Rerfences
实验平台:
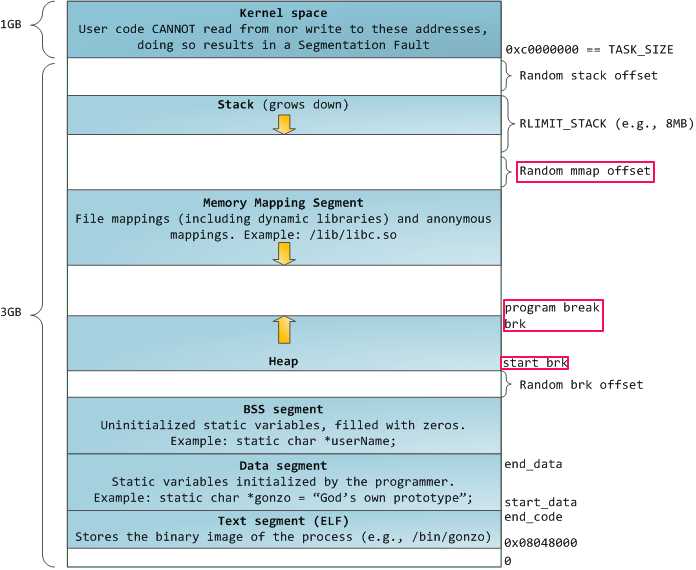
fig 1. 32bit linux 虚拟内存布局
fig 1展示了linux 32bit系统上虚拟内存布局,代码段(text segment)从0x0804800开始,接下来的分别是
BSS segment:存放未经初始化或初始化为0的静态变量,全局变量;
常用的内存分配:
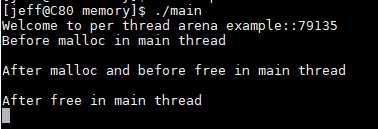
c标准库提供的malloc使用的是ptmalloc2,经过以下的测试程序观察一下malloc内存分配的具体情况:
1 /* Per thread arena example. */ 2 #include <stdio.h> 3 #include <stdlib.h> 4 #include <pthread.h> 5 #include <unistd.h> 6 #include <sys/types.h> 7 8 void* threadFunc(void* arg) { 9 printf("Before malloc in thread 1\n"); 10 getchar(); 11 char* addr = (char*) malloc(1000); 12 printf("After malloc and before free in thread 1\n"); 13 getchar(); 14 free(addr); 15 printf("After free in thread 1\n"); 16 getchar(); 17 } 18 19 int main() { 20 pthread_t t1; 21 void* s; 22 int ret; 23 char* addr; 24 25 printf("Welcome to per thread arena example::%d\n",getpid()); 26 printf("Before malloc in main thread\n"); 27 getchar(); 28 addr = (char*) malloc(1000); 29 printf("After malloc and before free in main thread\n"); 30 getchar(); 31 free(addr); 32 printf("After free in main thread\n"); 33 getchar(); 34 ret = pthread_create(&t1, NULL, threadFunc, NULL); 35 if(ret) 36 { 37 printf("Thread creation error\n"); 38 return -1; 39 } 40 ret = pthread_join(t1, &s); 41 if(ret) 42 { 43 printf("Thread join error\n"); 44 return -1; 45 } 46 return 0; 47 }
测试程序摘自[Understanding glibc malloc]
主线程调用malloc分配1000byte,从线程分配1000byte,在主线程与分线程之间通过getchar与控制台交互;

