K近邻算法(KNN)是指一个样本如果在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。即每个样本都可以用它最接近的k个邻居来代表。KNN算法适合分类,也适合回归。KNN算法广泛应用在推荐系统、语义搜索、异常检测。
KNN算法分类原理图:
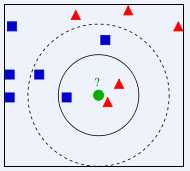
图中绿色的圆点是归属在红色三角还是蓝色方块一类?如果K=5(离绿色圆点最近的5个邻居,虚线圈内),则有3个蓝色方块是绿色圆点的“最近邻居”,比例为3/5,因此绿色圆点应当划归到蓝色方块一类;如果K=3(离绿色圆点最近的3个邻居,实线圈内),则有两个红色三角是绿色圆点的“最近邻居”,比例为2/3,那么绿色圆点应当划归到红色三角一类。
由上看出,该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
KNN算法实现步骤:
1. 数据预处理
2. 构建训练集与测试集数据
3. 设定参数,如K值(K一般选取样本数据量的平方根即可,3~10)
4. 维护一个大小为K的的按距离(欧氏距离)由大到小的优先级队列,用于存储最近邻训练元组。随机从训练元组中选取K个元组作为初始的最近邻元组,分别计算测试元组到这K个元组的距离将训练元组标号和距离存入优先级队列
5. 遍历训练元组集,计算当前训练元组与测试元组的距离L,将所得距离L与优先级队列中的最大距离Lmax
6. 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列
7. 遍历完毕,计算优先级队列中K个元组的多数类,并将其作为测试元组的类别
8. 测试元组集测试完毕后计算误差率,继续设定不同的K值重新进行训练,最后取误差率最小的K值。
R语言实现过程:
R语言中进行K近邻算法分析的函数包有class包中的knn函数、caret包中的train函数和kknn包中的kknn函数
knn(train, test, cl, k = 1, l = 0, prob = FALSE, use.all = TRUE)
参数含义:
train:含有训练集的矩阵或数据框
test:含有测试集的矩阵或数据框
cl:对训练集进行分类的因子变量
k:邻居个数
l:有限决策的最小投票数
prob:是否计算预测组别的概率
use.all:控制节点的处理办法,即如果有多个第K近的点与待判样本点的距离相等,默认情况下将这些点都作为判别样本点;当该参数设置为FALSE时,则随机选择一个点作为第K近的判别点。
(样本数据说明:文中样本数据描述一女士根据约会对象每年获得飞行里程数;玩视频游戏所消耗的时间百分比;每周消费的冰淇淋公升数,将自己约会对象划分为三种喜好类型)
代码:
#导入分析数据
mydata <- read.table("C:/Users/Cindy/Desktop/婚恋/datingTestSet.txt")
str(mydata)
colnames(mydata) <- c(‘飞行里程‘,‘视频游戏时间占比‘,‘食用冰淇淋数‘,‘喜好分类‘)
head(mydata)
#数据预处理,归一化
norfun <- function(x){
z <- (x-min(x))/(max(x)-min(x))
return(z)
}
data <- as.data.frame(apply(mydata[,1:3],2,norfun))
data$喜好分类<-mydata[,4]
#建立测试集与训练集样本
library(caret)
set.seed(123)
ind <- createDataPartition(y=data$喜好分类,times = 1,p=0.5,list = F)
testdata <- data[-ind,]
traindata <- data[ind,]
#KNN算法
library(class)
kresult <- knn(train = traindata[,1:3],test=testdata[,1:3],cl=traindata$喜好分类,k=3)
#生成实际与预判交叉表和预判准确率
table(testdata$喜好分类,kresult)
sum(diag(table(testdata$喜好分类,kresult)))/sum(table(testdata$喜好分类,kresult))
运行结果:

根据结果可知该分类的正确率为95%。
KNN算法优缺点:
优点:
1.易于理解和实现
2. 适合对稀有事件进行分类
3.特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好
缺点:
计算量较大,需要计算新的数据点与样本集中每个数据的“距离”,以判断是否是前K个邻居)
改进:
分类效率上,删除对分类结果影响较小的属性;分类效果上,采用加权K近邻算法,根据距离的远近赋予样本点不同的权重值,kknn包中的kknn函数即采用加权KNN算法。
2018-04-30 22:31:25
原文:https://www.cnblogs.com/wxyz94/p/8972280.html