <div class="bookname"> <h1><p class="text-center">{{fiction_name}}</p></h1> </div> <div class="bottem1"> <p class="text-center"> <a id="pager_prev" href="/book/fiction/?id={{f_id}}&f_url={{fiction_pre}}" target="_top" class="pre">上一章</a> ← <a id="pager_current" href="/book/list/{{f_id}}" target="_top" title="" class="back">章节列表</a> → <a id="pager_next" href="/book/fiction/?id={{f_id}}&f_url={{fiction_next}}" target="_top" class="next">下一章</a> </p> </div> <div class="lm"></div> {{fiction_content|safe}} </div> </div> </div> <!-- row end --> </div> </div> {{super()}} {% endblock%}
有个很奇怪的问题,就是我想在使用爬虫爬取信息使用flask_sqlalchemy 存储数据是在spider_tools.py中 get_one_page,上面代码可以看出我的设想是如果下载不成功就一直下载直到成功,如果自己创建数据库对象就像上面的那样,没问题,就是在页面点击搜索下载的时候,可能存在flask db对象和我自己创建db对象,数据会发生缓存,flask的db不能及时获取,爬取数据要在刷新下重新请求数据库就可以看到数据。
2.如果我在spider_tools.py使用flask的db对象,在get_one_page中哪个while循环当发生异常时候,我设置的是异常也不退出循环,当我使用这用模式的时候,try except 好像没起作用flask直接异常退出了,有大神知道怎么回事吗,求指点下
原文:https://www.cnblogs.com/lonelyhiker/p/8878526.html