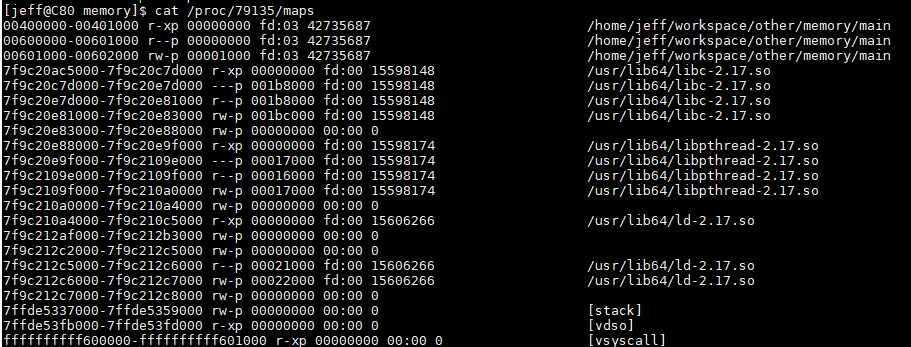
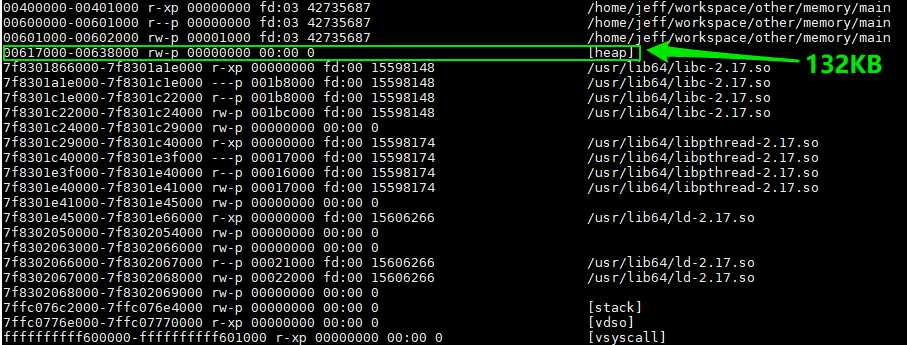
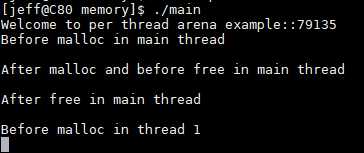
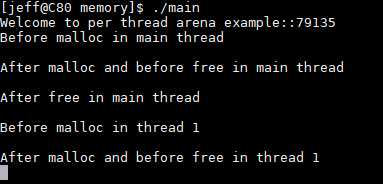
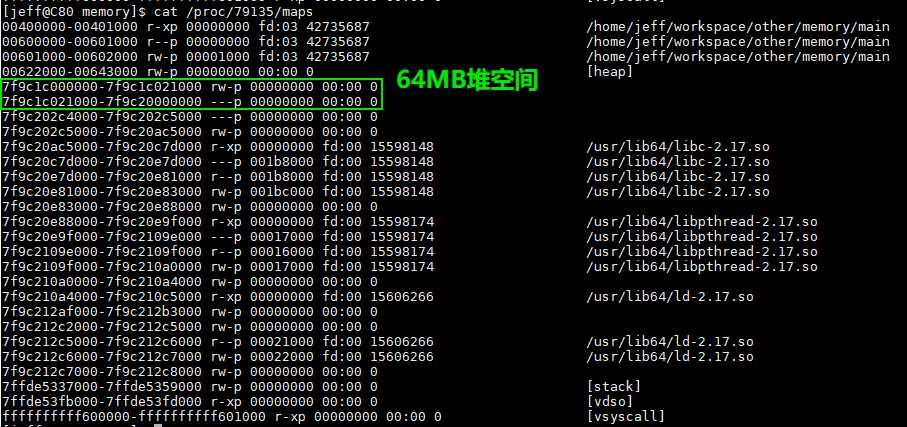
注意:当用户请求大于128KB时(比如说malloc(132*1024))并且此时是没有足够的内存空间来满足用户请求的,此时,无论是从main arena中或是从thread arena中的内存分配采用的都是mmap系统调用(而不是brk系统调用)
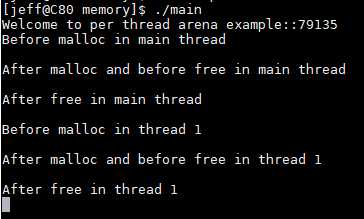
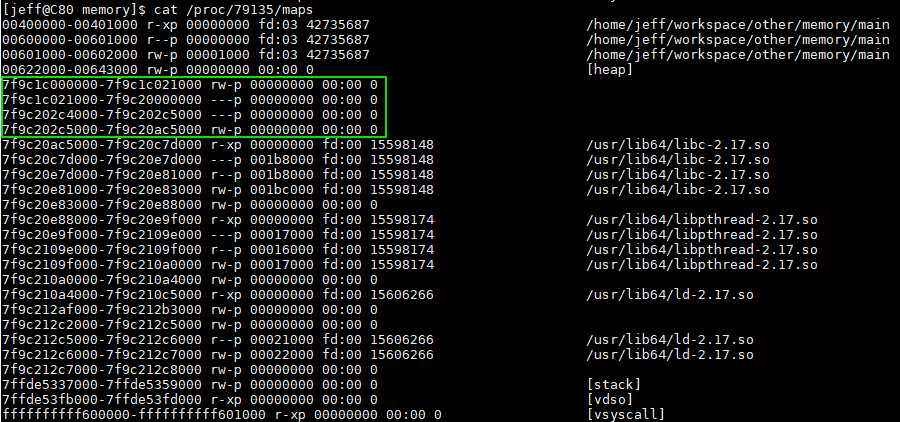
上述内容可以概括为:
在上面的例子中,main thread中包含main arena,thread1中包含thread arena。这里会引申出一个问题:是不是有多少线程就会有多少arena,即arena和thread之间的关系时一一对应的?答案当然是否定的:
对于32bit系统:
arena个数 = 2*core个数 + 1;(在[Understanding glibc malloc]写成了2*number of cores)
对于64bit系统:
arena个数 = 8*core个数 + 1;
举例来说,对于一个运行在32bit单核系统上的4threads的多线程应用程序(3 slave thread + main thread)。由上述公式可以得到:arena个数为3:
glibc的堆内存管理主要涉及三个数据结构:
1 typedef struct _heap_info 2 { 3 mstate ar_ptr; /* Arena for this heap. */ 4 struct _heap_info *prev; /* Previous heap. */ 5 size_t size; /* Current size in bytes. */ 6 size_t mprotect_size; /* Size in bytes that has been mprotected PROT_READ|PROT_WRITE. */ 7 /* Make sure the following data is properly aligned, particularly that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of MALLOC_ALIGNMENT. */ 8 char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK]; 9 } heap_info;
