




https://statweb.stanford.edu/~owen/mc/Ch-var-is.pdf
https://zhuanlan.zhihu.com/p/29934206


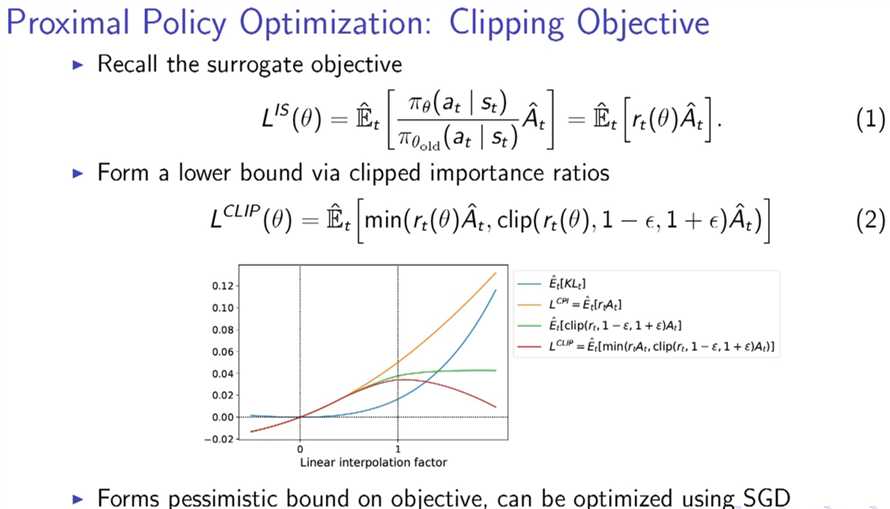
blue curve is the lower bounded one

conjugate gradient to solve the optimization problem.

Fisher information matrix, natural policy gradient


To write down an optimization problem, we can solve more robustly with more sample efficiency to update policy
But Lis Lpg is not constrained, so we use KL to ...

it‘s hard to choose beta







TRPO is much worse than A3C on imaging game, where PPO does better
see the slide: limitations of TRPO



Deep RL Bootcamp Lecture 5: Natural Policy Gradients, TRPO, PPO
原文:https://www.cnblogs.com/ecoflex/p/8976876.html