1 struct malloc_state 2 { 3 /* Serialize access. */ 4 mutex_t mutex; 5 /* Flags (formerly in max_fast). */ 6 int flags; 7 /* Fastbins */ 8 mfastbinptr fastbinsY[NFASTBINS]; 9 /* Base of the topmost chunk -- not otherwise kept in a bin */ 10 mchunkptr top; 11 /* The remainder from the most recent split of a small request */ 12 mchunkptr last_remainder; 13 /* Normal bins packed as described above */ 14 mchunkptr bins[NBINS * 2 - 2]; 15 /* Bitmap of bins */ 16 unsigned int binmap[BINMAPSIZE]; 17 /* Linked list */ 18 struct malloc_state *next; 19 /* Linked list for free arenas. */ 20 struct malloc_state *next_free; 21 /* Memory allocated from the system in this arena. */ 22 INTERNAL_SIZE_T system_mem; 23 INTERNAL_SIZE_T max_system_mem; 24 };
1 struct malloc_chunk { 2 /* #define INTERNAL_SIZE_T size_t */ 3 INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */ 4 INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */ 5 struct malloc_chunk* fd; /* double links -- used only if free. 这两个指针只在free chunk中存在*/ 6 struct malloc_chunk* bk; 7 /* Only used for large blocks: pointer to next larger size. */ 8 struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */ 9 struct malloc_chunk* bk_nextsize; 10 };
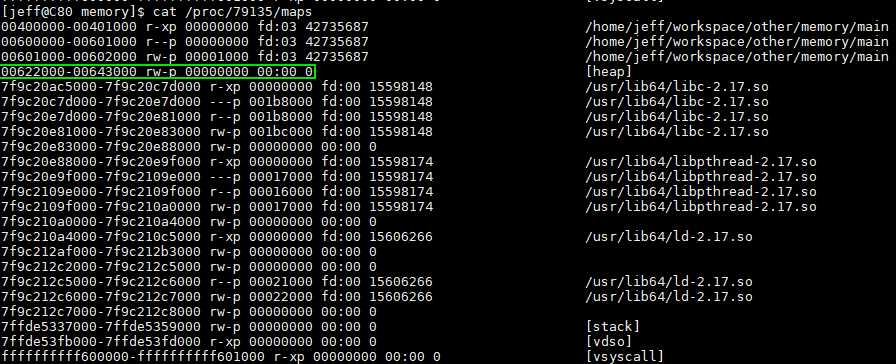
main arena只有一个heap,因此没有heap_info结构。当main arena用尽了所有空间时,会通过sbrk系统调用增加heap空间(连续的空间),直到碰到mmap段;
与thread arena不同的是,main arena的arena header不是sbrk heap segment的一部分。它是一个全局变量,因此,它存在于libc.so的data segment。
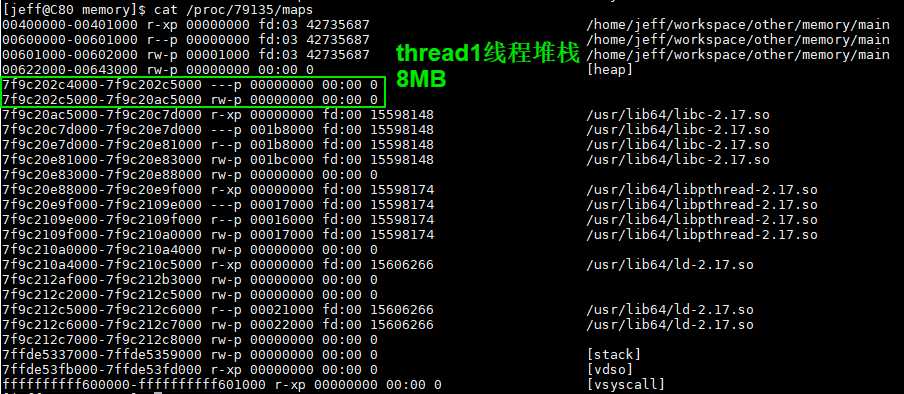
__heap_info中的ar_ptr指向当前thread的thread arena(malloc_state),prev指向前一个thread的heap_info结构体(main thread没有heap_info结构体);
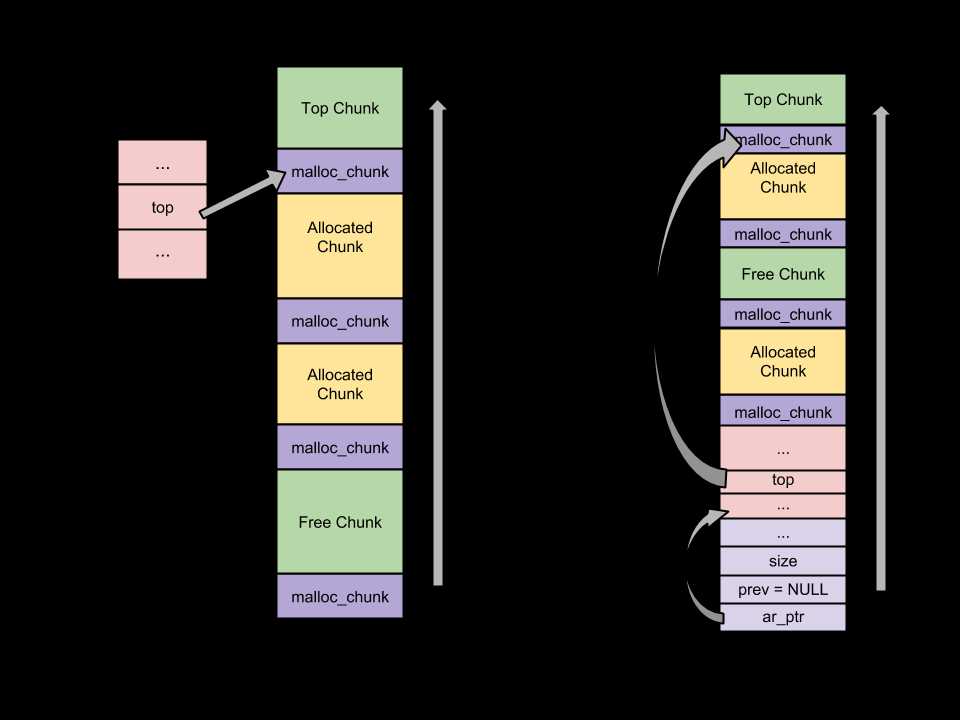
从图中可以看到,thread arena只含有一个malloc_state(即arena header),却有两个heap_info(即heap_header);
由于两个heap segments是通过mmap分配的内存,两者在内存布局上并不相邻,而是属于不同的内存区间,所以为了便于管理,malloc将第二个heap_info结构体的prev成员指向了第一个heap_info结构的其实位置(即ar_ptr),而第一个heap_info结构体的ar_ptr成员指向了malloc_state,这样就构成了单链表,方便后续管理。
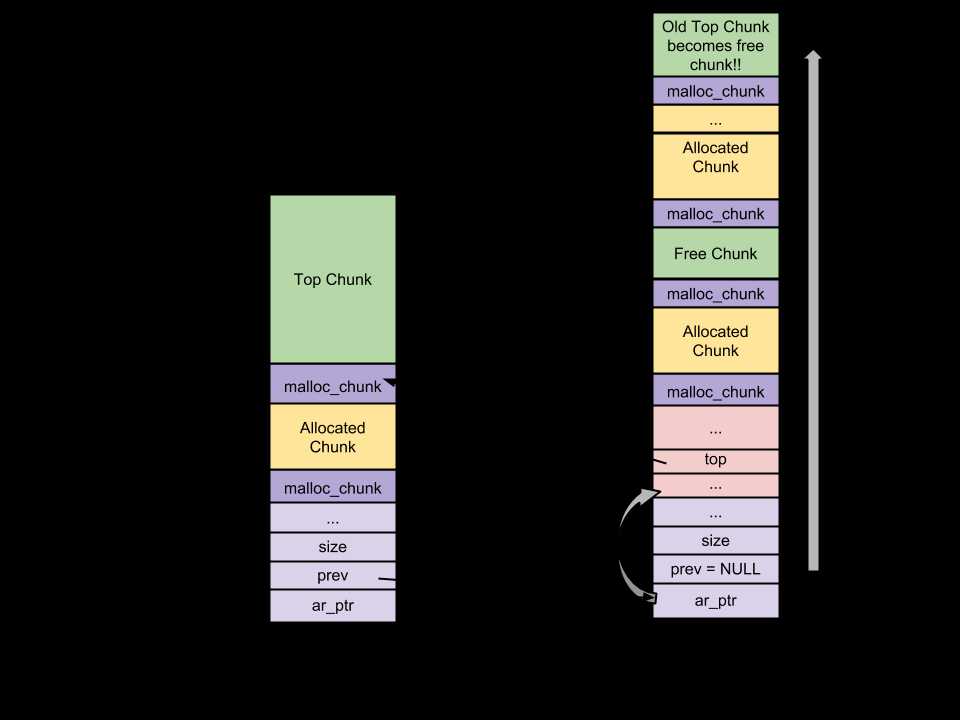
在glibic malloc中将整个堆内存空间分成了连续的,大小不一的chunk,即对于堆内存管理而言,chunk就是最小操作单位:
Free chunk
Top chunk
Last Remainder chunk
prev_sive:如果前一个chunk是空间的,那么该field会包含前一段chunk的size。否则,该field会包含前一个chunk的用户数据;
PREV_INUSE(P):当 前一个chunk已经被分配时,置位;
IS_MMAPPED(M):当chunk是被mmap的时候,置位;
NON_MAIN_ARENA(N):当chunk是属于thread arena时,置位;
NOTE:
malloc_chunk结构体的其他field(如下图),这些field可以用来存储用户数据;


prev_size:没有相邻的两个空间chunk(因为会被合并)。
size:包含free chunk的大小;
fd:指向双向链表中下一个chunk;
bk:指向双向链表中上一个chunk;

BINS:存储freelist的数据结构。每一个bin中的chunk大小不同
Fast bin
Unsorted bin
Small bin
Large bin
fastbinsY: the array hold fast bins
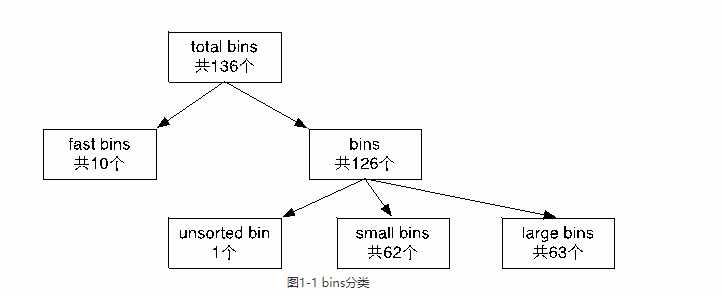
bins: the array hold unsorted, small and large bins. 总共有126个bins并且被分成以下:
Bin1:unsorted bin
Bin2 - Bin63:small bin
Bin64 - Bin126:Large bin
1 struct malloc_state 2 { 3 …… 4 /* Fastbins */ 5 mfastbinptr fastbinsY[NFASTBINS]; 6 …… 7 /* Normal bins packed as described above */ 8 mchunkptr bins[NBINS * 2 - 2]; // #define NBINS 128 9 …… 10 }; 11 这里mfastbinptr的定义:typedef struct malloc_chunk *mfastbinptr; 12 mchunkptr的定义:typedef struct malloc_chunk* mchunkptr;
1 struct malloc_chunk { 2 /* #define INTERNAL_SIZE_T size_t */ 3 INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */ 4 INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */ 5 struct malloc_chunk* fd; /* 这两个指针只在free chunk中存在*/ 6 struct malloc_chunk* bk; 7 /* Only used for large blocks: pointer to next larger size. */ 8 struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */ 9 struct malloc_chunk* bk_nextsize; 10 };
其中fd和bk指针就是指向当前chunk
Fast bin:在内存分配和释放过程中,fast bin是所有bin中操作速度最快的。 减少对大内存块的切割次数
chunk size表示malloc_chunk的实际整体大小;
chunk unused size表示malloc chunk中刨除诸如prev_size,size,fd和bk这类辅助成员之后的实际可用大小。因此,对于free chunk而言,其实际可用大小比实际整体大小少16字节;
fast bin 的个数:10个;
每个fast bin都是一个单链表(只使用fd指针)?为什么是单链表呢?因为在fast bin中无论是添加还是移除fast chunk,都是对”链表尾“进行操作,而不会对其中某个中间的fast chunk进行操作。更具体点就是LIFO(后入先出)算法:添加操作(free内存)就是将心的fast chunk加入链表尾,删除操作(malloc内存)就是将链表尾部的fast chunk删除。需要注意的是,为了实现LIFO算法,fastbinsY数组中每个fastbin元素均指向了该链表的rear end(尾节点),而尾节点通过其fd指针指向前一个节点,依次类推;
chunk size:10个fast bin中所包含的fast chunk size是按照步进8字节排列的,即第一个fast bin中所有fast chunk size均为16字节,第二个fast bin中为24字节,以此类推。在进行malloc初始化的时候,最大的fast chunk size被设置为80字节(chunk unused size为64字节),因此默认情况下大小为16到80字节的chunk被分类到fast chunk;
不会对free chunk进行合并操作。鉴于设计fast bin的初衷就是进行快速的小内存分配和释放,因此系统将属于fast bin的chunk的P(未使用标志位)总是设置为1,这样即使当fast bin中有某个chunk同一个free chunk相邻的时候,系统也不会自动进行合并操作,而是保留两位。虽然这样做可能会造成额外的碎片化问题,但瑕不掩瑜;
malloc(fast chunk)操作:即用户通过malloc请求的大小属于fast chunk的大小范围(注意:用户请求size+16字节就是实际内存chunk size)。在初始化的时候fast bin支持的最大内存以及所有fast bin链表都是空的,所以当最开始使用malloc申请内存的时候,即使申请的内存大小属于fast chunk的内存大小(即16字节到80字节),它不会交由fast bin来处理,而是向下传递交由small bin来处理,如果small bin也为空的话就交给unsorted bin处理:
1 /* Maximum size of memory handled in fastbins. */ 2 static INTERNAL_SIZE_T global_max_fast; 3 /* offset 2 to use otherwise unindexable first 2 bins */ 4 /*这里SIZE_SZ就是sizeof(size_t),在32位系统为4,64位为8,fastbin_index就是根据要malloc的size来快速计算该size应该属于哪一个fast bin,即该fast bin的索引。因为fast bin中chunk是从16字节开始的,所有这里以8字节为单位(32位系统为例)有减2*8 = 16的操作!*/ 5 #define fastbin_index(sz) 6 ((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2) 7 /* The maximum fastbin request size we support */ 8 #define MAX_FAST_SIZE (80 * SIZE_SZ / 4) 9 #define NFASTBINS (fastbin_index (request2size (MAX_FAST_SIZE)) + 1)
small bins:ptmalloc使用smalls管理空闲小chunk,每个small bin中的chunk大小与bin的index有如下关系:
chunk size = 2 * SIZE_SZ * index,SIZE_SZ为4B的平台上,small bins中的chunk大小是以8B为公差的等差数列,在SIZE_SZ为8B的平台上,small bins的chunk大小是以16B为公差的等差数列;
unsorted bins:回收的的chunk不会直接返回到对应的bin,而是先返回到unsorted bins中,从而提高内存利用的局部性;可以将unsorted bin看作是small bins和large bins的cache,只有一个unsorted bin,以双链表形式管理空闲chunk,空闲chunk不排序,所有的chunk在回收时都要先放到unsorted bin中,分配时,如果在unsorted bin中没有合适的chunk的,就会把cunsorted bin中所有的chunk分别加入到所属的bin中,然后再在bin中分配合适的chunk;
large bins:chunk size = 512 + 64 * index;
原文:https://www.cnblogs.com/HaHaJeff/p/8868539.html